
Related work
Debiasing using a small amout of fair data and a fairness classifier is a well establieshed approach to improve fairness in generative models [1]. Specifically, in the first step, a classifier is trained to distinguish if a sample is containing more or less bias.
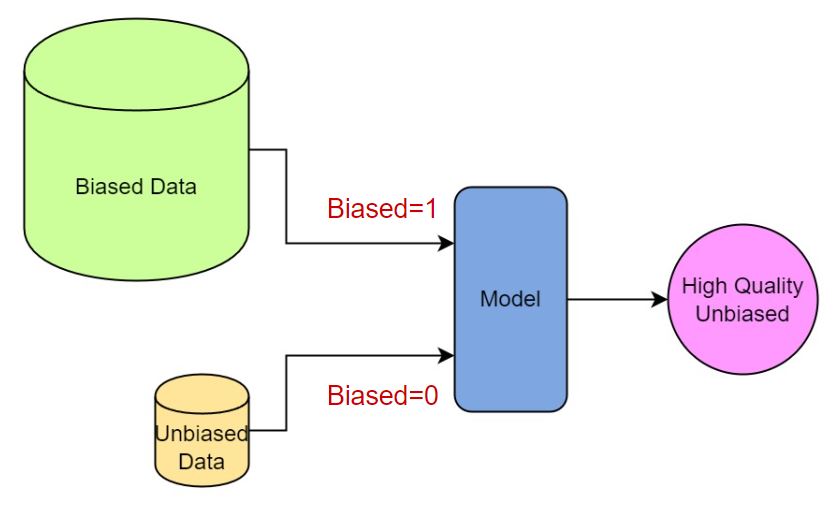
Second, the generative model is finetuned on a set of data, in which each data’s weight is assigned by the bias probability assigned by the classifier.
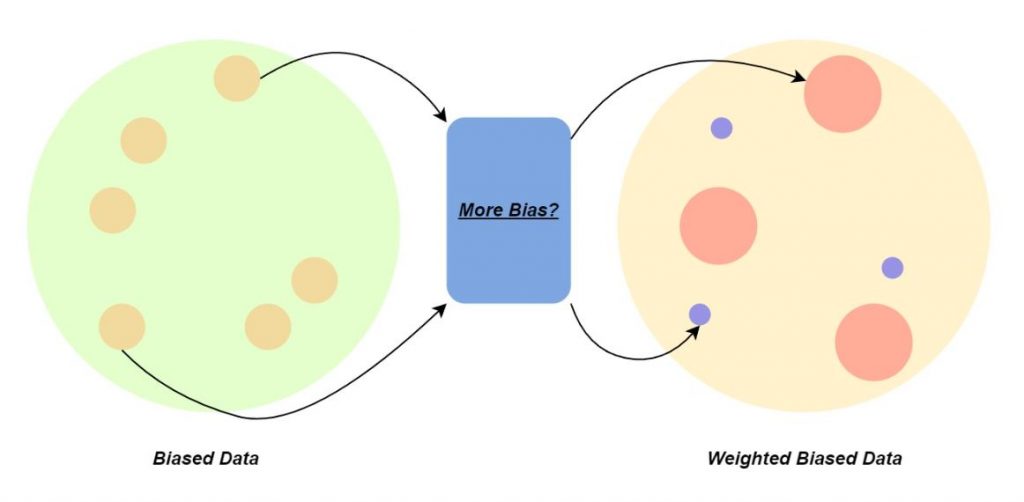
While this method works well for the many GAN models, it is not very practical for the DDIM models since the diffusion process takes much more VRAM and the forward passing takes long.
Shift latent distribution
Another related method achieves the goal by learning and shifting GAN model’s latent sampling space [2]. It first collects sample latent codes generating images for each subclass. For instance, the subclasses for the gender attribute is ‘Male’ and ‘Female’. Then, for each set of code, a GMM model is learned. Finally, fair sampling is done by uniformally sample from each class’s GMM model.
Although this method do not require finetuning the generative model, we found that it is very difficult to learn the GMMs for the DDIM model since its latent space’s dimsion is much higher.
Debiasing single attribute

We approach this task via learning fair text embedding. In the DDIM model, a text prompt is is first turned into a text embedding through the CLIP text encoder. For example in Figure 3, the prompt, ‘face photo of a person’ is mapped to text embedding E, which is a 77×768 shaped tensor.
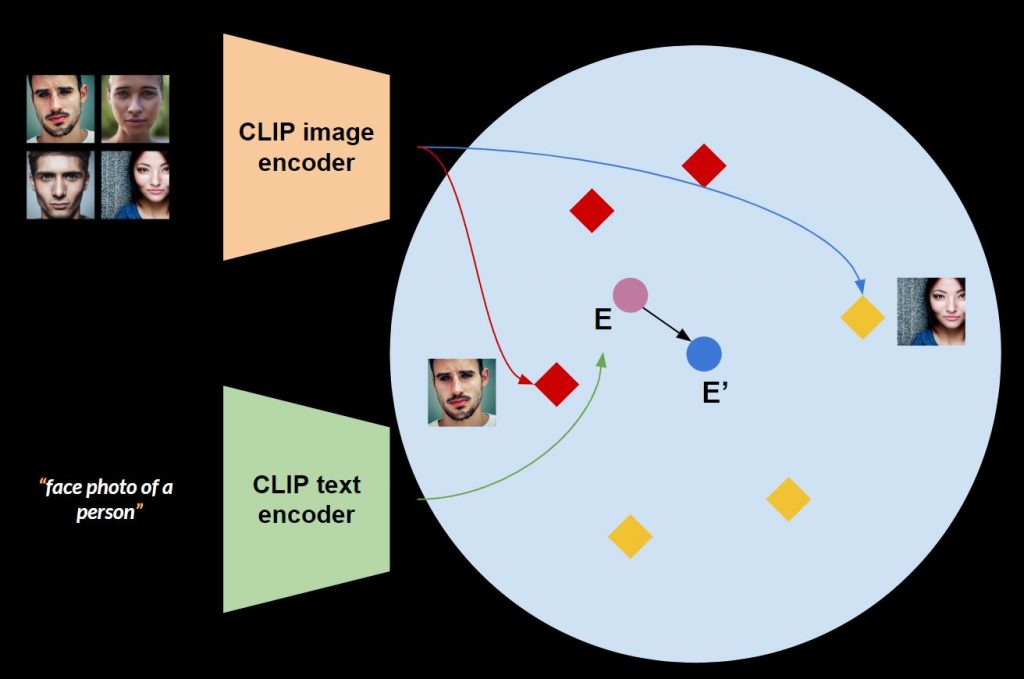
We want to learn a new text embedding, E’, that after the DDIM process, gives us a more fair set of images on the attribute of interest. Specifically, we want to push the E to E’ in the CLIP image and text joint embedding space (Figure 4), where it initially bias to ‘Male’ and then befome fair.
| P(E’ | image batch) | P(E | image batch) | |
 | 1 | 0 |
 | 1 | 0 |
 | 1 | 0 |
 | 1 | 0 |
While learning E’, we first initialize it to the same as E, then we sample batch of images from a small fair data set. For each batch, we extract image features using the CLIP image encoder, and enforce E’s probability given the image features to be larger than E as shown in Table 4. Using binary cross entropy loss, E’ will eventually become a fair text embedding via gradient descent.
Debiasing mutiple attributes
The above method, learning a single fair text embedding E’, is great in 3 aspects:
- Do not require finetuning or learning any new model
- Training takes less than 5 minutes for a single attribute
- performs well for tested attributes
Nevertheless, it is not easy to use a single E’ to cover multiple attributes at the same time. For example, ‘gender’ and ‘wearing or not wearing eyeglasses’. In this case, we can learn one text embedding for each subclass. As shown in Table 5, we learn E1-E4 to cover all the possible subclass combinations for the two attributes. In this way, we can achieve a superior fairness!
| sample | E1 | E2 | E3 | E4 | |
| Man w/o eyeglasses |  | 1 | 0 | 0 | 0 |
| Woman w/o eyeglasses |  | 0 | 1 | 0 | 0 |
| Woman with eyeglasses |  | 0 | 0 | 1 | 0 |
| Man with eyeglasses |  | 0 | 0 | 0 | 1 |
References
- Choi, Kristy, et al. “Fair generative modeling via weak supervision.” International Conference on Machine Learning. PMLR, 2020.
- Tan, Shuhan, Yujun Shen, and Bolei Zhou. “Improving the fairness of deep generative models without retraining.” arXiv preprint arXiv:2012.04842 (2020).