
Overview
We identified a few problems with our baseline tracking approach (SORT): low accuracy of projected bounding boxes and high ID switches during association. We focused on tackling these by refining the projected bounding boxes using single-view detector, and reducing ID switches by adding appearance descriptor as the association metrics (DeepSORT).
Presentation slides and poster are publicly available.
Bounding Box Refinement with YOLOv8
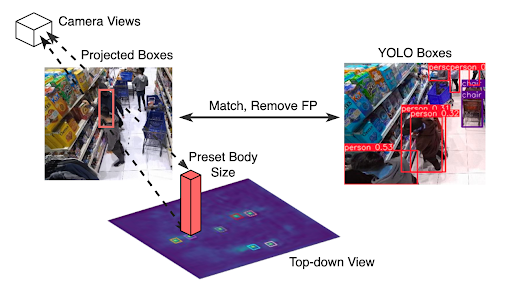
Previously, we were utilizing projection of detection on top-down occupancy map onto each camera view as the final projected bounding boxes to be visualized. This, however, resulted in inaccurate bounding boxes when projected, as we were arbitrarily defining a fixed 3D box on the top-down view map to be projected (see Figure 1). In order to adjust the projected bounding boxes to better encapsulate humans in each camera views, we added a single-view detector to run on each of camera views. In other words, we use fine-tuned YOLOv8 detector to detect humans in each camera views, match with the projected bounding box based on IoU, and remove false positives, if there is any. As shown in Figure 2, those refined by YOLOv8 more tightly fit the humans in the scene.

Appearance Feature Encoding for Tracking
We added deep appearance descriptor in order to reduce frequent ID switches during tracking. Motivation for this was that our baseline uses SORT tracking algorithm, which estimates the position of the target in the next frame using Gaussian distribution and constant velocity model. Here, the distance metric is simply the spatial distance and covariances. To complement the missing information, after we detect targets in top-down view, we project the point back to each camera views, encode the target bounding boxes and use the deep appearance feature vector as one of the association metrics. In essence, we are combining both motion and appearance descriptor to better track targets with higher consistency in identification.
One important point in using DeepSORT in the multi-view setting is that we need to aggregate these feature vectors across multiple camera views. Given 6 camera views, the encoder will generate 6 feature vectors. Here, in order to prevent including an encoding of occluded image, we reuse YOLOv8 single-view detector to filter out the projected bounding boxes with small IoU overlap with YOLO results. Then, we take a mean of encoded features across the camera views, which aims to tackle the occlusion and smoothen the feature vector.
We also make modifications to the Kalman filter to track the state of points in top-down view instead of bounding boxes. The IoU cost is also replaced with Euclidean distance correspondingly.

Updated Results on MMPTRACK
