
This project aims at understanding kitchen in 3D to enable robot learning by watching video demonstrations.
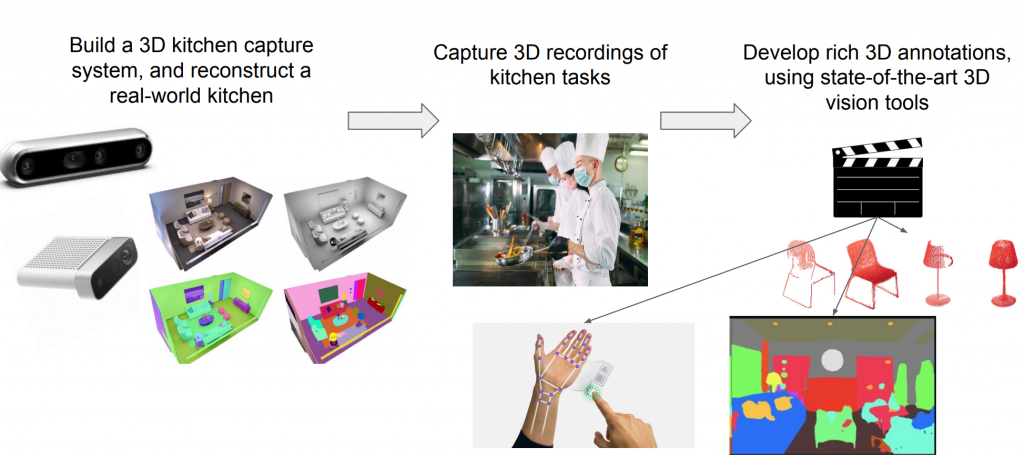
The first part of the project, the data collection part, includes the following components: building a 3D kitchen capture system, reconstruct a real-world kitchen, capture 3D recordings of kitchen tasks, and developing rich 3D annotations. Here is an illustration from the project pitch:
In the spring semester, we have developed a synchronized multi-camera capture system. The extrinsic pose of each camera is estimated by detecting AprilTags. Here is our miniature camera setup, which we are going to move to the actual kitchen:

We can then capture a 3D video jointly with the cameras from different views:
We also use off-the-shelf models including ViTPose for human pose estimation:
In the next semester, we will continue our project by introducing semantic understanding of 3D kitchen scenes and build pipeline of visual imitation learning.








