Datasets
The primary datasets we used for training and evaluation were MOT17 and MOT20. Both these datasets contain outdoor pedestrian scenes with different levels of density and a mixture of stationary and moving cameras. The ground truth tracking label is provided, which we ignore during inference, using only detections.

Evaluation
We evaluate our method using the commonly used HOTA metric, comparing against other SoTA algorithms on MOT17 and 20. HOTA equally weights detection quality and association.
A correct detection is based on a predicted bounding box having an overlap of > 0.5 IoU with a ground truth bounding box. This is largely influenced by the detector’s performance, although as our method rejects tracks below a certain length, having correct tracks can reduce the number of false positives from spurious detections. We use the same detector as other top performing methods for fairness.
Our method associates these bounding boxes into tracks with unique IDs. A predicted track has a track-IoU with a ground truth track based on the number of bounding boxes which correctly belong to the same ID. HOTA greedily assigns the predicted tracks to ground truth tracks based on the best track-IoU. Our algorithm for association completely influences this half of the HOTA metric.
Background: SORT and OC-SORT
In the last year, tracking by detection MOT approaches such as ByteTrack and OC-SORT that build on top of SORT have gained prominence as the most performant approaches.

SORT is an IoU based method. A track is parameterized by a simple Kalman Filter (KF) with position and velocity of the center and size of the object. At frame (t), the KF makes a prediction of the next bounding box for the track (shown in the figure above as the dashed boxes). In the next frame (t + 1), the IoU of each predicted box is taken with the detector’s predictions. The IoU across the entire frame is maximized by the Hungarian matching algorithm. By maximizing the IoU between KF predictions for (t + 1) from existing tracks and detector predictions at (t + 1), SORT achieves SoTA performance even in 2022 when used with an incredibly strong detector.
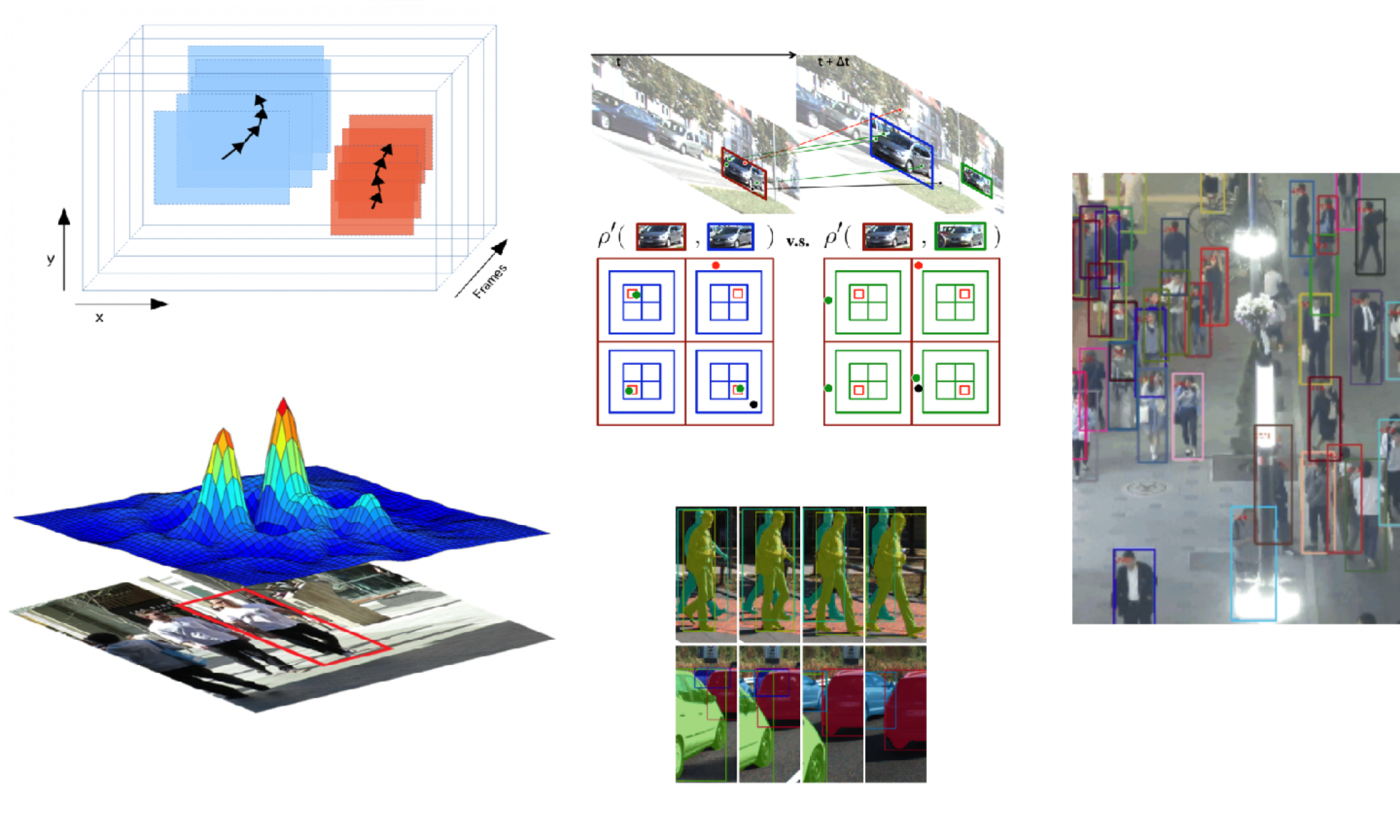
OC-SORT incrementally improves on SORT with several hand-crafted heuristics. It makes the observation that our detectors are so strong that it’s more important to rely on frame to frame observations (hence, Observation Centric SORT) than the KF state.
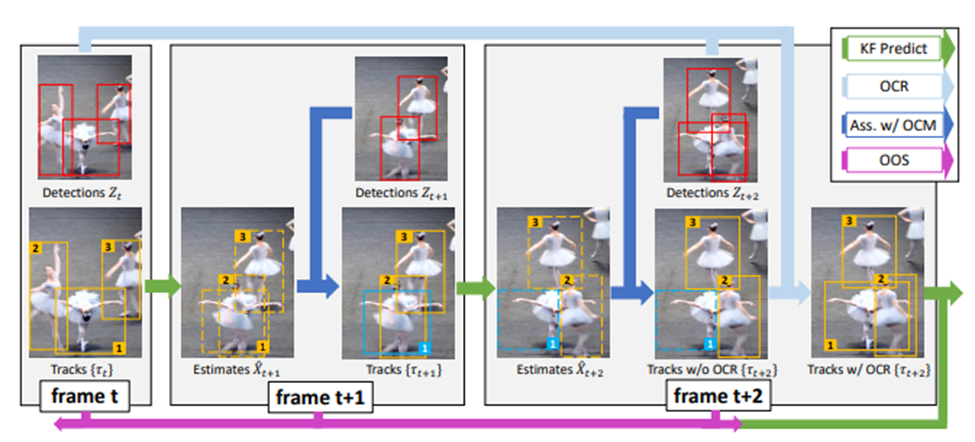
Their first contribution involves ignoring the KF predictions when a track is lost, i.e. no detection is found at frame (t + 1) that matches the KF prediction. Rather than bootstrapping the prediction of the KF state, they simply continue to look in the same place where the detection was lost. This is coined as OCR (observation centric recovery).
Their next contribution is OCM (observation centric momentum), which simply adds a velocity term to the cost. Rather than using just IoU of the KF prediction, they explicitly track just velocity of the track, and weight consistency of velocity between frames.
Their final contribution is OOS (online object smoothing) – when a track is lost, then re-associated, the KF is updated with a linearly interpolated path from the last position the track was detected at. This affects the KF covariance matrix, which weights how heavily the observations affect its estimates.
With just these three contributions, OC-SORT established SoTA on MOT17 and 20.
Our Method: Deep OC-SORT
Motivation
It has been established that SORT-based tracking approaches suffer from inaccurate tracking performance in the face of aberrations such as occlusions or image degradation that causes missed detections – this is especially the case with OC-SORT, which relies on consistent detections.
One way to improve performance is to use ReID models, which provide an embedding for a bounding box modeling its appearance. Then, new detections can be associated with tracks not just based on IoU, but on appearance information as well. However, preliminary experiments with OC-SORT demonstrate that basic ReID models actually reduce performance on MOT17/20. As IoU provides a stronger indicator of correct association than appearance, naively adding an appearance cost injects extra noise to Hungarian matching.
To counter that, we suggest several changes that include adding a more granular ReID model, dynamically updating the appearance model for a track based on the ReID embedding, and adaptively weighting appearance and IoU cost during Hungarian matching.
Our method, called Deep OC-SORT, builds on top of the OC-SORT tracker and is detailed below.
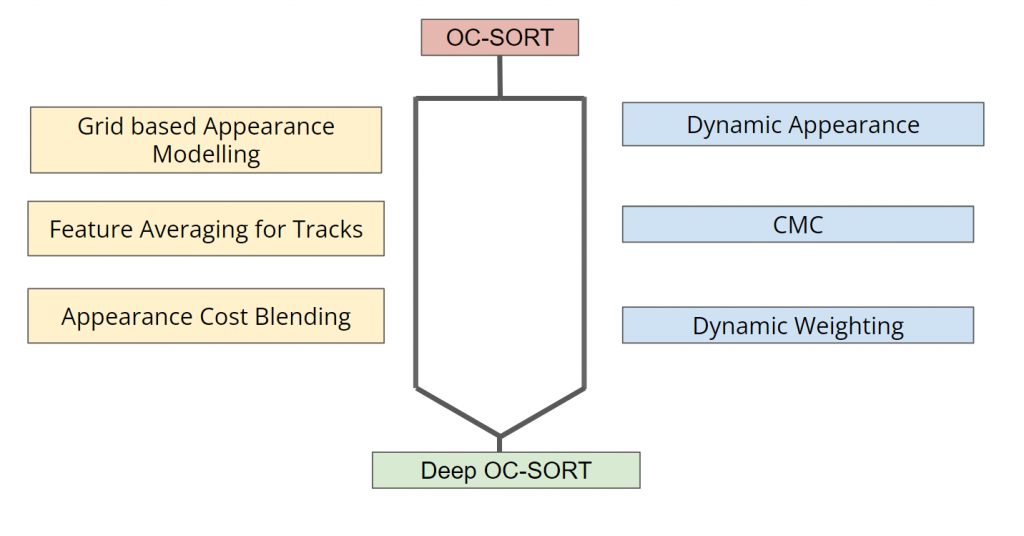
Better Appearance Embedding: Grid Based Appearance Modeling
We propose these changes to specifically answer the question of how to deal with ‘tainted’ appearance features during occlusion, where the bounding boxes of two people are highly overlapped. In this case, it’s possible that the majority of one bounding box actually contains another identity, resulting in a poor embedding.
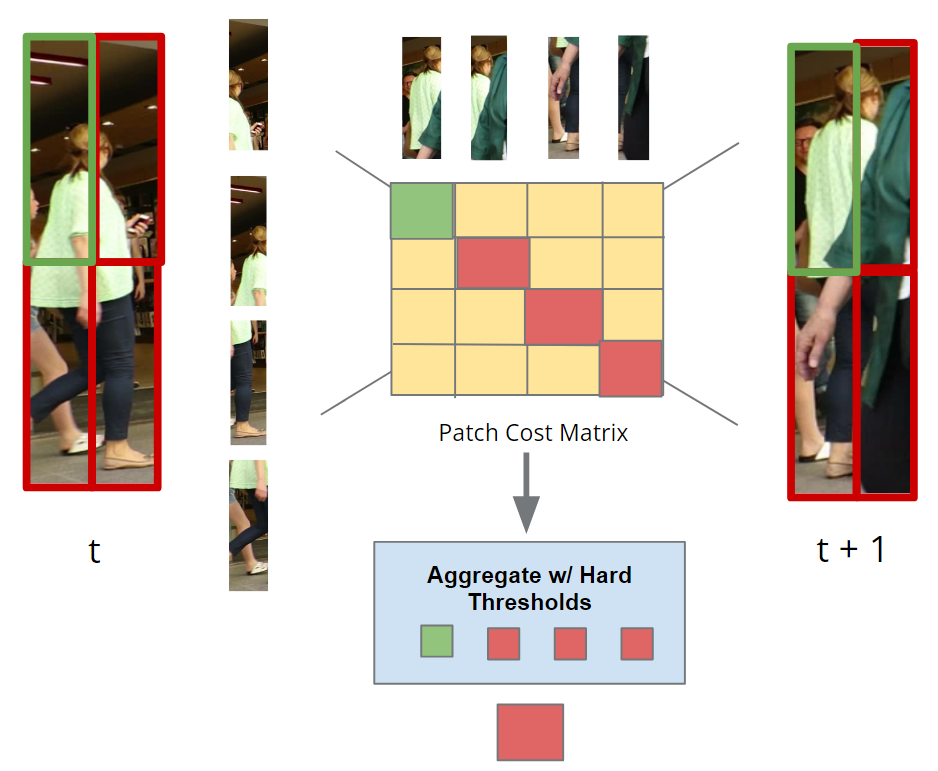
We introduce the idea of splitting bounding boxes into smaller units and computing pairwise appearance features between different bins.
We further refine the cost matrix by applying an aggregation operation that discards contributions from detection-track pairs that include any bin with an affinity value below a pre-determined threshold (most likely due to occlusion). Finally, we average over the last K track frames to obtain a better estimate of the appearance cost.
Better Track Embedding: Dynamic Appearance
Historically, embeddings for a track were aggregated in a feature bank. More recent approaches keep just one representation for the track, updated by an EMA of the new detections. However, these approaches have a fixed EMA alpha, consistently updating the track’s appearance model with the new detection’s embedding, regardless of how good that embedding is.
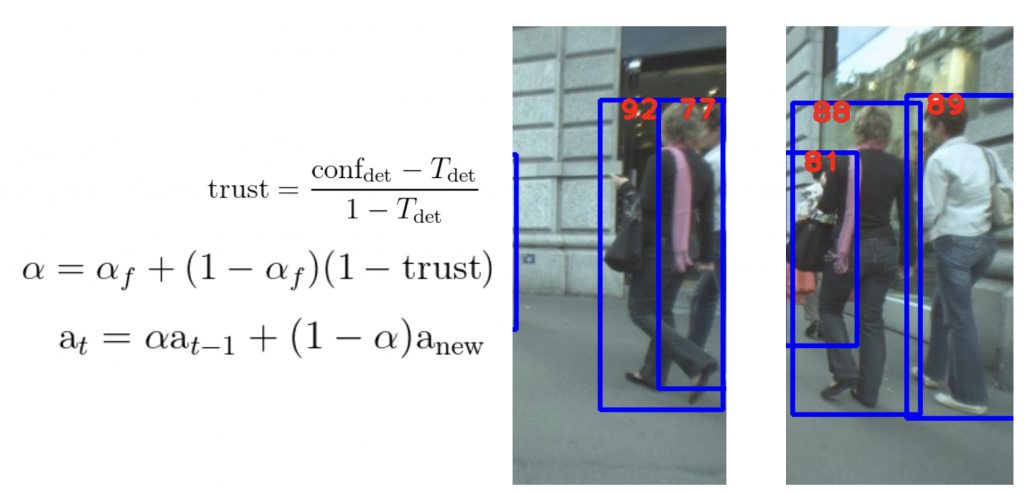
Our insight was to use the detector’s confidence as a proxy for the quality of the appearance embedding – low confidence from the detector could mean that occlusion, motion blur, or degradation of the appearance in some manner. In this case, we want to set alpha for that frame higher, reducing the incorporation of that appearance embedding.
Better IoU Weighting: Adaptive Weighting
We noted earlier that the naive, and common approach, is to weight the appearance similarity of a track and detection with some global weight to add it to the IoU cost. The Hungarian matching is then over some linear combination of the IoU cost and appearance cost.
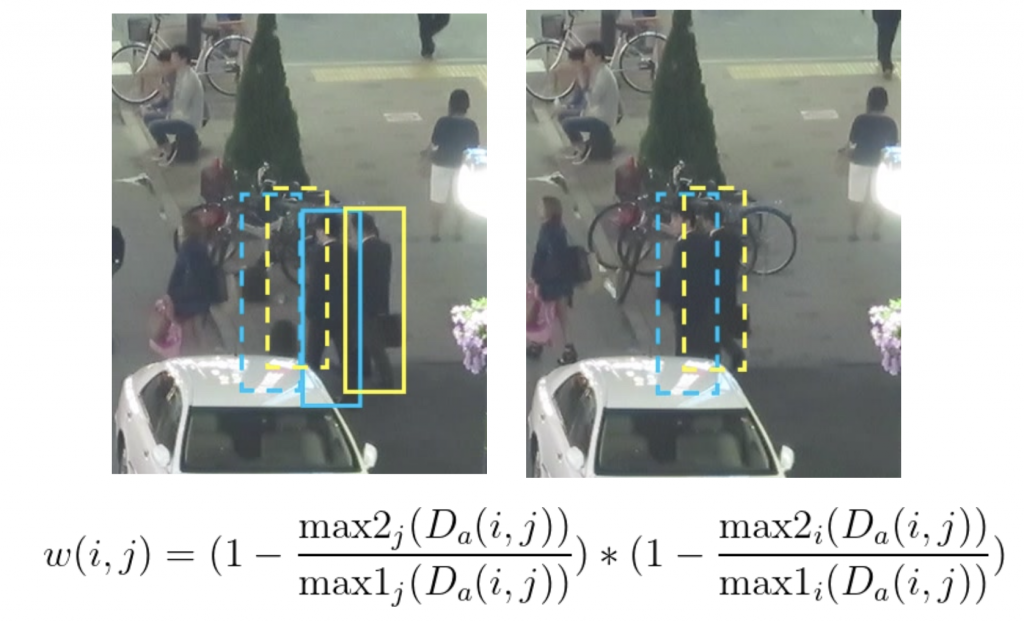
We propose to adaptively reduce the weight of the appearance cost for individual track and detection matching candidates based on the similarity of appearance embeddings. When a track seems equally similar to two potential detections, we reduce the weight – additionally, when a detection seems similar to two potential tracks, we reduce the weight. This is done by comparing the maximum appearance score to the second maximum score, denoted by max2 and max1 below.
Better Detections: Camera Motion Compensation in OC-SORT
Finally we add a well known, but under-utilized, technique called camera motion compensation (CMC), integrating it into the OC-SORT framework. In contrast to the prior focus on appearance, we decide to improve detections as well.

As shown above, when there is camera motion, the predictions of the KF are significantly off. While continuous camera motion will eventually be integrated into the KF state, real world camera motion is often sporadic and decoupled from the path of a pedestrian.
We predict a similarity transform from frame (t) to (t + 1), and apply that to all of our KF states.
The main difficulty is in the details – to achieve good performance, we apply the similarity transform to the OCM velocities, KF covariance matrixes (block rotating correlated variables like (x, y) position and velocity), OCR boxes, and last found detection in OCR.