Overview
We reviewed relevant literature and decided to implement tracking-by-detection method in top-down view in order to efficiently aggregate multiple views. We trained two multi-view detectors (MVDet, MVDeTr) on MMPTrack dataset, and implemented SORT as our baseline tracking algorithm. Detected and tracked bounding boxes in top-down view are reprojected onto camera planes for final output.
Presentation slides and poster are publicly available.
Literature Review
Paper 1: Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
Previously mentioned tracking-by-detection framework has two main challenges: one is unreliable detection, and another one is occlusion which results in ambiguities in data association. Then the challenge is to associating unreliable detection results with existing tracks in real-time, or in other words only using current and past frames.
Authors propose three novel ideas to tackle this challenge. First, they suggest that detection and tracks can complement each other in different scenarios. Detection results of high confidence can prevent tracking drifts while prediction of tracks can handle noisy detection by occlusion. So, the authors propose to collect candidates from outputs of both detection and tracking while default framework used to collect only from detection results.
In order to optimally select from a considerable amount of candidates in real-time, the authors present a novel scoring function that fuses an object classifier and a tracklet confidence.
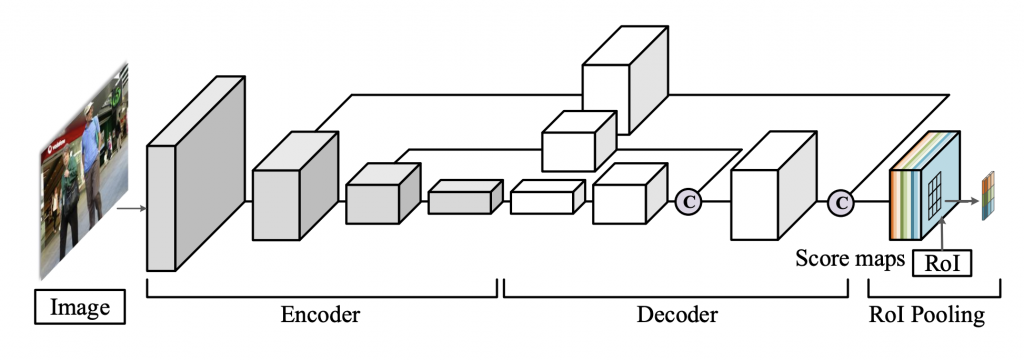
Given an image frame, score maps of the entire image are predicted using a fully convolutional neural network with an encoder-decoder architecture. At the end there is a position-sensitive RoI pooling layer to explicitly encode spatial information into the score maps.
This region-based fully convolutional neural network shares most computations on the entire image, which makes it much more efficient compared to classification on image patches (cropped from heavily overlapped candidate regions).
For computing tracklet confidence, we estimate new location of existing track using Kalman filter. These predictions are adopted to handle detection failures caused by occlusion in crowded scenes and various visual properties of objects. Hence, tracklet confidence is designed to measure the accuracy of the filter using temporal information.
Lastly, the authors adopt deeply learned appearance representation to improve the identification ability of the tracker. A deep neural network with convolutional backbone from GoogLeNet followed by part-aligned fully connected layers extracts feature vectors from RGB images.
Tracks are hierarchically associated with different candidates of different features by first using appearance representation, and then based on IOUs, and finally new tracks are initialized for remaining detection results. This enables to avoid tracking other unwanted objects and backgrounds. For the hierarchical data association, we only need to extract ReID features for candidates from detections once per frame.
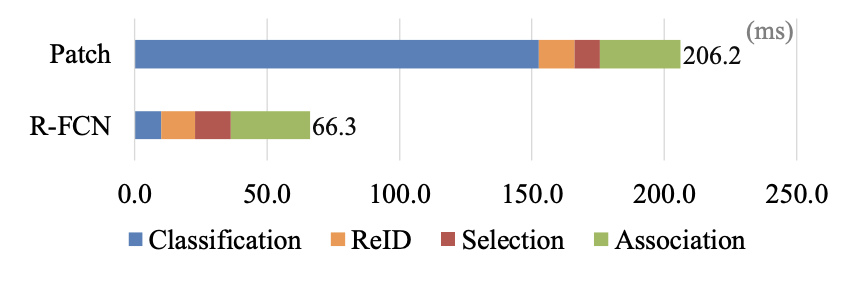
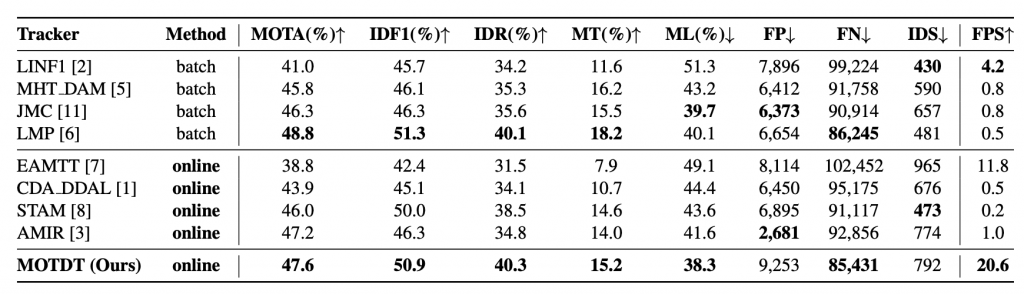
Proposed method is much more time efficient by sharing computations on the entire image. Also, when evaluated on the same MOT16 dataset, proposed method achieves state-of-the-arts performance while being 5-20 times faster than most existing methods.
Paper 2: Multi-view People Tracking via Hierarchical Trajectory Composition
Different cues, like appearance and location, have been studied for cross-camera data association at that time (2016). However, the author notices that existing approaches usually rely on the effectiveness of particular cues, which is an over-strong assumption. As shown in the case below, the validity of different cues varies at different time and places.

The proposed method learns an optimal strategy for utilizing multiple cues. Specifically, it’s a hierarchical composition model with 3 composition criteria: appearance coherence, geometry proximity, and motion consistency. In the mode, graph nodes are tracklets, which refer to a sequence of states (appearance feature, location, timestamp, visibility). The composition of nodes will grow tracklets and finally form a complete trajectory, and the criterion will measure likelihood of such composition.
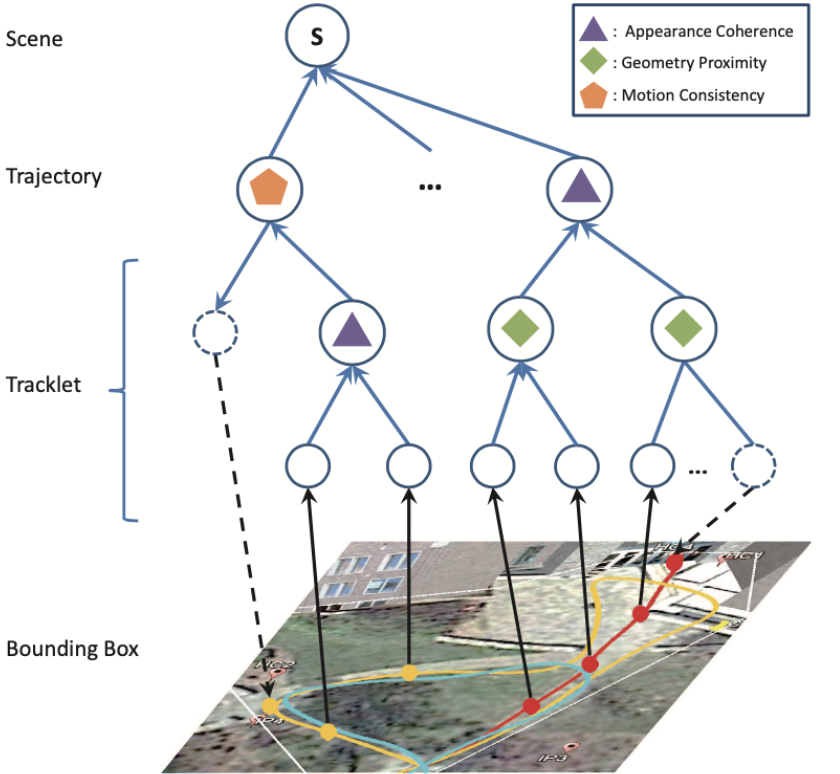
At inference time, the model will do an iterative greedy construction which reduces computational cost: First, enumerate to find two tracklets with max probability to be merged into a new one. Then re-estimate states for the new node. This process will repeat until max composition probability goes under a threshold, and each subtree connected to the root should be an object trajectory.
Paper 3: Multi-view Detection with Feature Perspective Transformation
What Paper 1 and Paper 2 have in common is that they are based on object detection at each camera view and seek to aggregate information across cameras later. The downside of this kind of method is the detection accuracy will suffer from severe occlusion. Recent methods like Paper 3 are based on a different idea. The authors propose an end-to-end model for direct multi-view detection and produce results as an occupancy map in the top-down view.
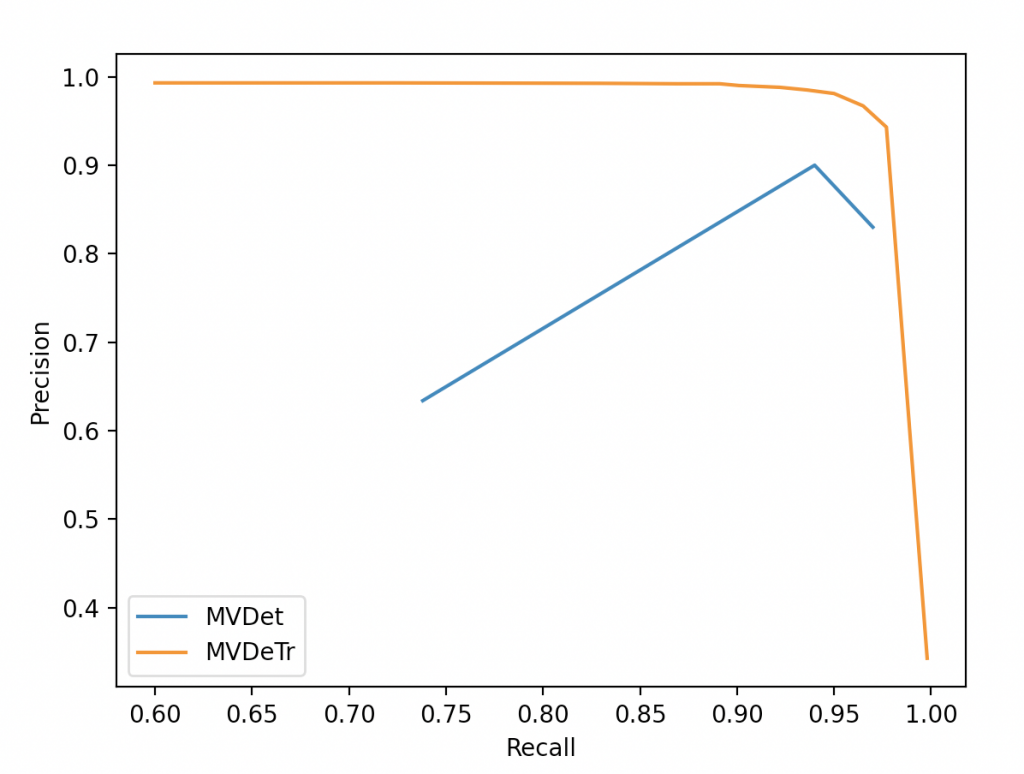
This kind of methods inspire us to build a tracker based on a multi-view detector. So a detailed description of a similar model can be found in our method page. This early cross-camera association strategy gives us a solid detection result (~97% recall and ~99% precision) on the MMPTRACK dataset.
Baseline Results
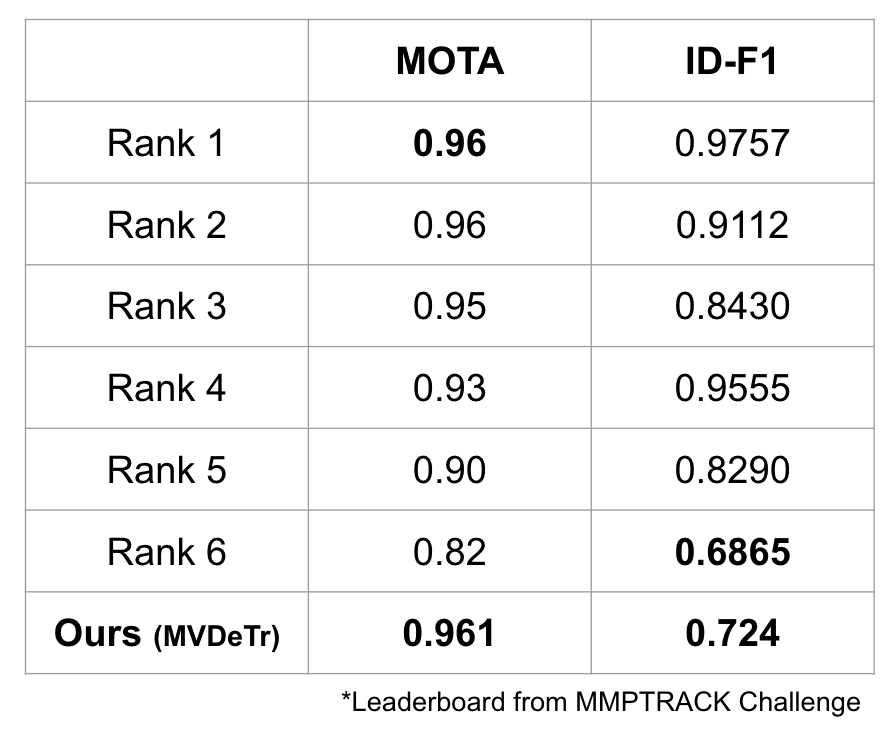
We trained multi-view detector (MVDet, MVDeTr) on MMPTrack dataset for 10 epochs on a single NVIDIA GeForce GTX 1070. We used SORT algorithms as our baseline tracking algorithm. Tracked bounding boxes are projected from world grid to each camera views by setting a fixed z coordinate of 1.6m which translates to bounding box height.