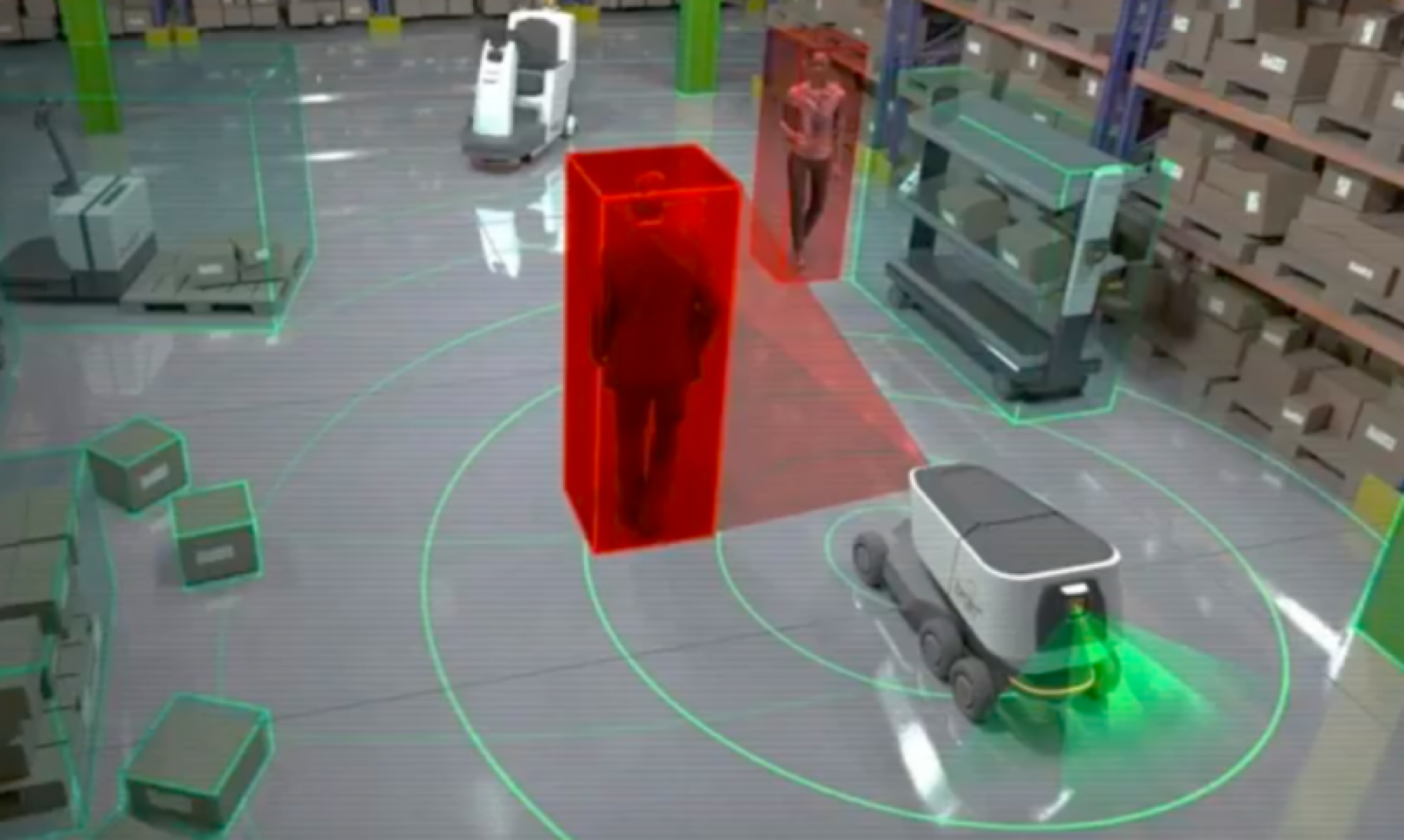
As part of our method’s creation of a semantic map, we aim to first create a 3D reconstruction of the scene. We explore here the task of aligning subsequent frames to ensure consistency of geometric feature. We also explore using semantic segmentation to perform recognitions of pixels and points in the scene.
Method Pipeline
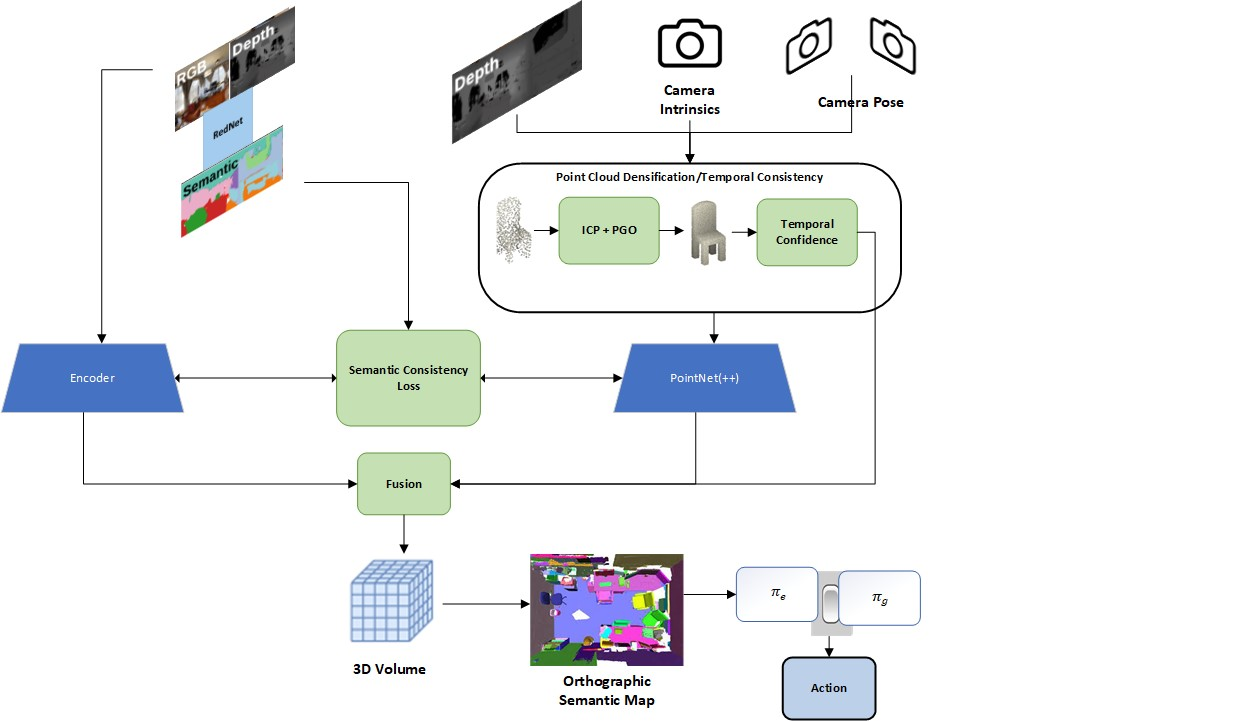
Projecting from 2D to 3D
At each keyframe, given the image, depth, and ego-pose of the robot we can create a point-cloud for the current frame via:
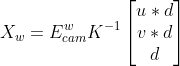
Scan Matching – Humble Beginnings
We then choose to use point-to-plane ICP to align the two point clouds temporally for the 3D reconstruction
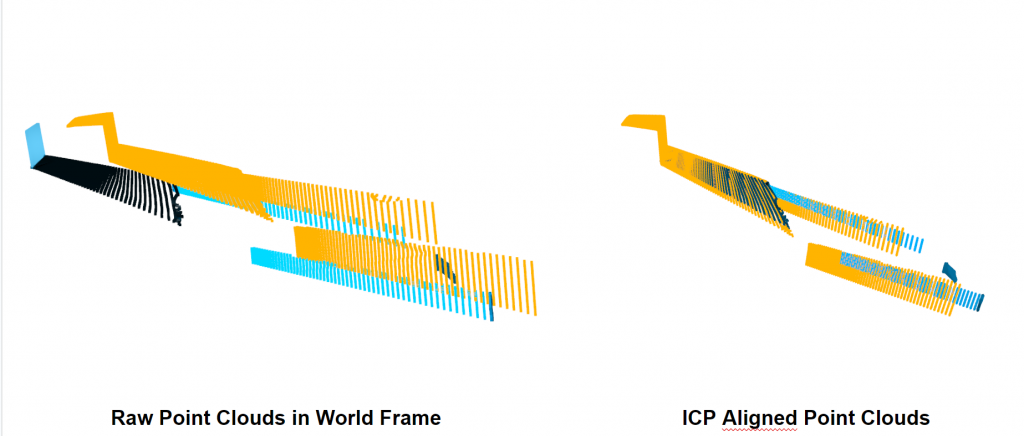
However, over time, we still see an excessive amount of drift accumulate such that we have high quality 3D reconstructions.

Scan Matching – Motion-only Bundle Adjustment via Pose Graph Optimization
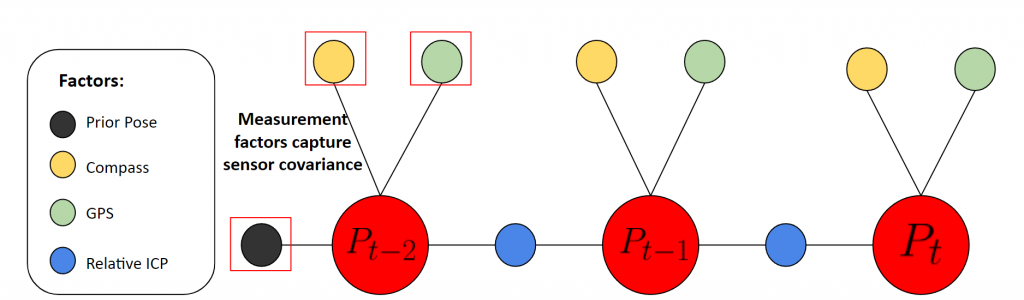
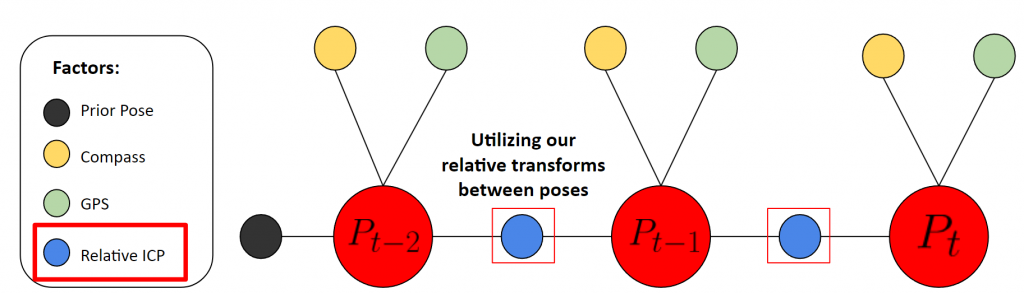
In order to create a temporally smoothed pose estimation, we propose using a simple pose graph to jointly estimate the pose of the robot, incorporating multiple sensor measurements and keyframes. Specifically, we use the ICP estimation for relative extrinsics between keyframes to conenct the poses in the pose graph:
Pose Graph Formulation
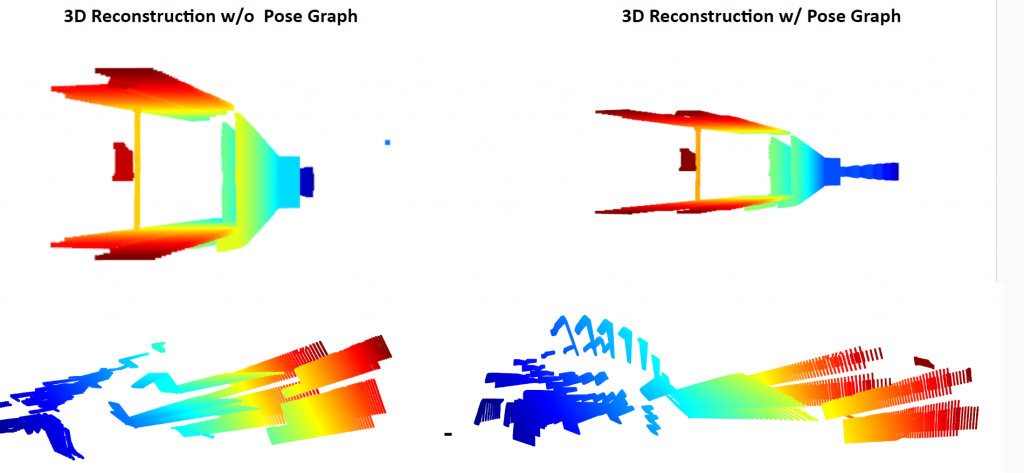
Pose Graph Bundle Adjustment Results
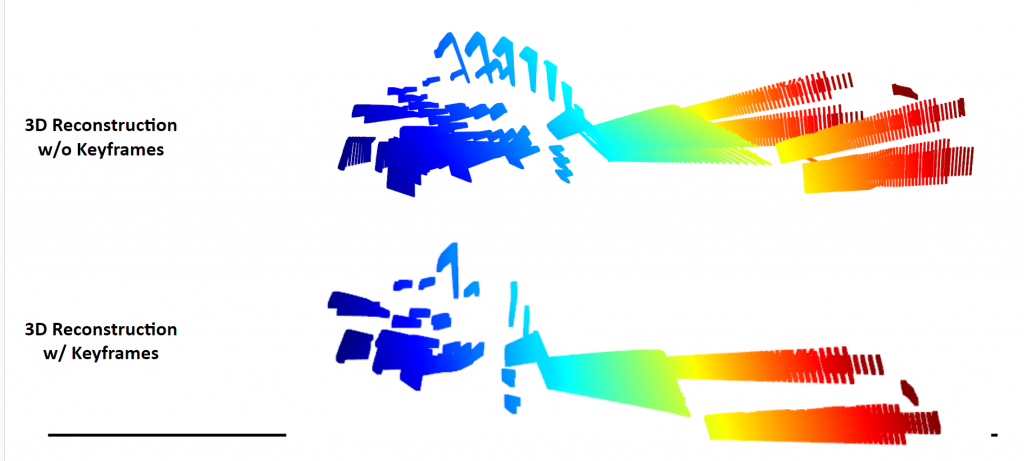
Live 3D Reconstruction with MO-BA
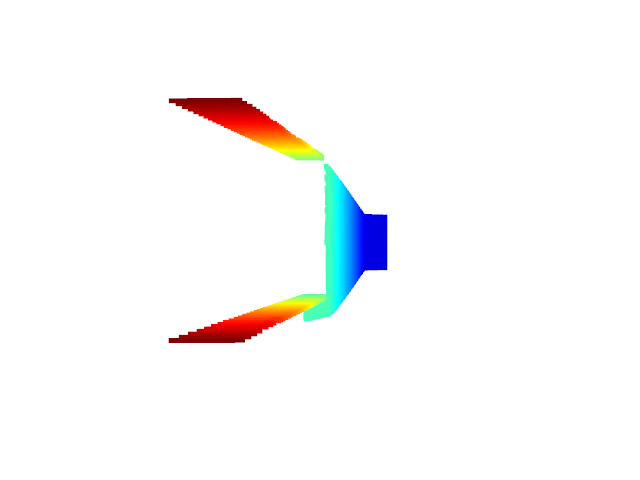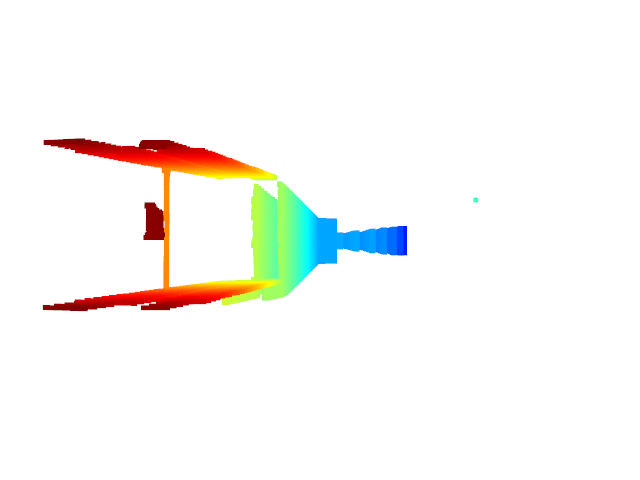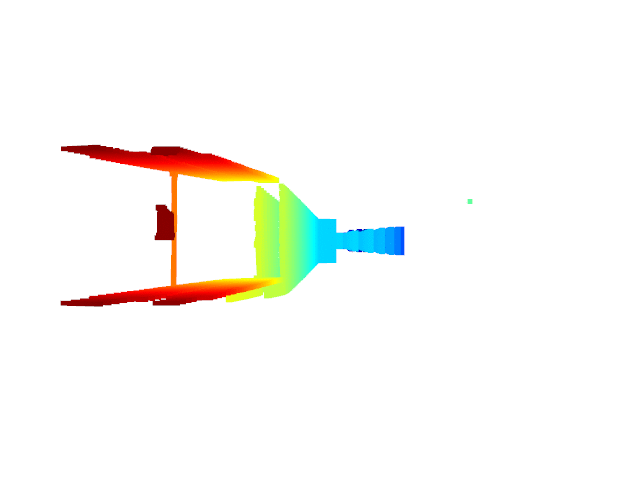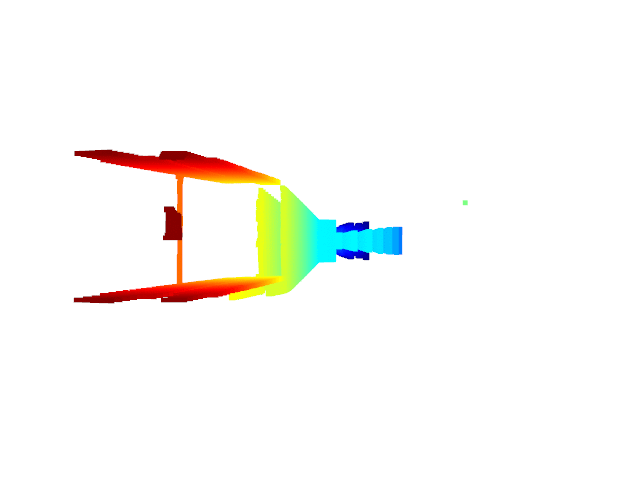
2D Segmentation
Our 2D-segmentation module leverages RedNet, a distinguished RGB-D encoder-decoder architecture renowned for its effective indoor segmentation capabilities. RedNet’s design features a residual structure with skip-connections that adeptly retain spatial details. A standout aspect of RedNet is its dual processing approach, treating RGB and depth images separately before merging their features at various layers. Additionally, RedNet employs a novel training technique, pyramid supervision, which applies supervised learning across multiple decoder layers for enhanced optimization.
RedNet’s efficacy is exemplified by a notable 47.8% mIoU accuracy on the SUN RGB-D dataset, a factor contributing to its popularity in top-tier Habitat Challenge submissions. The encoder’s backbone in both the RGB and Depth branches is a ResNet-50 structure, and depth features are integrated into the RGB branch at five different layers through element-wise summation.
In the decoder, the initial four layers include an upsample residual unit that doubles the size of the feature map. The pyramid supervision approach is utilized to mitigate gradient vanishing issues by introducing supervised learning at five distinct layers. Both the side outputs and final output are processed through a softmax layer and cross-entropy function for final predictions.
RedNet’s performance on the HM3D dataset further illustrates its capabilities. Initially pretrained on the SUN RGB-D dataset, it was fine-tuned using 100k front-facing views from the Habitat simulator. For enhanced visual clarity, labels are placed at each object’s centroid in the bounding boxes, forming an integral part of our debugging environment. This setup aids in swiftly pinpointing model limitations and comparing predictions with ground truth.
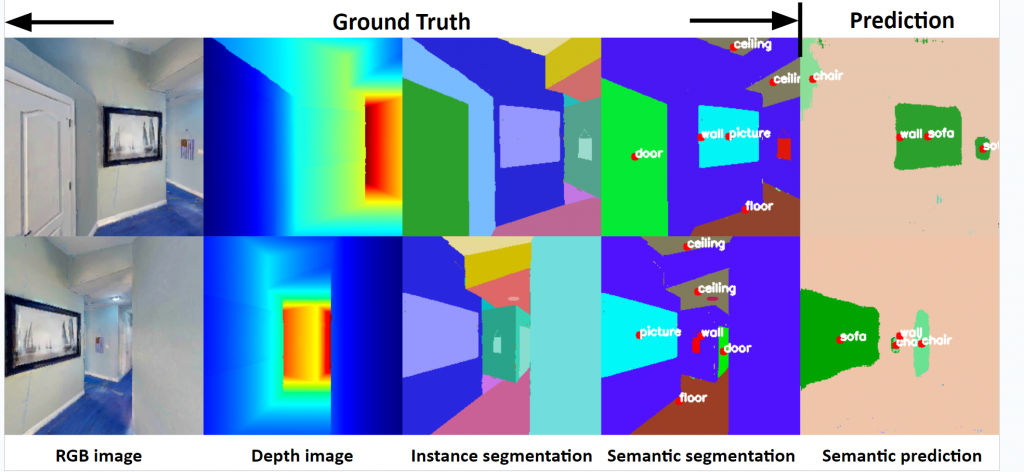
While the model demonstrates impressive proficiency on training data, with a mIoU of 77.09 and accuracy of 91.62, its performance on validation data indicates a notable drop to a mIoU of 24.95 and accuracy of 61.88. This discrepancy suggests a tendency for overfitting, highlighting the model’s challenges in generalizing to new, unseen data.
| mIoU | mRecall | mPrecision | Acc | |
| train | 77.09 | 86.46 | 87.22 | 91.62 |
| val | 24.95 | 36.96 | 39.62 | 61.88 |
Credit: Ye, J., Batra, D., Das, A., & Wijmans, E. (Year). Auxiliary Tasks and Exploration Enable ObjectGoal Navigation. arXiv. https://arxiv.org/pdf/2104.04112.pdf.
3D Segmentation
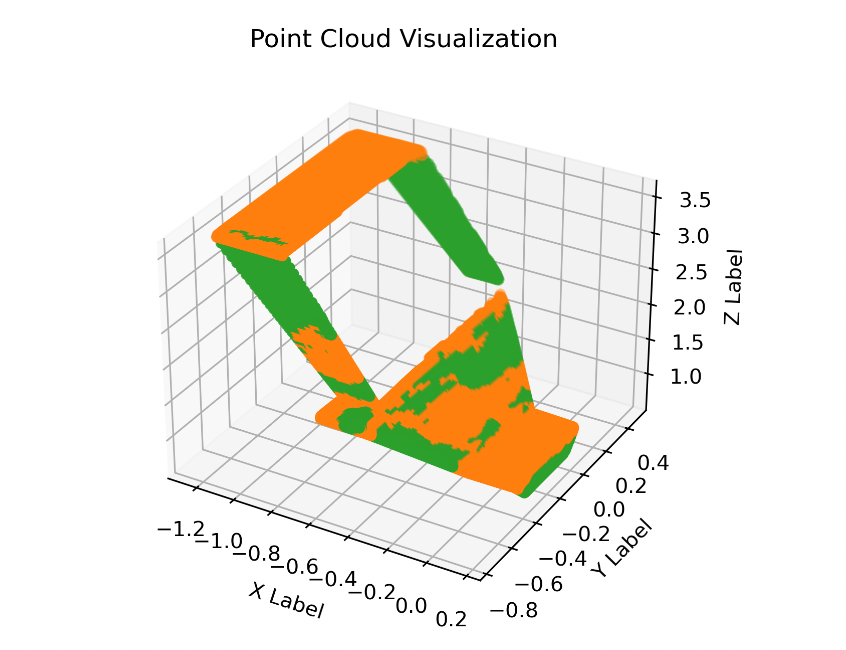
Our 3D segmentation framework incorporates the PointNet++ model, specifically the single-scale grouping (SSG) variant, initially trained on the Stanford 3D Indoor Parsing Dataset (S3DIS). This model has demonstrated commendable performance with an overall accuracy of 83.0% and an average class IoU of 53.5%. When tested on the HM3D dataset, the visualized point cloud depicts walls as green and floors as orange. Despite successfully identifying large segments, the segmentation outcomes indicate there is room for improvement in terms of precision and detail.
3Semantic S2egmentation
Navigation Rewards
| Reward | Formula | Used When Training | Notes |
| Rslack | -λ1 | Both | This is to ensure the agent is implicitly rewarded for navigating and finding the goal quickly |
| Rcuriosity | λ2log(points t+1 ⁄ pointst) | Exploration Policy | When exploring, encouraging curiosity and not staying in the same area |
| Rnav | λ3 e-|| locgoal – locrobot ||2 | Greedy Policy | Reward for navigating to the goal as quickly as possible once identified |
| Rgoal | λ4(goal_pix / total_pix) | Both | Rewards when a goal is in sight, the more of the goal that is in the FOV, the larger the reward. This will incentivize the agent to not get stuck when the goal is occluded |