
Human-level Annotations
We include 2D and 3D pose estimation as part of our data collection pipeline. Human-pose can be useful to obtain a trajectory and interaction information which is a good prior for imitation frameworks.
We also include hand-pose estimation and segmentation.

Scene-level Annotations
Our data contains posed RGB-D images that can provide us with point clouds. Therefore, for scene-level annotations, we have focused on collecting 3D segmentation masks for point clouds.
Leveraging 2D Foundation Models For 3D Scene Segmentation
Modern 2D segmentation foundation models, enabled by transfer learning and large-scale datasets generate high-quality object masks. 3D segmentation models are not there yet. Given the fact that a majority of 3D data are collected by sensors that produce point clouds from RGB-D images, we aim to leverage the 2D foundation models that take RGB images as input to yield segmentation masks and develop an algorithm that utilizes those generated masks along with the depth information and scene geometry to facilitate 3D scene segmentation.
Finding Correspondences
Each view has its corresponding color images and depth images, from which we can get a point cloud and 2D-to-3D correspondences. Using camera matrix of the next view, we can find 2D-to-2D correspondences between the current view and the next view.
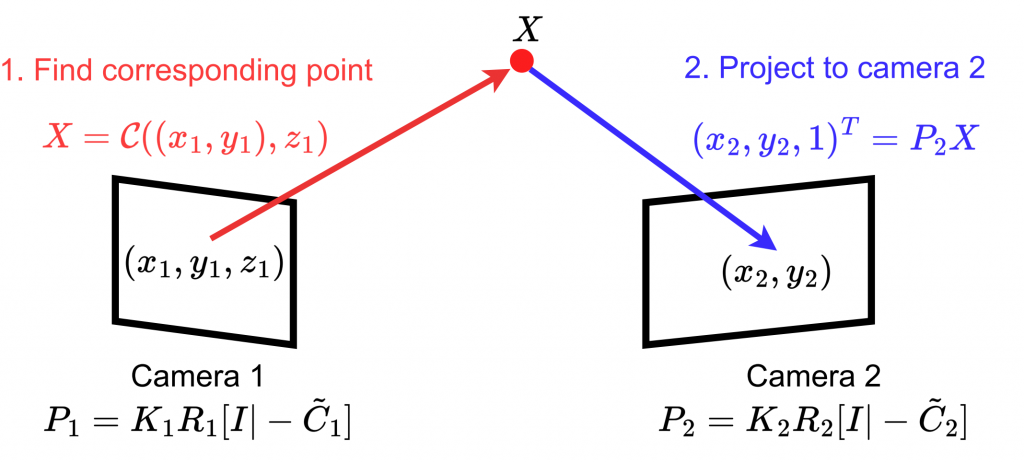
Graph-Based Merging
The unsupervised foundation models do not provide semantic IDs for the segmentation generated. Moreover, due to occlusion, objects might be separated into two masks.
To determine the merging assignments of masks across views, we formulate a graph as shown in the diagram below. Based on 2D-to-2D correspondences, we decide the edges between two nodes. After updating all the masks in all the views, we eventually reach to a final graph and all the connected nodes in the final graph are assigned same ID.
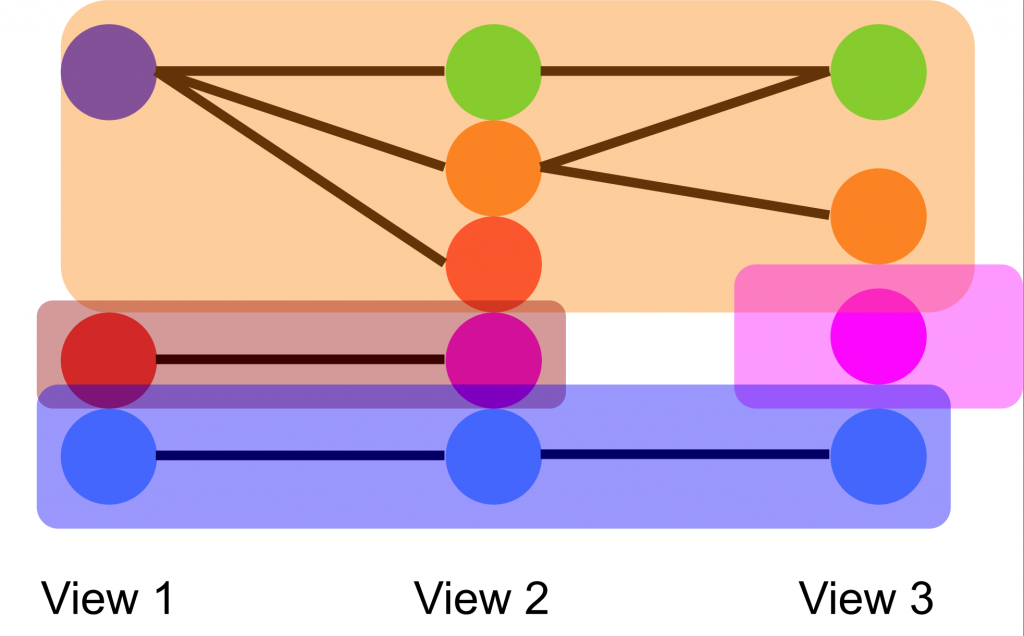
Results
Before merging:


After merging:


Output merged point cloud:
