

Project Advisor

Professor Jeff Schneider
The Robotics Institute
School of Computer Science
Carnegie Mellon University
Project Sponsor
Introduction
As self-driving is a potential solution to traffic issues including safety, efficiency, scalability, and cost reducing, it’s been rapidly developing in recent years. With the help of quickly emerging neural networks and deep learning models, many missions of the field has been made possible.
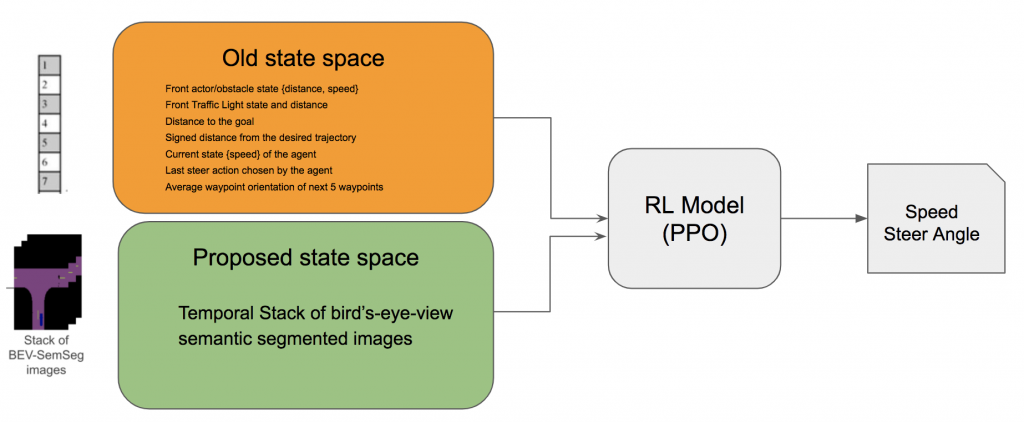
Based on this, the project seeks to propose a new state space that includes visual signals to improve the learning behavior of reinforcement learning (RL) models based on it. Specifically, we propose a multitasking framework to pretrain a neural network based encoder that creates a low-dimensional representation for a temporal stack of semantic-segmented bird eyes view (BEV) images. The pretrained encoder is later used, either fixed or fine-tuned, by the reinforcement learning algorithm.
The progresses and visualized results are shown in this website.
Approach
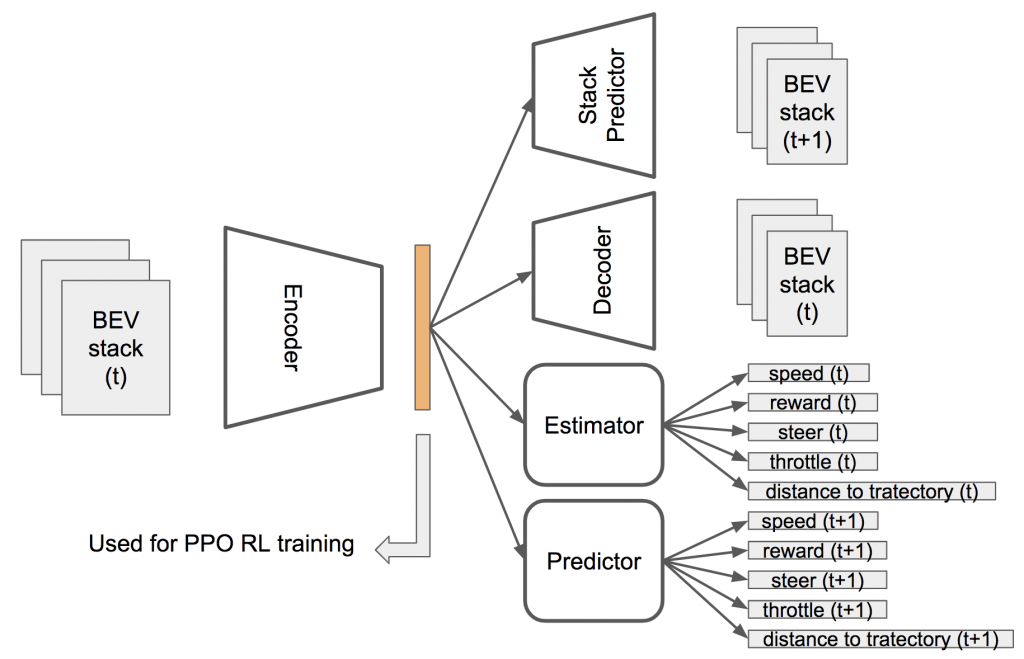
The multitasking framework is illustrated in the figure below. The Encoder and the learned low-dimensional representation in the middle (colored) are later used and fine-tuned along with the reinforcement learning algorithm. During pretraining, multiple unsupervised or self-supervised tasks serve as learning objectives, each of which can be turned on or off depending on the need of usage and analysis. The input of the framework is a temporal stack of semantic-segmented BEV images, while the output depends on which branches are used.
The training objectives include reconstructing the current BEV stack (autoencoder), estimating the current values of some driving-related attributes, predicting the BEV stack a few time steps later, and predicting the future values of some driving-related attributes. The driving related attributes include speed of the ego-vehicle, the reward of a time step, the controlling parameters of steer, throttle and others, the distance to the desired trajectory, and more.
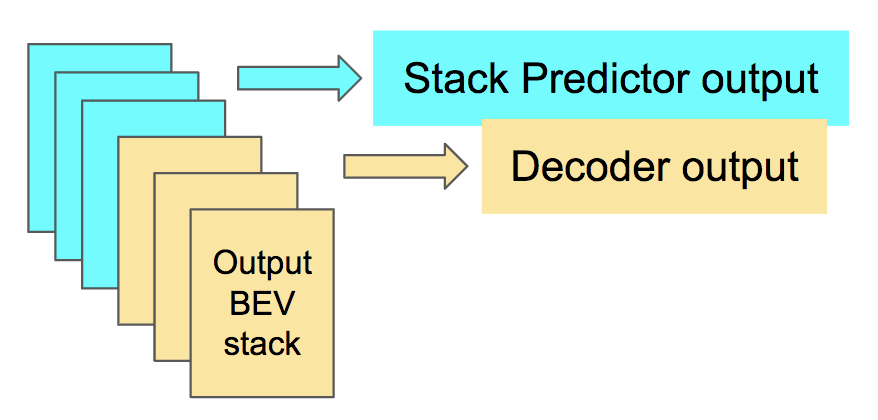
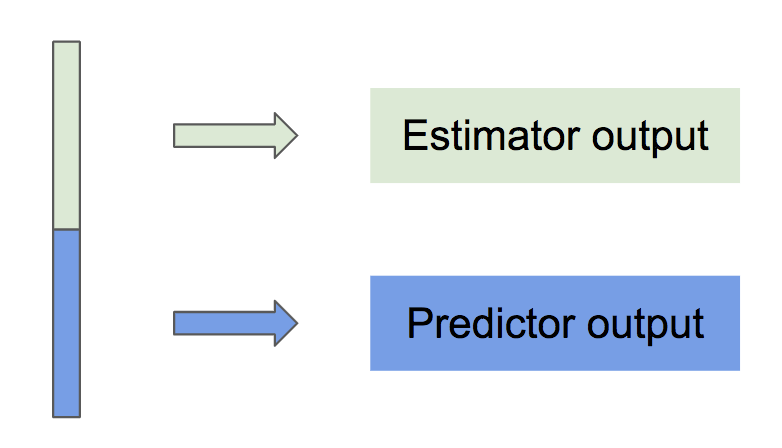
In practice, to accelerate model pretraining and improve the generality of features, learning objectives with similar output structures share a single output branch of the model. As shown in the following figures, Stack Predictor and Decoder share a single spacial-temporal structured output branch, while Estimator and Predictor share a single feedforward output branch. The model outputs are separated by channels and dimensions respectively.
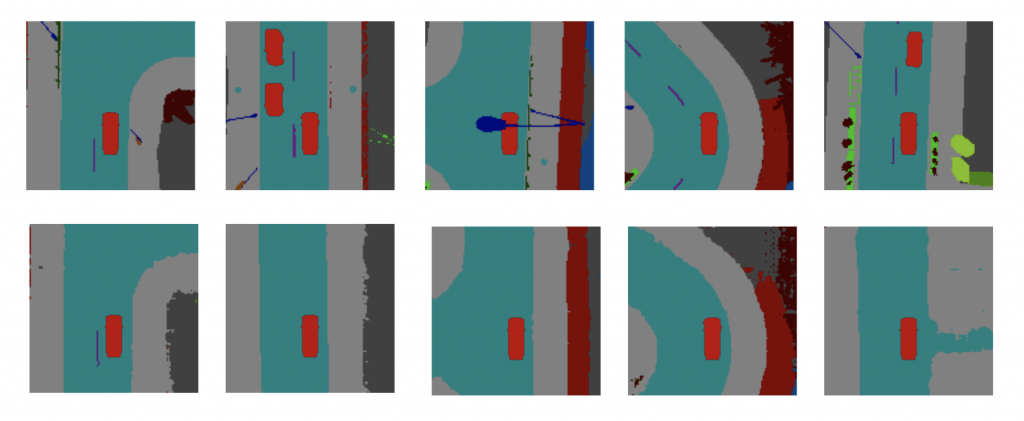
Results Visualization
A brief overview of the results of the model learning process is shown below. The figures show the comparison between model outputs and ground truth labels of the frame reconstruction task and the frame prediction task. Notice that the output for both tasks are temporal stacks of BEV images, while only randomly selected single frames from the stacks are shown for convenience.

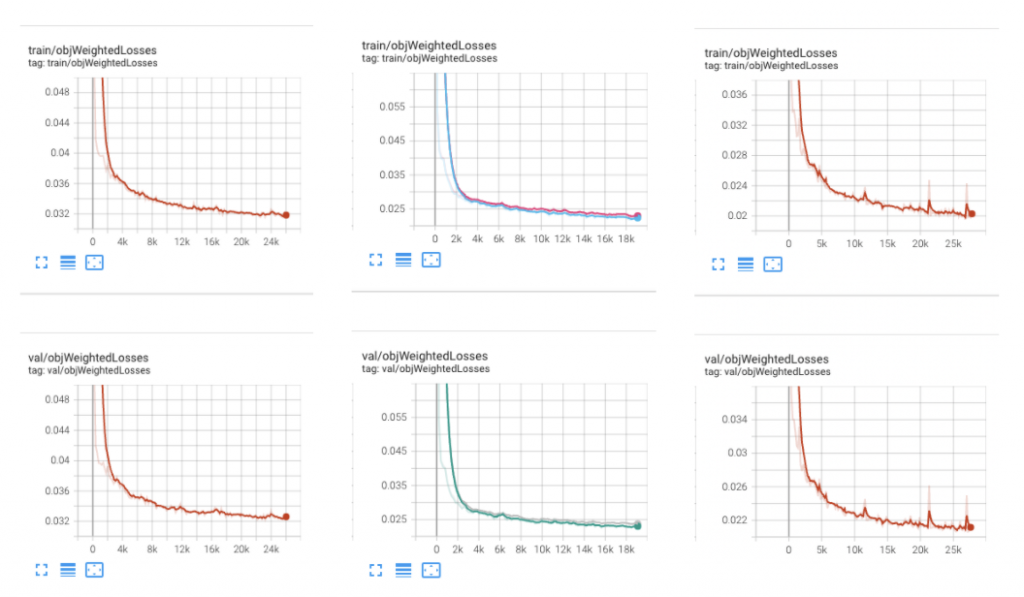
The training and validation losses of various learning objectives are shown below. The curves show the uniform and smooth improvement during the model learning process.
Next Steps
Our next step is to apply the pretrained encoder to an online reinforcement learning model to evaluate its effectiveness on a self-driving task.