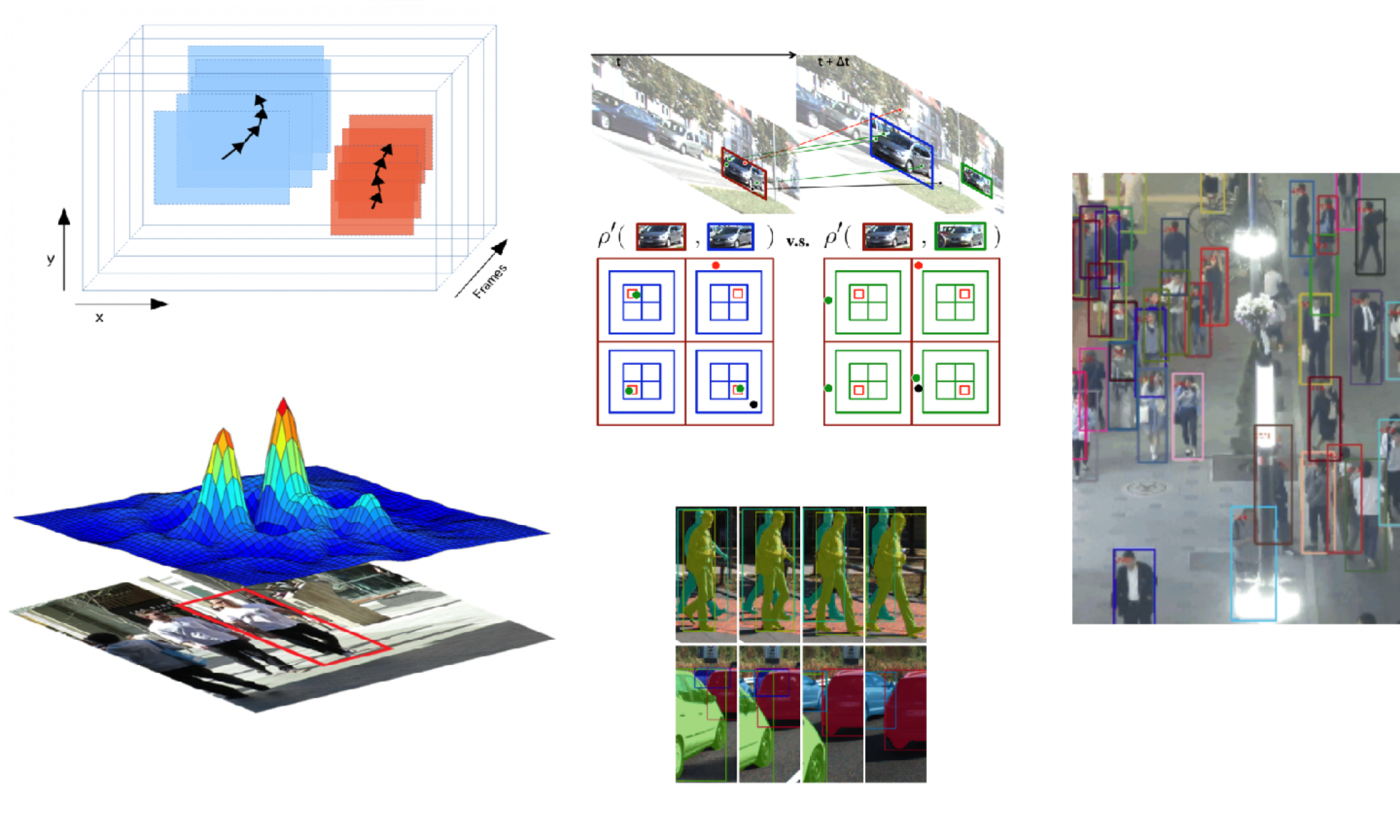
Description
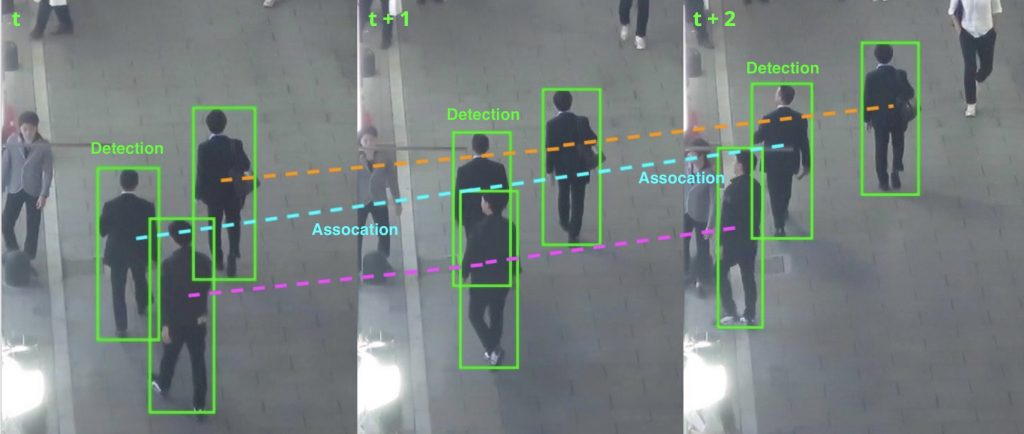
Our researched based goal in this project was to advance the performance of Multi-Object Tracking (MOT) algorithms. The MOT problem is often formulated as the detection and association of multiple objects of interest across frames of a video feed.
Motivation
MOT finds application across a variety of real world problems. In autonomous robotics, tracking objects across multiple frames allows a system to predict higher level statistics of the object over time, enabling forecasting and planning based on the prior path. MOT is also frequently used in security, where tracking a particular identity over time in a crowded scene is difficult to do manually. In analytics, we may want to count the number of unique objects in a scene.

Generally speaking, MOT is important whenever we want to build a model of unique identities in a dynamic scene.
MOT methods that jointly learn detection and association are supervised, requiring training on track annotations. Labeling both bounding boxes and their associated identities is an incredibly challenging and time consuming procedure, with most tracking benchmarks having only several short (<30 second) video clips. As a result, our aim in this project was to study MOT as an exclusively unsupervised problem where tracking labels are assumed to not be available – i.e. we follow the paradigm of tracking by detection. We first train a detector on unassociated scenes labeled by only bounding boxes, then use hand-crafted heuristics to association these bounding boxes across time.

Problem Statement
Our aim in this project is to improve existing MOT algorithms by surpassing their performance on common benchmarks. We additionally ensure our algorithm is unsupervised (doesn’t use tracking ground truth) by following the tracking by detection paradigm and our algorithm is online (predicts each frame given only information of previous frames).

.