
In this page, we briefly introduce our work in Spring 2023.
Title
TPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Links
[Paper] [Code] [Slides] [Videos]
Abstract
Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability.
Contributions
- Triangular Probability Similarity (TPS) for minimizing artifacts and distortions.
- Semantic Noise Contrastive Estimation (SeNCE) for optimizing the amounts of generated rain.
- Realistic rain generation benefits deraining and object detection in real rainy conditions.
Future Works
- Extremely Heavy Rain
- Strong Light Sources
- Diffusion Models
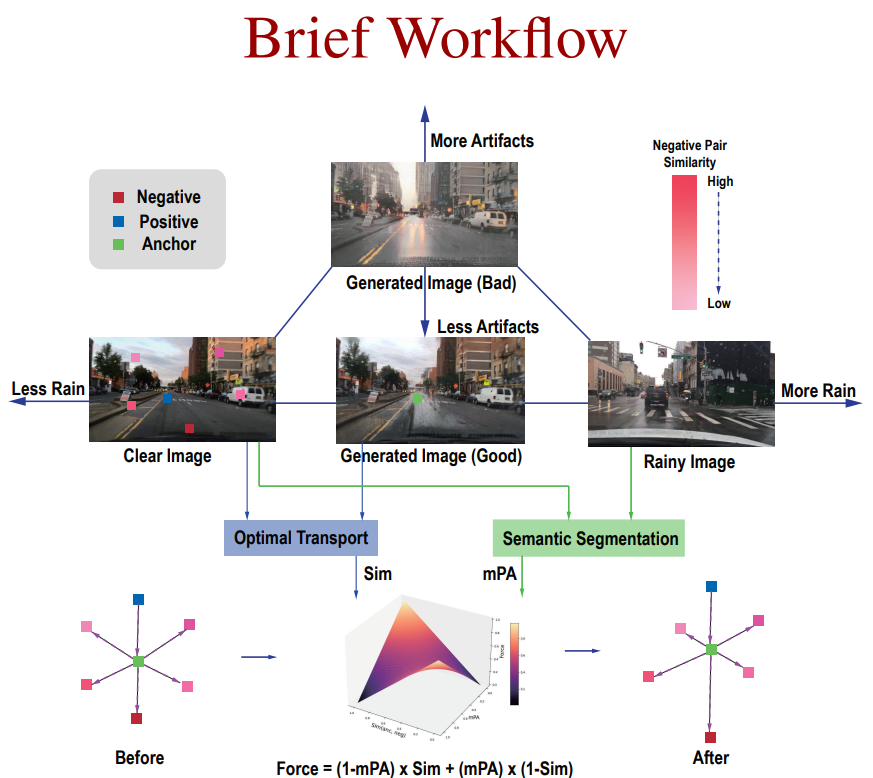
Brief Workflow
TPS aligns the generated rainy image with the clear and rainy image in the discriminator
manifold to suppress artifacts and distortions, while SeNCE adjusts the pushing force of the negative patches based on their feature similarities with the anchor patch and refines that force with the semantic similarity between clear and rainy
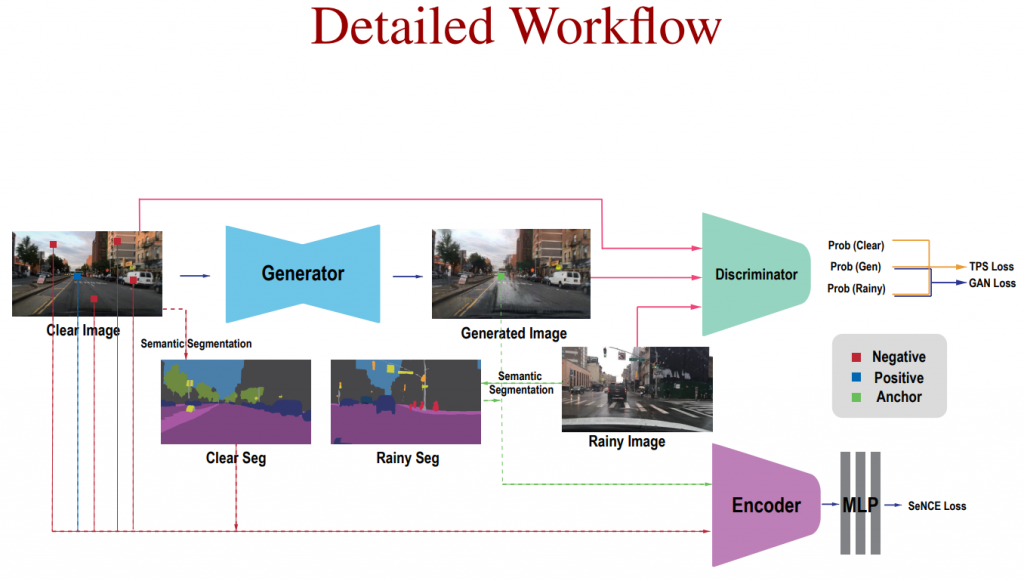
Detailed Workflow
TPSeNCE uses a generator to translate clear images to rainy ones, a discriminator with TPS and GAN losses, and an encoder that embeds patches from both clear and generated images. MLPs process these patches contrastively to output SeNCE loss, guided by semantic segmentation maps.
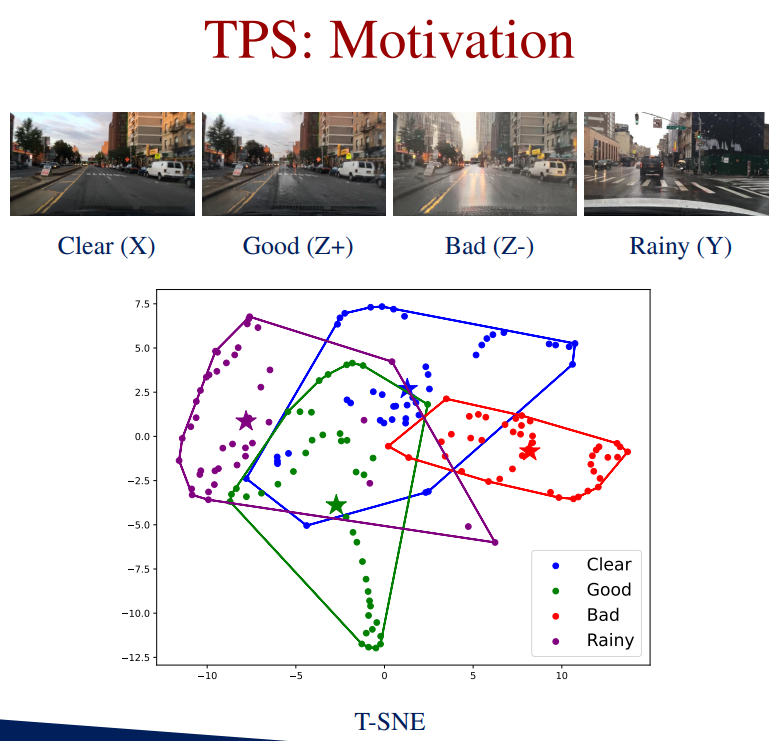
TPS: Motivation
T-SNE Visualization of the output matrices from the discriminator. We notice that ‘Good’ generated images has more feature overlap with clear and (real) rainy images. Designing a loss that maximize feature overlap between D(Z) and D(X) and D(Y) would minimize the space for artifacts and distortions, and thereby improve the quality of the generated image.
TPS: Formulas
Based on the triangle inequality theorem, the TPS loss aims to reduce the triangle to a line segment, thereby maximizing the feature overlaps between X, Y, and Z.

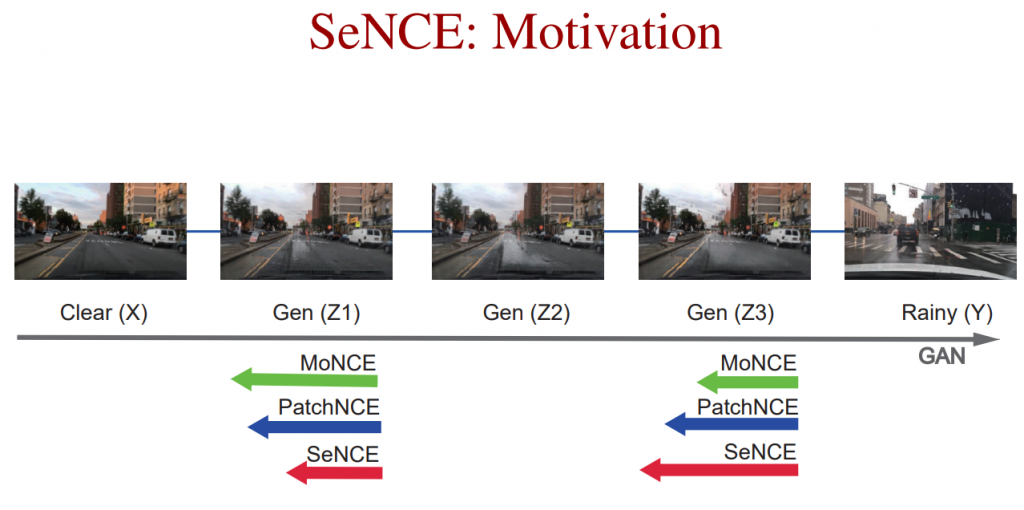
SeNCE: Motivations
SeNCE outperforms PatchNCE and MoNCE in optimizing the amount of rain to produce realistic rainy images. The length of the arrow here represents the magnitude of the NCE losses. Suppose Z2 represent optimal amount of rain. For insufficient rain (Z1), SeNCE magnitude is small => GAN loss will defeat SeNCE loss, bringing image from Z1 to Z2. For excessive rain (Z3), SeNCE magnitude is large => SeNCE loss will defeat GAN loss, bringing image from Z3 to Z2.
SeNCE: Formulas

Quantitative Comparison: Clear2Rainy (Rain Generation)
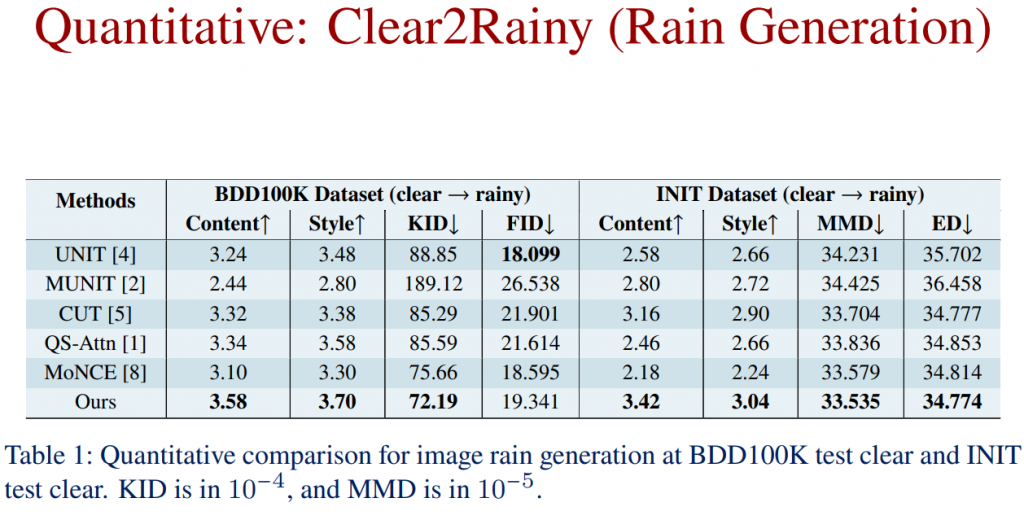
Quantitative Comparison: Rainy2Clear (Deraining)
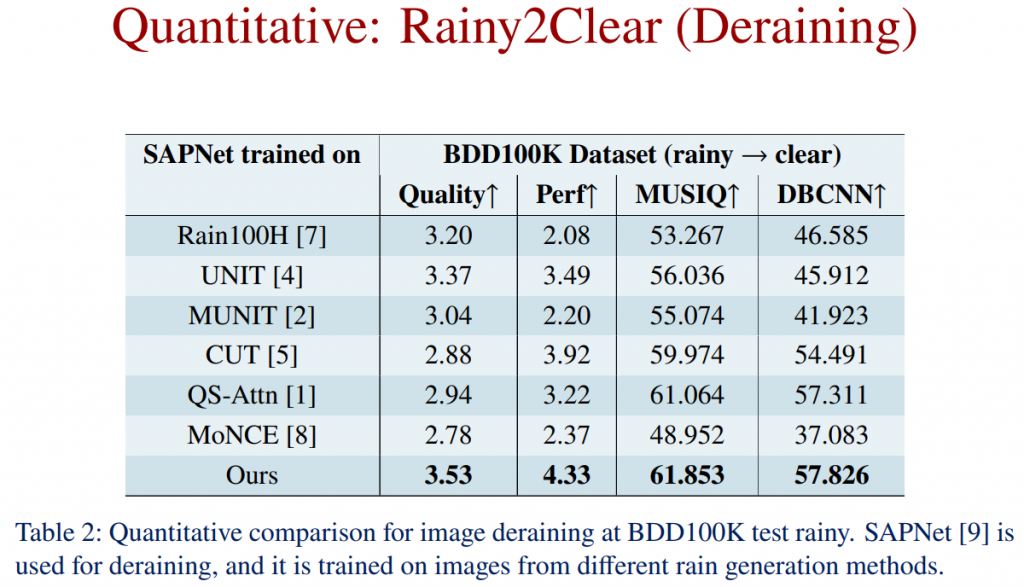
Quantitative Comparison: Object Detection in Rain
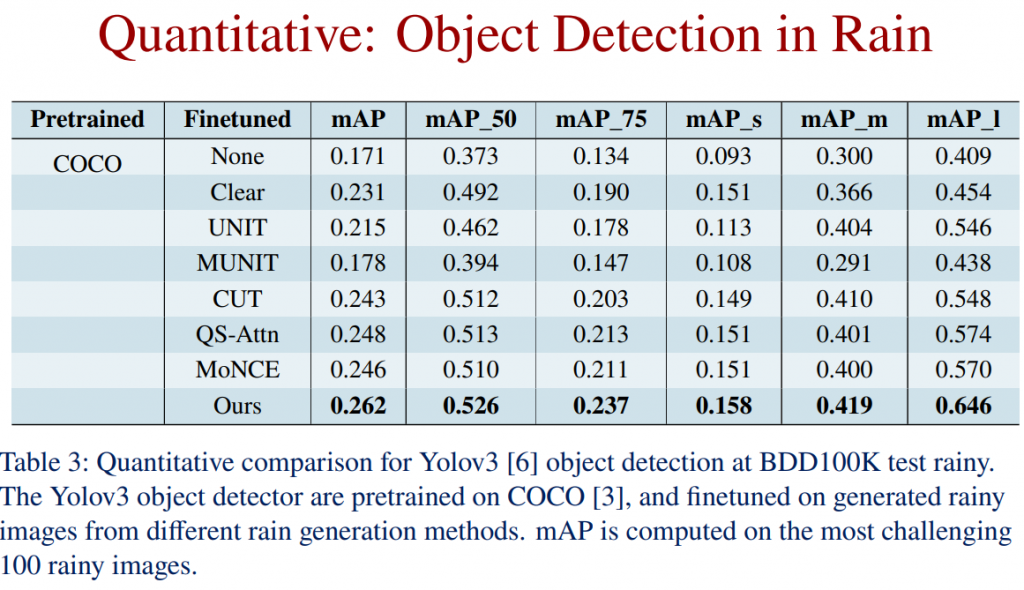
Qualitative Comparison: Clear2Rainy (Rain Generation)

Qualitative Comparison: Rainy2Clear (Deraining)

Qualitative Comparison: Object Detection in Rain
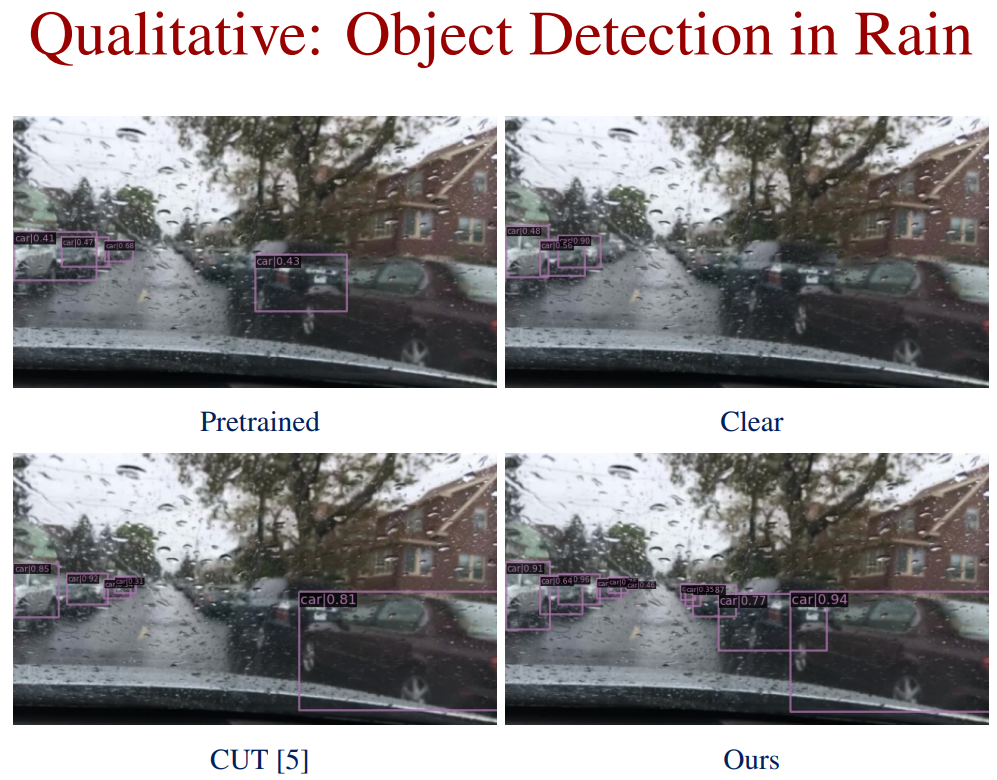
Qualitative Comparison: Day2Night

Qualitative Comparison: Clear2Snowy

References
[1] Hu, Xueqi, et al. “Qs-attn: Query-selected attention for contrastive learning in i2i translation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[2] Huang, Xun, et al. “Multimodal unsupervised image-to-image translation.” Proceedings of the European conference on computer vision (ECCV). 2018.
[3] Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer International Publishing, 2014.
[4] Liu, Ming-Yu, Thomas Breuel, and Jan Kautz. “Unsupervised image-to-image translation networks.” Advances in neural information processing systems 30 (2017).
[5] Park, Taesung, et al. “Contrastive learning for unpaired image-to-image translation.” Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16. Springer International Publishing, 2020.
[6] Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018).
[7] Yang, Wenhan, et al. “Deep joint rain detection and removal from a single image.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[8] Zhan, Fangneng, et al. “Modulated contrast for versatile image synthesis.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[9] Zheng, Shen, et al. “SAPNet: Segmentation-aware progressive network for perceptual contrastive deraining.” Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2022.