
Overview
Unlike most previous works, we associate information across cameras at the detection stage to get an accurate top-down view detection results. Next, we track and project points back to each camera view. A single-view detector will be used to further refine the bounding boxes. We also extracts appearance feature for more robust association.

Multi-View Detection
Based on recent research in BEV perception or 3D detection [1] [2], we build the following architecture. The model runs a modified ResNet backbone on each views and then projects the extracted features into the top-down view using camera calibration data. Concatenating these projected features aggregates information across camera views. For the spatial aggregation module, there are two options: large-kernel convolution and deformable transformer. The latter option allows a larger receptive field and is proved to perform better in our case.
A single view detection head is also trained and its bounding box regression loss is used as an auxiliary loss term of feature extractor.
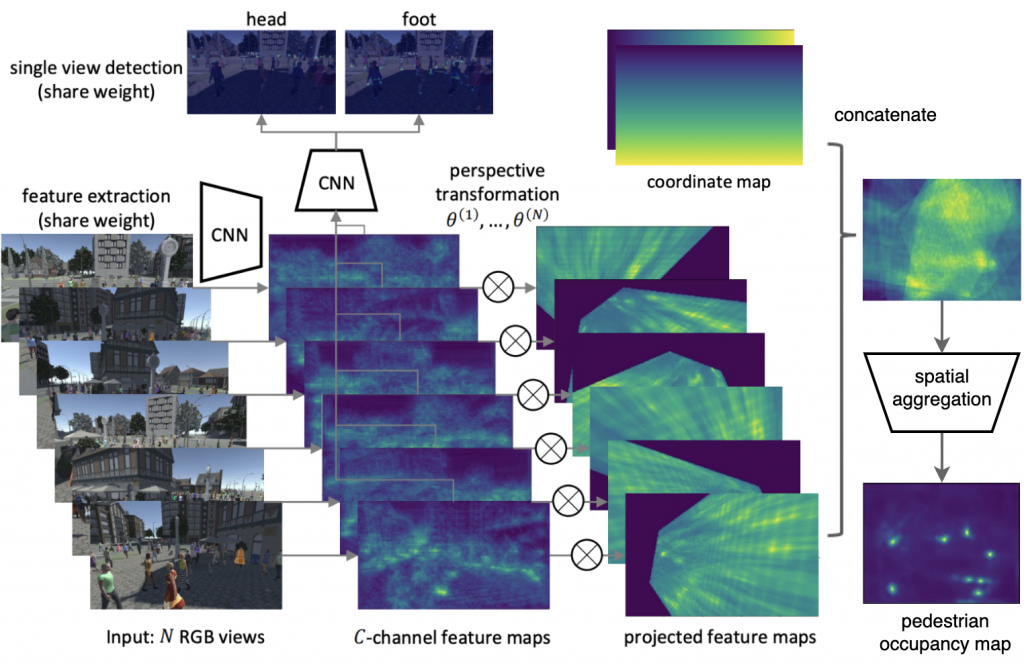
Projection and Refinement
We assume a fixed human body size which allows us to project 3D detection results back to camera views. The projected bounding boxes can have an inaccurate shape but can be refined by matching them with results from normal single-view detectors. Another benefit of this refinement is that we can identify and remove false positives when some boxes are not matched in any of the views.
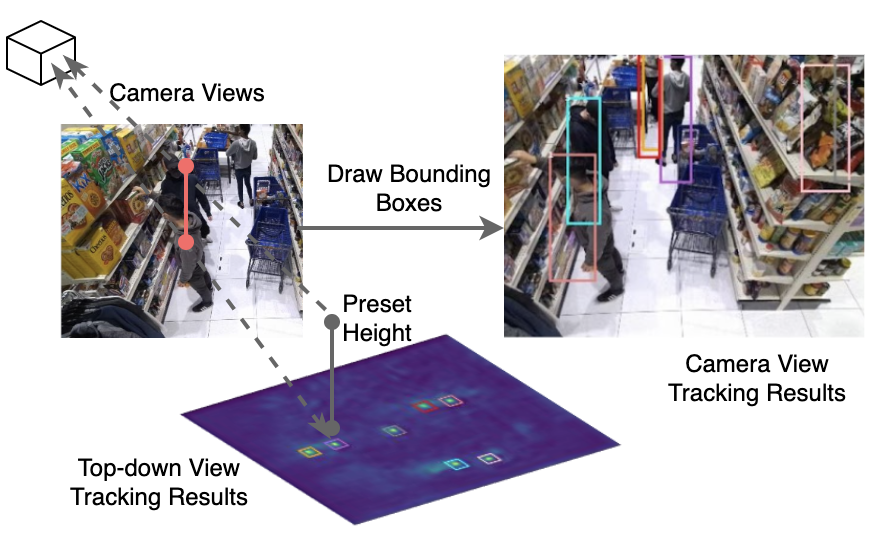
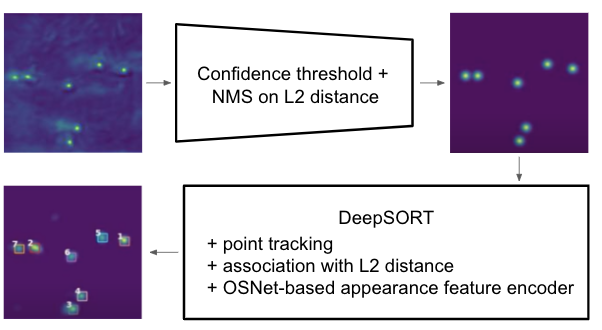
Tracking
We start with SORT [3] with an adjustment of its Kalman filter to track points in the top-down view, and later upgrade to a DeepSORT-like [5] tracking algorithm. Using refined bounding boxes, we can incorporate appearance feature at the association stage which allows “remembering” a target even if we lose track of him/her for a short period. We explore minimum cosine distance and averaging as two ways of aggregating appearance feature in the multi-view setting.
More specifically, we filter out features from occluded targets (invisible to single-view detector) and use, for example, average across views to represent its multi-view appearance. Finally, the min cosine distance between feature vector from new detections with those from tracking history is used as the appearance distance in matching.
Experiment
We train and evaluate our model on MMPTRACK dataset [4], which is a large-scale video dataset for multi-camera multi-object tracking. The dataset has ~5 hour videos for training and 1.5 hour videos for validation. Annotations include per-frame bounding boxes, corresponding person IDs and camera calibration data. The dataset poses challenges like cluttered and crowded environments, varying human poses and appearances to our tracking system.
We mostly focus on the retail environment and fine-tuned the pre-trained MVDeTr dataset for 10 epochs sampling 1 image every 5 images (for nearby frames in videos look alike). As images from all cameras need to be processed, we reduce the size of images by a factor of 4 to reduce the memory overhead. The world coordinate is voxelized with a size of 20mm × 20mm × 20mm and the ground plane is further reduced by a factor of 2. For the single view detector, we fine-tune YOLOv8-small for 20 epochs predicting Person class. Finally, an off-the-shelf Market1501 pre-trained OSNet is used to extract appearance features.
For quantitative evaluation, we mainly uses MOTA and IDF1 scores. We set up matching threshold as IoU>0.5 for camera view and pixel distance <25 in top-down view, following rules used in the MMPTRACK challenge. For updated results, please visit our 2023 Fall page.
Reference
[1] Hou, Yunzhong, Liang Zheng, and Stephen Gould. “Multiview detection with feature perspective transformation.” Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16. Springer International Publishing, 2020.
[2] Hou, Yunzhong, and Liang Zheng. “Multiview detection with shadow transformer (and view-coherent data augmentation).” Proceedings of the 29th ACM International Conference on Multimedia. 2021.
[3] Bewley, Alex, et al. “Simple online and realtime tracking.” 2016 IEEE international conference on image processing (ICIP). IEEE, 2016.
[4] Han, Xiaotian, et al. “Mmptrack: Large-scale densely annotated multi-camera multiple people tracking benchmark.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.
[5] Wojke, Nicolai, Alex Bewley, and Dietrich Paulus. “Simple online and realtime tracking with a deep association metric.” 2017 IEEE international conference on image processing (ICIP). IEEE, 2017.