
For our baseline, we plan on using the ‘End-to-End Learning for Omnidirectional Stereo Matching With Uncertainty Prior[1] paper. The original setup involves a four fisheye camera setup. We implemented this from scratch for our camera setup and data
Summary
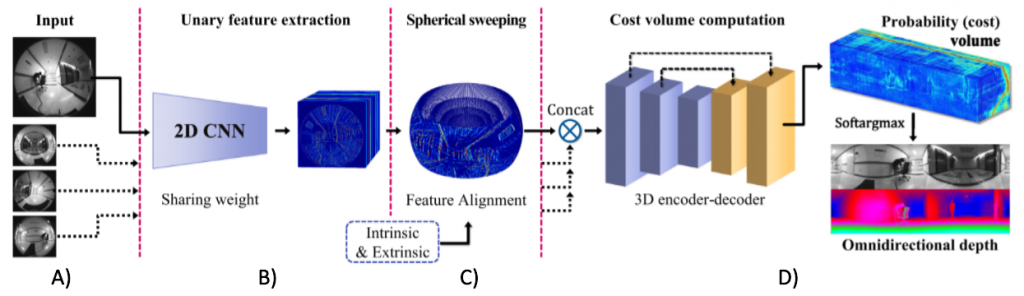
- Sphere Sweep (C) – Every pixel of the six fisheye images is projected onto n spheres. These spheres lie evenly between the minimum and maximum depth to be measured.
- For every pair of images, the n spherical representations are integrated and then averaged over to form a 4D cost volume.
- The cost volume is then passed through a 3D encoder-decoder to generate the depth map (D).
- To save on computation and memory, sphere sweep is run on feature maps generated by a 2D CNN feature extractor (B) instead of the images themselves.
Uncertainty Prior
In case of hard matching cases such as textureless, reflective, or occluded regions, the depths predicted might not be accurate enough. In such cases, having a confidence measure of the model predictions would provide a good indication of where the model doesn’t perform well. This measure would provide the model a great training signal to penalize such scenarios and detections appropriately.

One of the novel ideas presented in this paper included having an uncertainty prior. The uncertainty, measured using entropy, information would be used to filter out depths with uncertainty higher than a threshold. This information would also be used to enforce an uncertainty loss thus, forcing the model to learn such cases explicitly.
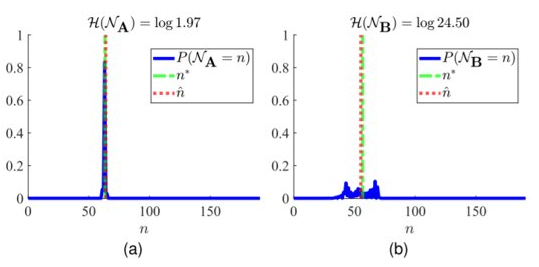
The graphs above two scenarios of depth prediction. In (a), the depth is predicted with high probability. The predicted depth is close to the ground truth depth and so, the overall loss is low and the uncertainty loss is low as well. In (b), however, the depth predicted is very close to other depth candidates around it. Fortunately, the predicted depth turned out to be very close to the ground truth depth. So, the loss is low. However, due to the low and distributed probabilities, the entropy is high and the overall uncertainty loss is high. The model is thus, forced to disambiguate such scenarios.
This uncertainty prior is yet to be implemented.