Abstract
In this research project, we aim to tackle the goal of semantic navigation with 3D and 2D scene information. As most prior methods tackle this problem using single frame inputs with feature extractors and RNNs, we take a different approach in developing a temporally coherent system that aims to more explicitly exploit 3D features. Our method also looks to tackle the issue of temporal consistency by penalizing inconsistent semantic labels over time and modularity by having two separate heads for 2D and 3D navigation.
Problem Statement
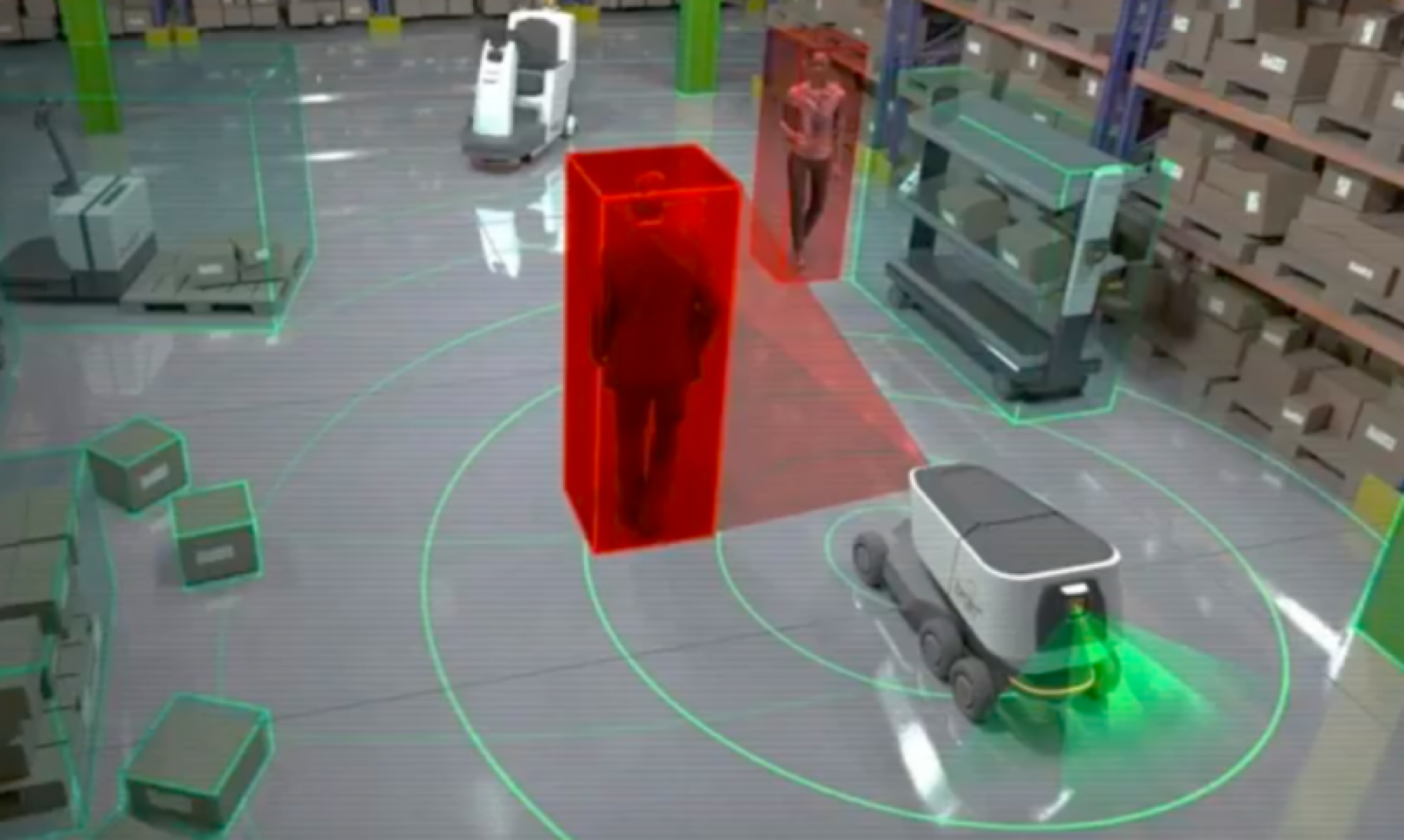
Our problem is colloquially referred to as the ObjectNav problem. Given a specific object category, our agent must identify and navigate within 1.0m of any instance of the given object category. We currently are working on this challenge solely in indoor environments. We hope to explore the Sim2Real capabilities of our method in the Fall.
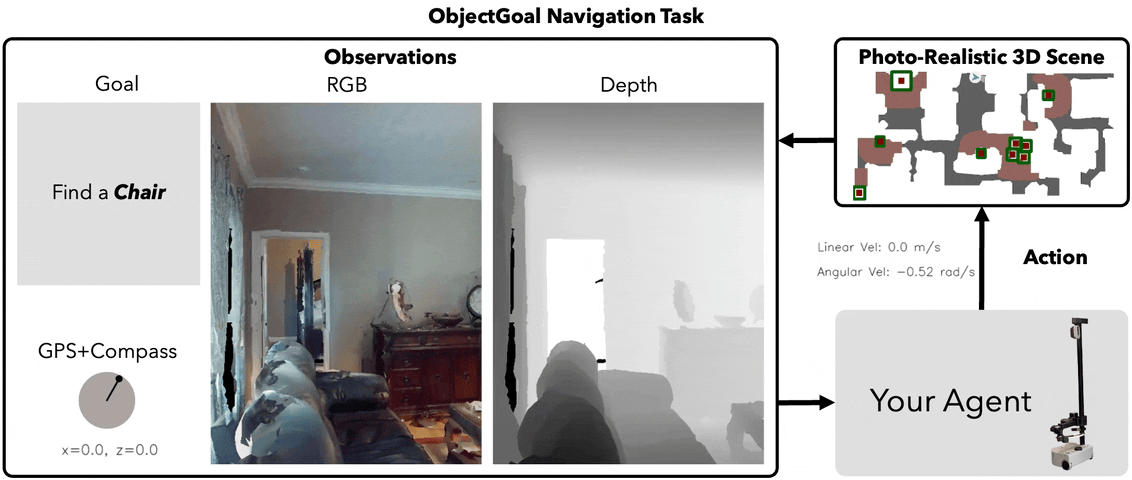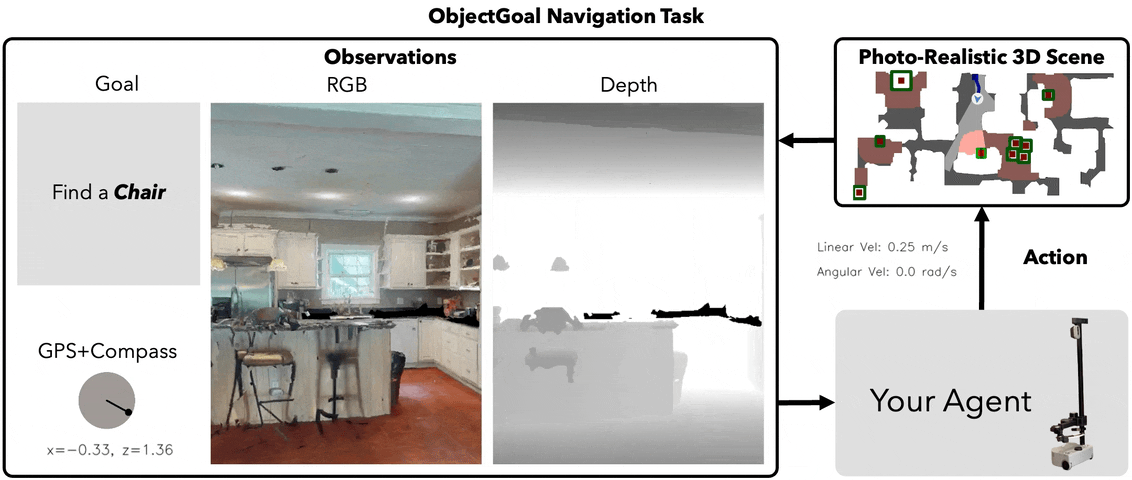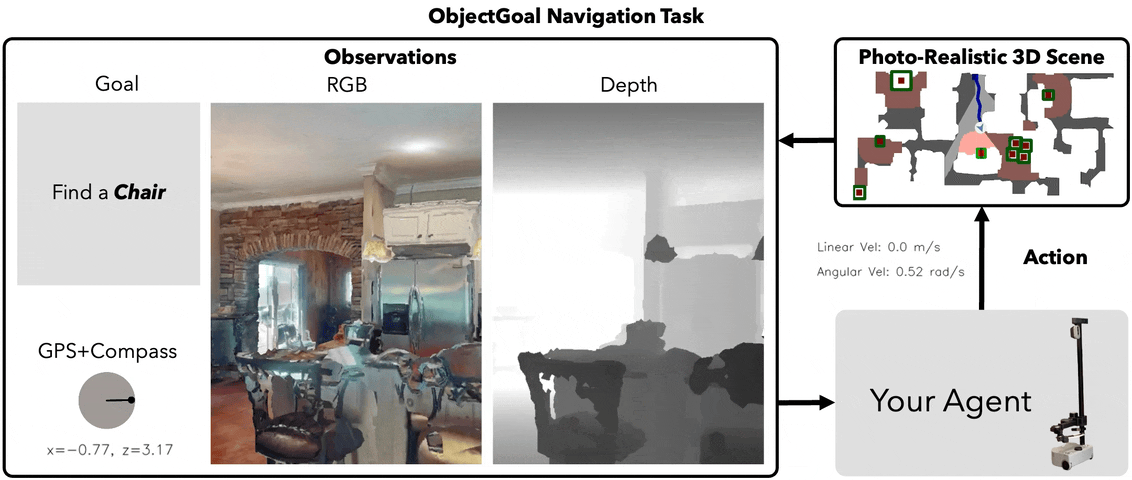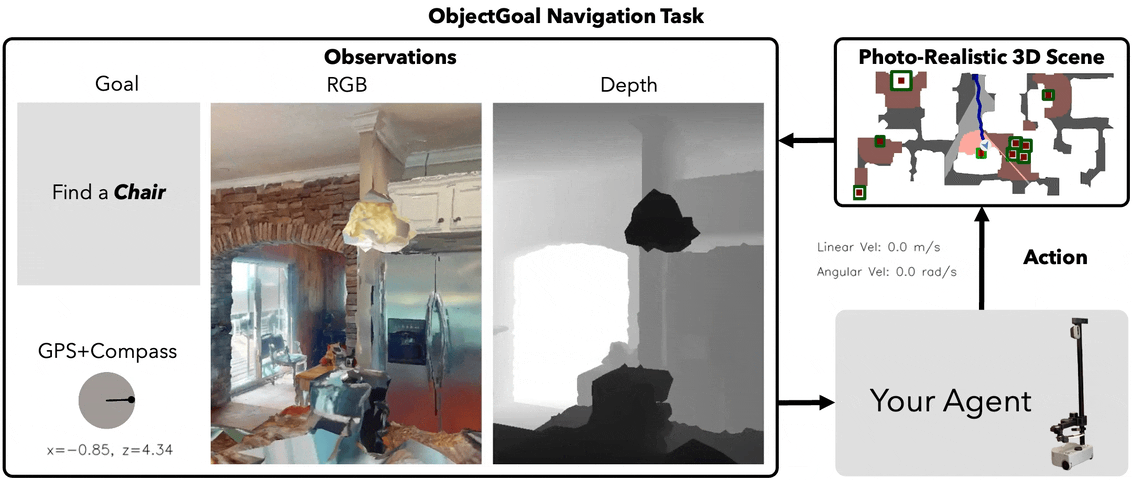
Top Down MAP VIEW

Sensors (INDOOR)
- RGB-D Camera
- GPS Location
- Compass
Methodology
As part of our work, we provide the following contributions:
- Feature extraction for 2D uses RGB and depth information which uses a pre-trained RedNet for semantic segmentation to produce 2D semantic segmentation results. This model is pre-trained on the SUN-RGBD dataset and is then fine-tuned when training the agent to improve the efficacy for the HM3D dataset
- Feature extraction for 3D uses the depth information with the camera intrinsics to create a point cloud. The camera poses are used in order to aggregate and densify the 3D point clouds over time using ICP and allowing for the creation of a confidence score. PointNet++ is then used to produce our 3D features.
- We plan to fuse the 2D and 3D features as input to our RL agents in addition to some context about whether the goal is in sight and the confidence level of the features as the output from our system.
- We plan to train an exploration policy when the semantic goal is not present in the scene
- We plan to train a greedy policy to be used when the semantic goal is present in the scene
Please refer to more details here
Prior Work
Habitat Web
Habitat-Web: Learning Embodied Object-Search Strategies
from Human Demonstrations at Scale
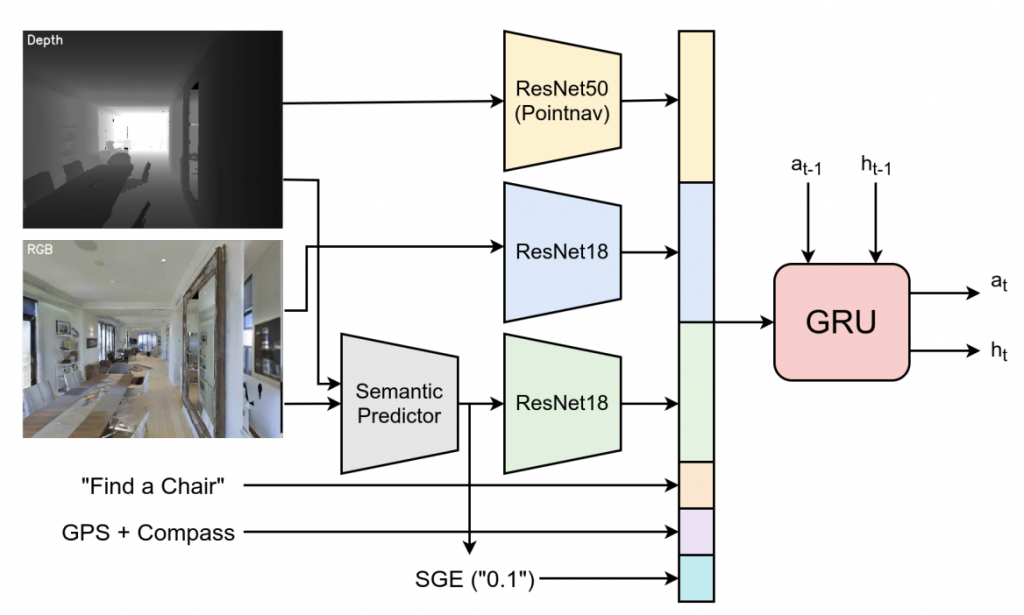
In the Habitat-Web project, researchers employed imitation learning (IL) to address the ObjectNav and Pick&Place tasks in a virtual setting. Utilizing 70k human demonstrations, IL outperformed reinforcement learning (RL) in the ObjectNav task, emphasizing the value of human demonstrations and the potential for further improvements with more data.
The ObjectNav architecture used in Habitat-Web is built on a fundamental CNN+RNN structure. RGBD inputs and GPS+Compass sensor information are processed via feed-forward modules, with the GPS+Compass inputs transformed into 32-dimensional vectors through fully-connected layers. The architecture also incorporates additional semantic features like the semantic segmentation of input RGB and a ‘Semantic Goal Exists’ scalar, which quantifies the visual input portion occupied by the target object category. These semantic features are calculated using a pretrained and frozen RedNet model. Moreover, the object goal category is embedded as a 32-dimensional vector. All input features are combined to create an observation embedding, which is subsequently input into a 2-layer, 512-dimensional GRU at every timestep. This arccgoal – locrobot ||2 hitecture allows for efficient object-search behavior and navigation by capitalizing on the diverse strategies derived from human demonstrations.
3D Aware Object Goal Navigation (CVPR 2023)
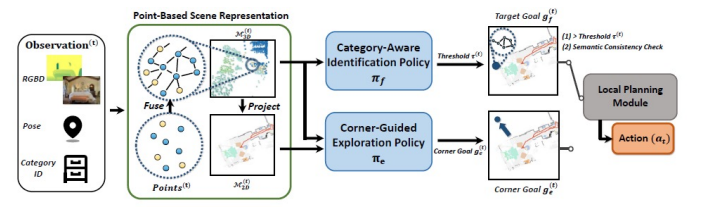
In this work, the authors take an approach to create a point based scene representation which are associated over time to form a voxel occupancy grid. This occupancy grid is then converted to a 2D grid by marginalizing the 3rd dimension. This method trains a corner goal policy for exploration and a identification policy which ensures that the goal exists inside of the scene and that the target category is veritably in the scene. Once the goal is found, this method employs a local planning module to find the shortest path to the goal and generate actions to achieve said goal.