
SliceNet
An alternative approach to solving MVS using Sphere Sweep and Cost Volume Computation, would be to predict depth using a single panorama image view. Intuitively, this makes sense as in all cases, the model outputs a panorama depth map anyway.
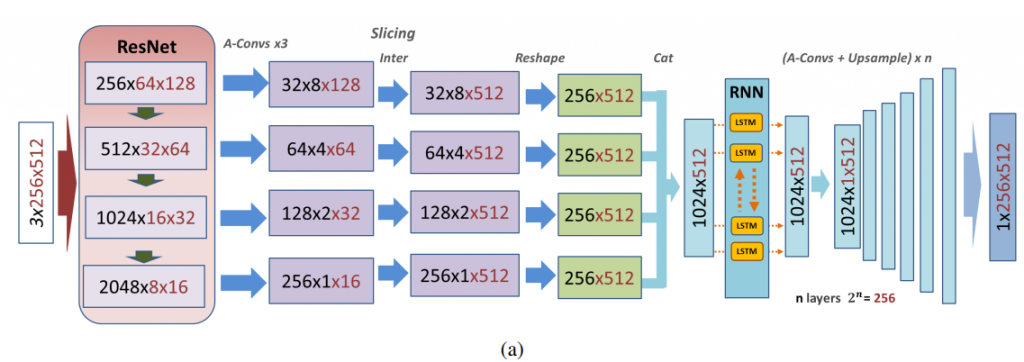
SliceNet[1] estimates depth from a single input panorama image.
- Panorama image is fed to a pretrained ResNet50 feature extractor.
- The last 4 layer outputs are used to ensure that both, high level details and spatial context, are captured.
- These outputs are passed through 3 asymmetric 1×1 convolutional layers to reduce the channels and heights by a factor of 8.
- The width component is then resized to 512 by interpolation and the reshaped components are concatenated to get 512 column slices of feature vectors of length 1024.
- These slices sequentially represent the 3600 view and so, are passed through a bi-directional LSTM setup.
- The reshaped output is then upsampled to obtain the depth map.
The authors used an Adaptive Reverse Huber Loss[2] to train this network.
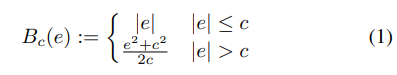
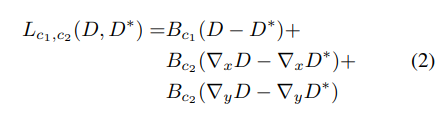
This loss is essentially a combination of L1 and L2 loss. However, just this alone wasn’t enough. As per studies[3], CNNs tend to lose details during tasks such as depth estimation. Thus, the training signal also included loss terms penalizing the gradient along X and Y. These gradients were calculated using horizontal and vertical sobel filters[4].