In the spring semester, our team members focus on reimplementing and analyzing state-of-the-art methods in multimodal 3D object detection, including AVOD, PointPillar, PointPainting and conduct experiments in nuScenes and KITTI dataset. For detailed explanation, please check out our video and slides.
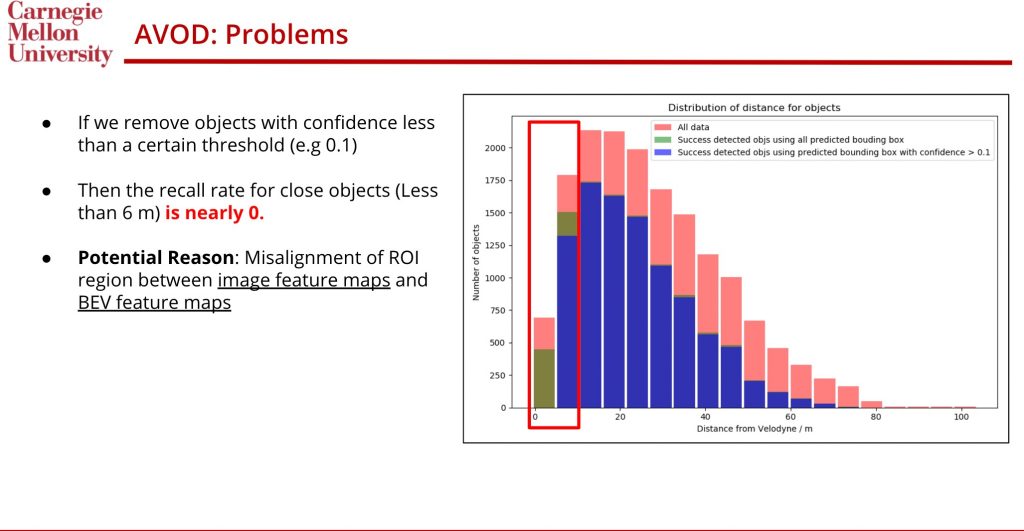
We start our experiment by first analyzing the AVOD, which is a common benchmark method that uses both image and LiDAR information. We realize that for super close objects (<10 meters), the AVOD performs surprisingly bad, and we argue that the main reason is the misalignment between frontal ROI Pooling and BEV ROI Pooling. Here is an illustrative figure:

We also conduct experiments when we have perfect semantic segmentation predictions in PointPainting(PointPainting relies heavily on 2D image segmentation). Our experiment shows that the performance of 3D object detection is highly correlated to 2D image segmentation. Here is the corresponding slides:

Given these findings, we decide to focus on the second finding and propose to let 2D model and 3D model benefits each other.