
[1]EchoMimicV2: Towards Striking, Simplified, and Semi-Body Human Animation
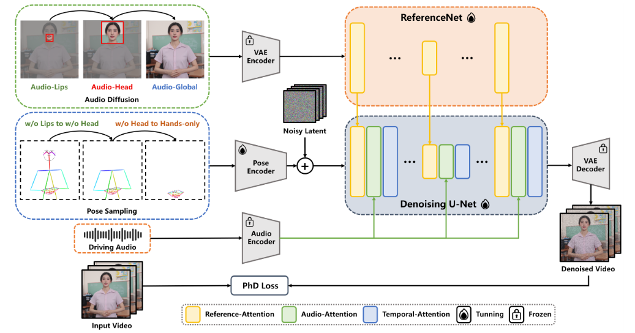
EchoMimicV2, that leverages a novel Audio-Pose Dynamic Harmonization strategy, including Pose Sampling and Audio Diffusion, to enhance half-body details, facial and gestural expressiveness, and meanwhile reduce conditions redundancy. To compensate for the scarcity of half-body data, we utilize Head Partial Attention to seamlessly accommodate headshot data into our training framework, which can be omitted during inference, providing a free lunch for animation. Furthermore, we design the Phase-specific Denoising Loss to guide motion, detail, and low-level quality for animation in specific phases, respectively. Besides, we also present a novel benchmark for evaluating the effectiveness of half-body human animation. Extensive experiments and analyses demonstrate that EchoMimicV2 surpasses existing methods in both quantitative and qualitative evaluations.
Limitation of EchoMimicV2:
– Requires manual input of hand pose sequences at inference time
– Lacks gesture diversity due to fixed poses
– Generated gestures can appear unnatural or repetitive
– Not suitable for real-time or interactive applications
[2]TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio-Motion Embedding
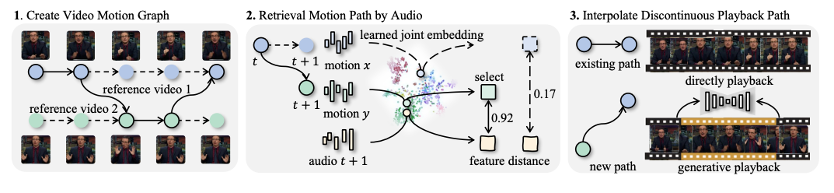
TANGO, a framework for generating co-speech body-gesture videos. Given a few-minute, single-speaker reference video and target speech audio, TANGO produces high-fidelity videos with synchronized body gestures. TANGO builds on Gesture Video Reenactment (GVR), which splits and retrieves video clips using a directed graph structure – representing video frames as nodes and valid transitions as edges. We address two key limitations of GVR: audio-motion misalignment and visual artifacts in GAN-generated transition frames.
[3] From Slow Bidirectional toFast Autoregressive Video Diffusion Models
Current video diffusion models achieve impressive generation quality but struggle in interactive applications due to bidirectional attention dependencies. The generation of a single frame requires the model to process the entire sequence, including the future. We address this limitation by adapting a pretrained bidirectional diffusion transformer to an autoregressive transformer that generates frames on-the-fly. To further reduce latency, we extend distribution matching distillation (DMD) to videos, distilling 50-step diffusion model into a 4-step generator.
