Imitating the RL expert with DAgger
In the fall semester, we tried a different approach to train a visual network for representation learning. We started with an ImageNet initialized ResNet34, added a MLP with 2 layers on top of it and then imitated the actions produced by the privileged agent for the manual state corresponding to current image (environment observation). Here, the privileged agent could be trained used either soft actor-critic (SAC) and proximal policy optimization (PPO), both of which give 100% success episodes on train town. However, for fair evaluation purposes, we used privileged agent trained using PPO. We used the DAgger algorithm to do imitation learning, which is made much easier by the fact that our expert is a neural network. To improve the training stability, in addition to behavior cloning loss, we also introduced a auxiliary task of predicting obstacle and red light affordances. We noticed that the approach will work even without this auxiliary task but needs more careful hyper parameter tuning. We call the resulting agent a behavior cloned (BC) visual policy.
Architecture
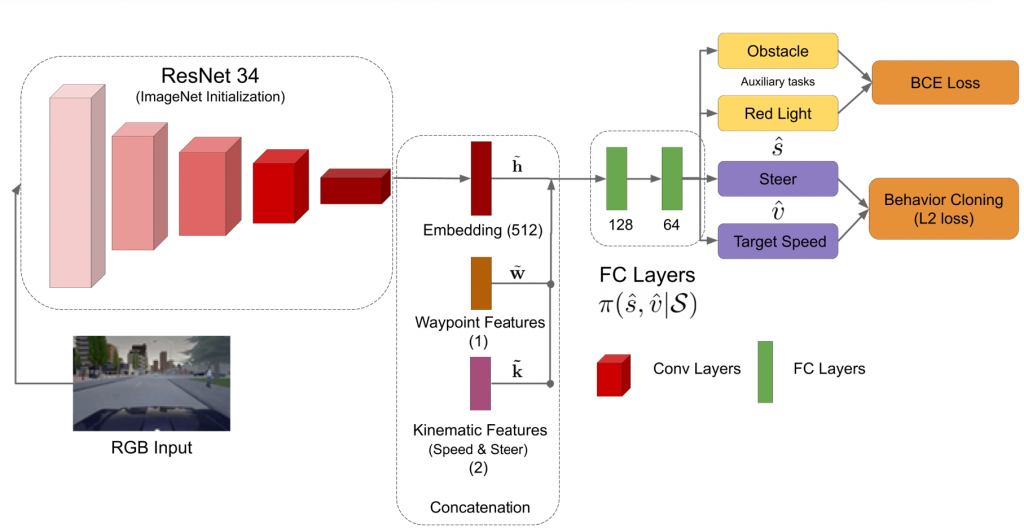
Fine tuning the BC visual policy
Two limitations of behavior cloning are that its performance is capped by the expert and that there might be cases where even our privileged agent can fail. So, we finetuned the BC visual policy using SAC. We kept the ResNet backbone fixed, removed the auxiliary task and fine tuned only the MLP layers. The architecture is shown below.
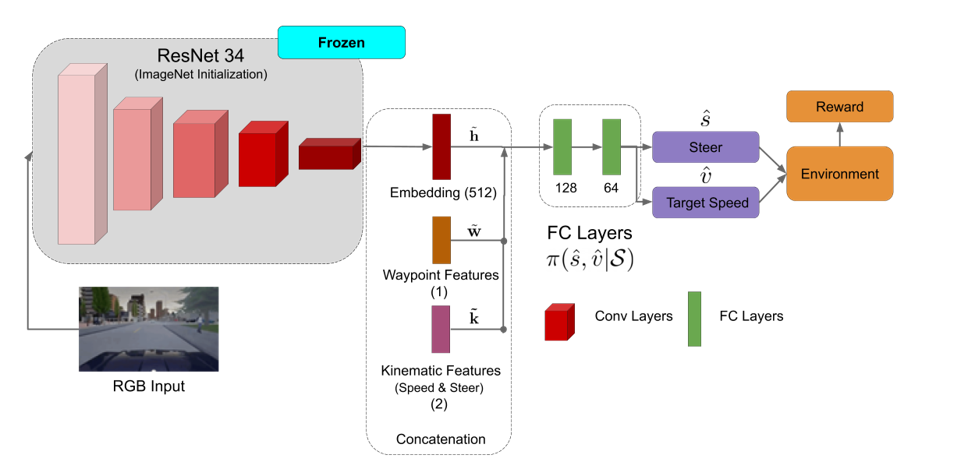
To fine tune using N-step SAC, we also need to train Q and V networks. In order to do this, we followed a similar, yet different, strategy to Batch constrained Q learning for the initial 100k time steps. The algorithm we used is given as follows. Please note that the “expert” below refers to the BC visual policy:

Results:
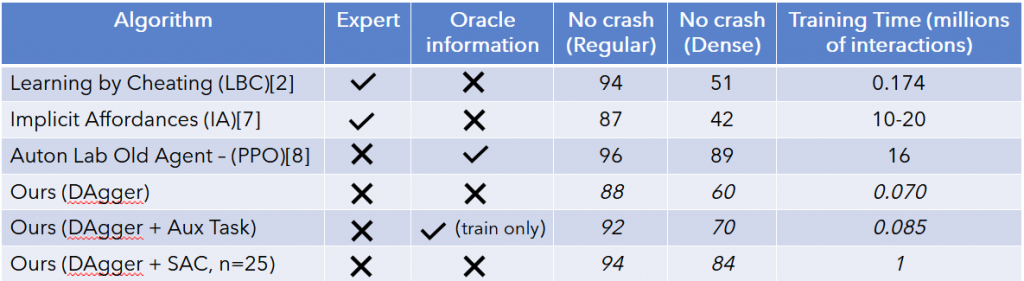
For all the experiments below, we shifted our evaluation setting to No-Crash benchmark. The first column specifies the method while the second and third columns state the usage of experts and oracle information by previous works. Ideally, we should have crosses in both these columns. The fourth and fifth columns denote the percentage of success episodes over several seeds on testing town (Town 2). We would like to note that the dense benchmark is significantly harder compared to regular.
We see that Auton lab’s privileged agent outperforms LBC and IA on both regular and dense benchmarks but it uses oracle information during testing. Our DAgger approach, i.e. the behavior cloned visual policy, almost matches the performance of previous works but doesn’t surpass them drastically.
However, upon finetuning with SAC our policy shows significant improvement over previous methods. It also takes significantly less time to train at only 1M timesteps which is extremely less for RL on image input. However, we do enjoy a robust privileged model train on an engineered state space. This goes to show that if a robust policy is trained on a small engineered state space invariant to visual variation, it can be easily transferred to any visual domain using imitation learning. Then it can be further finetuned using reward received in the real world, perhaps by supervision of safety drivers in the manner described in Learning to drive in a day [1].
Finally, the final SAC agent also performs better than the BC agent qualitatively. It’s driving is visibly smoother and it stops at a natural distance from obstacles rather than stopping too early like the BC or expert agent. Stopping too far from cars is an artifact of using a crude reward function on an engineered state space which SAC overcomes. The SAC agent also learns to stop or rush through yellow lights without violations which is very interesting behavior. For viewing the qualitative results, please visit the video demonstrations page.
Reference
[1] Dosovitskiy, Alexey, et al. “CARLA: An open urban driving simulator.” arXiv preprint arXiv:1711.03938 (2017).
[2] Chen, Dian, et al. “Learning by cheating.” Conference on Robot Learning. PMLR, 2020.
[3] Kendall, Alex, et al. “Learning to drive in a day.” 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019
[4] Schulman, John, et al. “Proximal policy optimization algorithms.” arXiv preprint arXiv:1707.06347 (2017).
[5] Haarnoja, Tuomas, et al. “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor.” arXiv preprint arXiv:1801.01290 (2018).
[6] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[7] Toromanoff, Marin, Emilie Wirbel, and Fabien Moutarde. “End-to-End Model-Free Reinforcement Learning for Urban Driving using Implicit Affordances.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[8] Master’s Thesis, Tech. Report, CMU-RI-TR-20-32, August, 2020, Tanmay Agarwal
[9] Agarwal, Tanmay, et al. “Learning to Drive using Waypoints.”