Dataset Collection
We collect monocular RGB-D videos using an iPhone with the Record3D app. For each scene, we capture two types of data:
- A static object filmed with a moving camera
- A dynamic object filmed by two synchronized cameras.
Pipeline
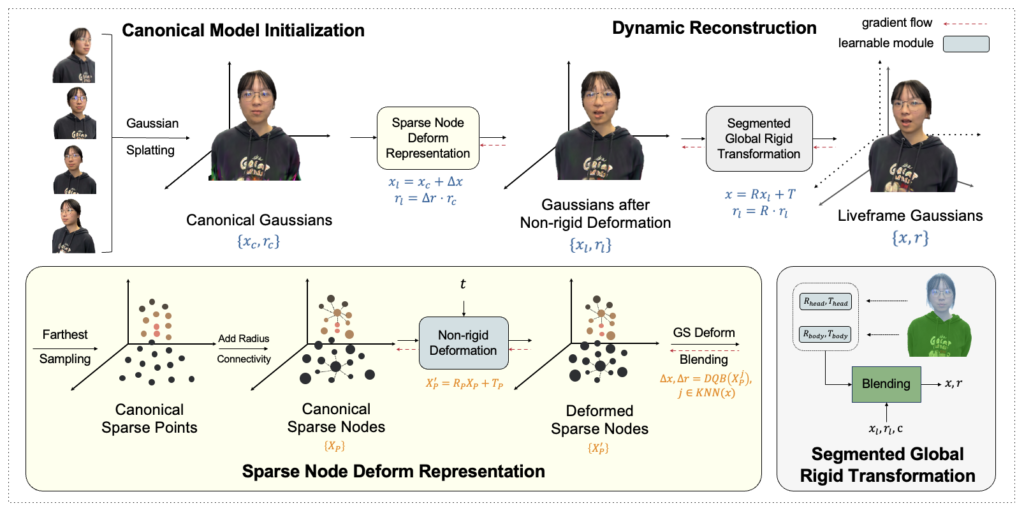
In the process outlined in Figure 4, initialization of the canonical Gaussians from a static sequence marks the starting point. This initialization sets the foundation for subsequent steps, where at each timestep, the deformation is broken down into two distinct components: a rigid global transformation and a non-rigid local deformation. This decomposition strategy allows for a nuanced understanding of the evolving scene dynamics, capturing both global shifts and localized changes over time. The frames are processed in a progressive fashion.
The non-rigid local deformation is modeled using a sparse node representation obtained by performing farthest sampling on canonical Gaussians to obtain canonical sparse points. Each point is associated with a radius to determine its influence and neighborhood connectivity. The deformed Gaussians are obtained by performing Dual Quaternion Blending(DQB) using the nearest neighbor nodes at time ‘t’. The rigid global transformation is obtained for each gaussian by blending the individual segment global transformations based on the neighborhood segment category of the gaussians.
Finally, as the process unfolds, liveframe Gaussians are effectively utilized to generate RGB and depth images, providing a comprehensive representation of the scene’s visual and spatial characteristics. Through this systematic approach, the framework ensures a robust and accurate rendering of dynamic scenes, offering valuable insights into their temporal evolution.