Previous work
Before we joined the project, previous members of our team tried to learn a policy[9] in the CARLA simulator using an on-policy RL algorithm, namely Proximal Policy Optimization(PPO)[4]. They used an encoding of semantically segmented bird eye view images as inputs. They used an auto-encoder to obtain the encodings. Their experiments showed that the even though the agent was able to navigate (go straight, take turns) successfully, it didn’t learn to stop before obstacles.
There are two possible sources of error. The first possibility is that the encoding did not detect the obstacle and the second one is that the RL algorithm did not learn a good policy. Thus, we decided to split the problem into two sub-parts which are described below.
1) Focus on RL : Train a policy using a handcrafted state space (no images) with enough information to solve the task. We name this agent as privileged agent.
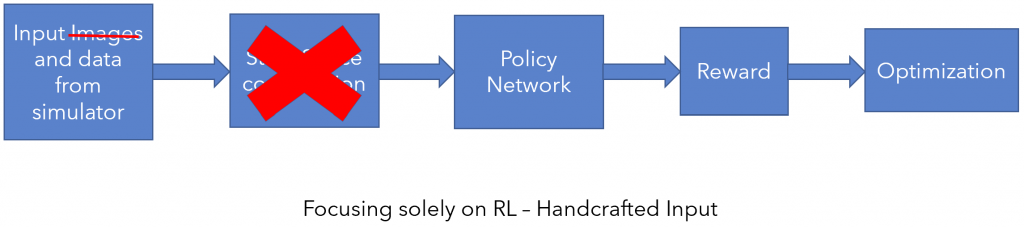
2) Focus on representation : Either find a suitable image representation by pretraining on an auxiliary task, or using pretrained networks available online, or by training a feature encoder using imitation learning.
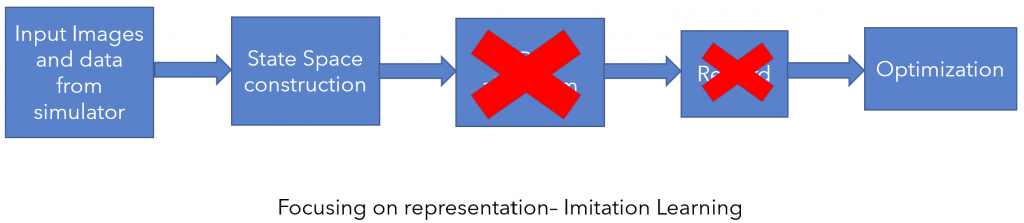
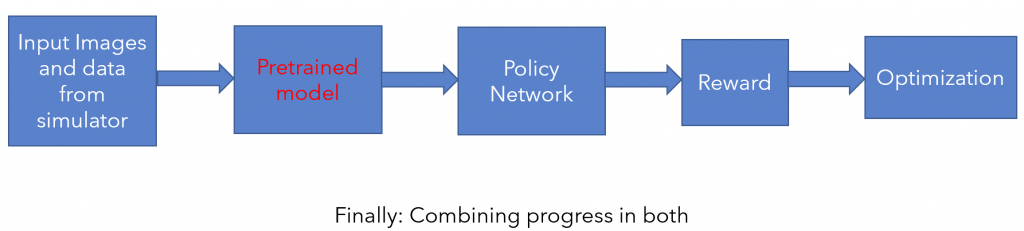
Finally, we wish to combine and finetune the above two parts to get a purely image based policy that performs just as well, if not better, than the original privileged expert.
Literature Survey
In order to tackle the first part of our problem, we spent the initial few weeks doing a broad literature survey and getting ourselves familiar with RL algorithms. Our initial presentation was on this literature survey and about the choices that we made for further experimentation. The slides for the initial presentation can be found at the link below.
Literature Survey Presentation
Formulation
Algorithm :
Since our final aim is to make use of previously collected driving logs, we decided to use an off-policy RL algorithm named Soft Actor Critic (SAC)[5] in all our experiments as the exploration is handled inherently using an intrinsic reward term measuring entropy of the policy. Also, another factor for choosing SAC is that there can be multiple ways to drive to successfully reach a destination (for ex: apply brakes at safer distance from obstacles vs apply sudden brakes closer to the obstacle) which resonates well with the motivation of SAC.
Outputs/Action space:
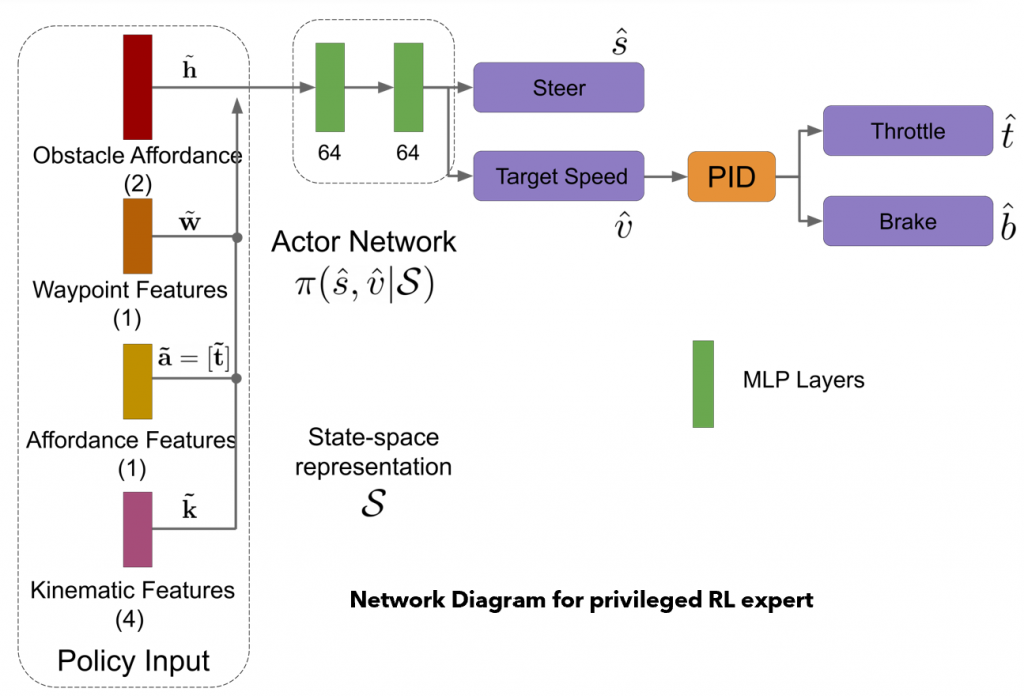
The SAC policy predicts speed and steer values within the range [-1,1]. The predicted values are scaled appropriately and passed to a PID controller which converts the speed to throttle and brake signals.
Rewards:
We used the following reward structure, which was fixed throughout our experiments. These rewards can be changed to reproduce desirable behaviors.
- Speed based reward : For each waypoint the agent visits, it gets a small reward, thus it is motivated to go as fast as possible.
- Deviation from trajectory reward : The agent gets negative reward for moving horizontally away from the trajectory.
- Collision reward : The agent gets a large negative reward upon collision. A separate speed based penalty, proportional to how fast the agent was moving at collision time, is also incurred.
Navigation scenarios
For our initial experiments, we use two scenarios:
- Navigation without dynamic actors
- Navigation with dynamic actors.
For all our experiments, we use Town 1 for training and Town 2 for testing.
The metric we use for evaluating a trained policy is the number or percentage of success videos out of 25 on training and testing towns.
Part 1 (Focus on RL – SAC) :
Input/ State space:
Our team chose a set of 8 features which are manually queried from CARLA simulator as inputs to SAC. The 8 features chosen are as follows.
- Mean Angle to the next 5 waypoints
- Agent’s current speed
- Agent’s current steer
- Distance to the nearest car in front of the agent
- Speed of the nearest car in front of the agent
- Distance from red light – Set to 1 if the traffic light is too far, or if it is yellow/green.
- Horizontal distance of the agent from the trajectory
- Distance to goal
Architecture
Results
- We found the first scenario, i.e. navigation without dynamic actors, to be relatively easy and it was solved with SAC.
- However, for the second scenario, we found that naive SAC doesn’t perform well.
- Upon further experimentation, we found that N-step performs well and for some values of N (=25,50), it even reaches the performance of PPO on training town.
Following are the number of success episodes of policy trained using SAC

Our findings are presented in the end semester presentation whose video is linked below. The slides for the presentation can be found here: Spring : End Sem Presentation
Part 2 (Focus on Vision):
Towards the end of spring semester, we also started experimenting to find a suitable image representation that could be helpful for learning the policy. A good feature encoding should learn to infer most of the things we are trying to capture in our 8-dim manual state space. Since the ego vehicle’s speed and steer is hard to infer from a single image, we provided them as manual input to the network. This assumption is practical because we usually know the speed and trajectory of our own vehicle. However, for future work, a stack of frames could be used to capture temporal information of other actors as well. Along with the image, speed and steer, we also feed the mean angle to the next 5 way points to guide the agent along the trajectory provided by the planner.
Input/ State space:
In summary, our new state space is
- Image encoding
- Mean angle to the next 5 waypoints
- Agent’s current speed
- Agent’s current steer
Using pretrained networks
We first attempted to use networks pretrained on the CARLA simulator to extract image features. For this purpose, we took the pretrained model from the agent trained in Learning by Cheating[2] as a feature extractor and used their Resnet[6] backbone.
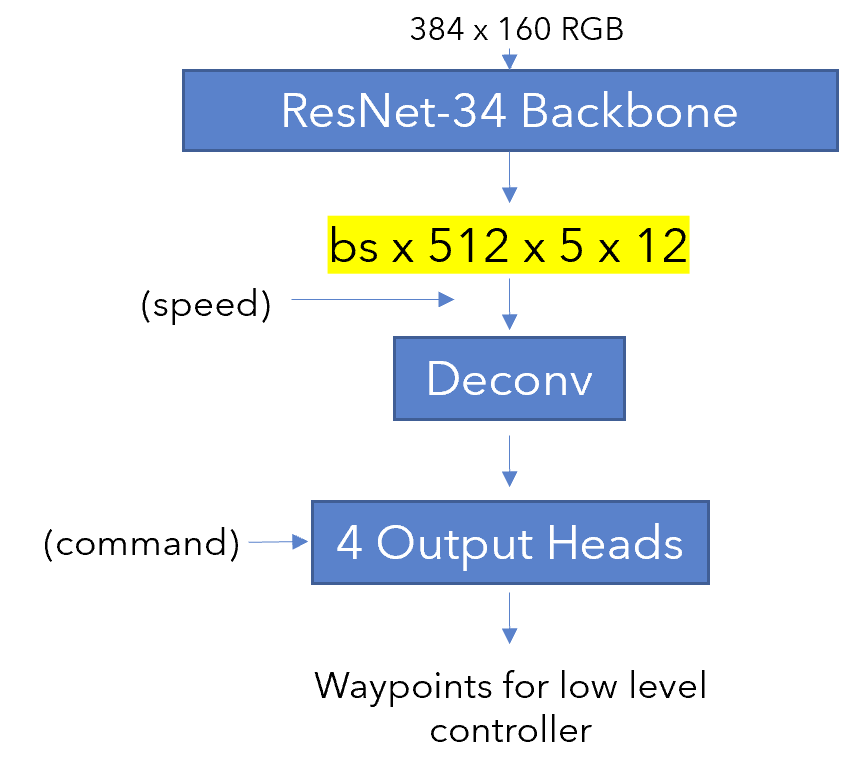
The feature encoding of the Resnet-34 backbone was used as a state space representation for RL. However, it was fairly large, at 30k dimensions. We tried to use a bottleneck architecture, as shown below, in the hopes of keeping the tunable parameters. However, in practice we never saw any agent succeed in more than 3 out of 25 episodes. In fact, it was also struggling to turn and could only drive straight.
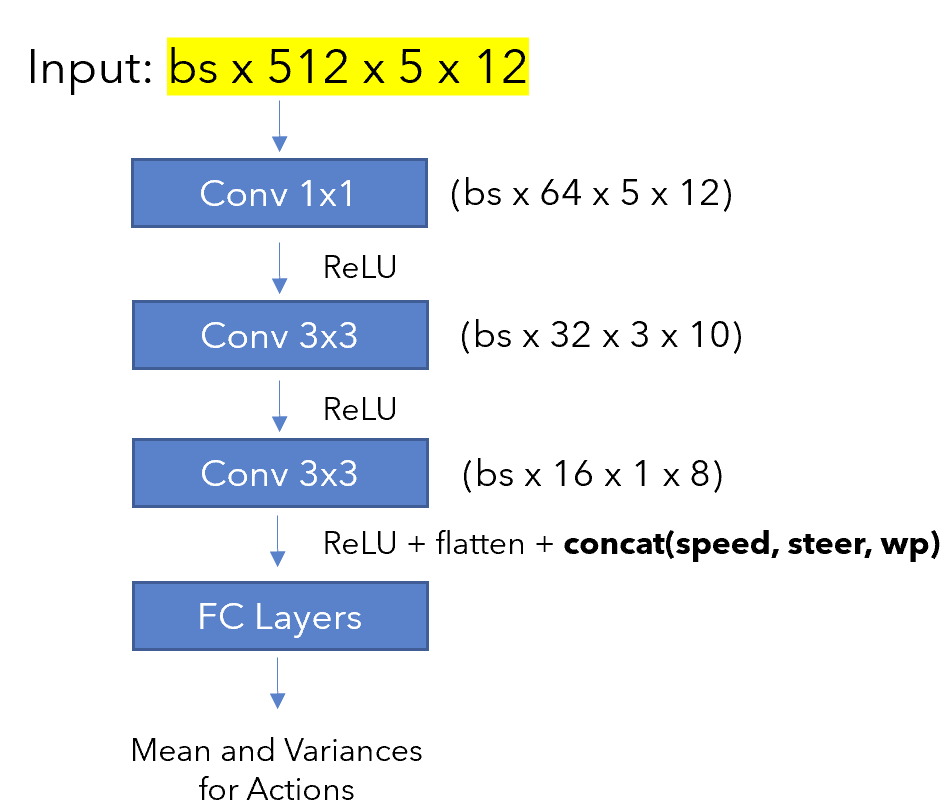
The fact that the agent failed to even turn despite being supplied with speed, steer and waypoints along with the state representation tells us that the input state dimensions might have been very large to train a the tunable model from scratch using RL. Also, we used an encoder network which was taken from a different task. Learning by Cheating predicts waypoints across four output nodes and so is not task specific for predicting speed and steer. However, the feature map should be general enough and usable in theory. We tested this out by visualizing 88 channels as shown below. The activations visibly change during traffic light changes and turns, which shows that the feature map does contain relevant information.
The final conclusions from these sets of experiments are as follows. We should prefer to train a task specific feature encoder rather than using an autoencoder. We should also try to keep the encoding, or resultant feature map, to be limited to a reasonably low dimension, for example 1000. However, we haven’t tried training our final method with a high dimensional state space and it is something that would be interesting as a future work.