
This MSCV Capstone Project is sponsored by Amazon Lab126 and advised by Prof. Kaess.
Project Summary: Typical visual SLAM (Simultaneous Localization and Mapping) systems track features (points, lines) in the environment to derive the camera trajectory, however, these features are typically not semantically meaningful. In this project, we attempt to write our own software on top of existing open-source software libraries. The students shall attempt to investigate the use of semantic features that might coincide with objects or are derived from other forms of scene understanding. Understanding features will allow trajectory estimation to focus on structural features that can be assumed to be static (doorways, sink, stove, etc.) while tracking others that might move over time (doors, chairs). One challenge is that the approach should also work in environments with objects that have not previously been observed or learned. We aim to build on publicly available and hope to combine existing methods or come up with new map representations while gaining real-world experience in SLAM.
Dataset: The dataset we are using follows the requirement from our sponsor. All the sequences are recorded in indoor environment with a monocular RGB-D sensor. The camera used is calibrated and the ground truth camera trajectory is recorded for algorithm evaluation.

Motivation: We believe it is a good way to identify static and dynamic structural features if we could identify static and dynamic objects since feature points on the same object share the same motion. For this problem, our intuition is that the camera pose estimated from static objects tend to be the same. If the number of static objects exceed that of dynamic objects (which is highly possible), then choose the majority of estimated camera pose could be a good solution.
Approach: We proposed to use a combination of deep learning and vision geometry approach to address this problem. So we will introduce our final method in two parts: the Deep Learning part and Geometry part.
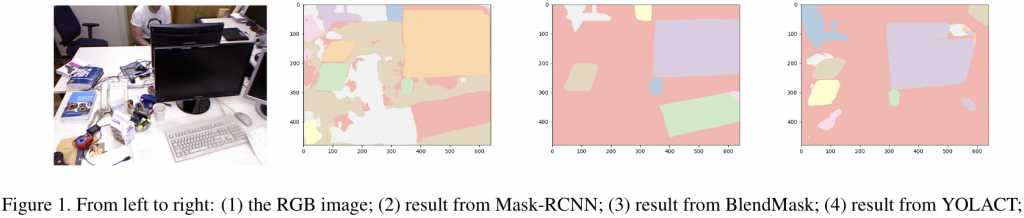
We use Mask-RCNN, BlendMask and YOLACT to perform instance segmentation. The latter two methods are state-of-the-art real-time instance segmentation methods and Mask-RCNN does not run in real-time. From the results we can see that Mask-RCNN recognized more objects in the scene and delineates the boundary more precisely. Even though it has a longer runtime, we choose to use it in the experiment part in order to achieve best tracking accuracy.
Our geometry method could be divided into several steps;
- Detect ORB feature point in two images;
- Convert point matches to objects matches using voting method;
- Perform pose estimation on feature points from each object;
- Pick the majority pose estimation as our final result;

This geometry method follows our intuition and did improve the tracking result. After our analysis we discovered that the Deep Learning is the key contributor here and the Geometry method did not enhance the system performance greatly. This due to that some small and faraway objects have too few feature points, and this affects the accuracy of the pose estimation algorithm. So later we proposed an optimized version of the Geometry method:
- Detect ORB feature point in two images;
- Convert point matches to objects matches using voting method;
- Perform pose estimation on feature points from each object;
- For each pose estimation, find out how many inlier feature points agree with it;
- Use all inlier points to perform pose estimation again;
- The pose estimated from maximum number of inlier points is final result;
Since we have the depth map and estimated rotation & translation, we could project the feature point from the second image to the first image and see if there is a match. That’s how we decide whether a point is an inlier: reproduction error.
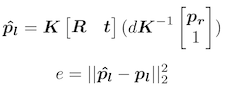
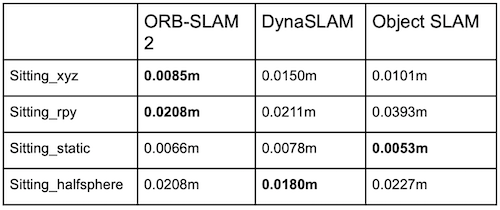
Result: The following tables demonstrate our result in high/low dynamic scenes. We did more ablation study and you could find it in our final representation slides.
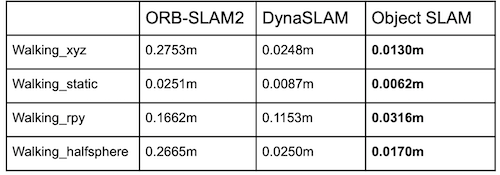
Our method did a really great job in high dynamic scenes. It outperforms the original ORB-SLAM2 significantly. Also, it beats the result from DynaSLAM, which is the state-of-the-art method in visual SLAM under dynamic scenes. This has demonstrated the power of deep learning and verifies our intuition that visual SLAM is suffered from dynamic objects in the scene.
Our method achieved similar result with all baseline methods. Since the trajectory error for the baseline methods in low dynamic scenes is low enough, our performance meets the expectation.