
Visual localization plays an essential role in Unmanned Aerial Vehicle (UAV) tasks such as delivery, seed sowing, etc. Typically for these tasks, the majority of the travel is composed of fixed, point-to-point routes. Therefore if we make it possible to collect good-quality data with just one manual pre-flight on the routes, and learn a data-driven re-localization module requiring only images, then we can effectively leverage the few expensive high-end UAVs and the large quantity of regular UAVs. This will bring great autonomy to the regular UAVs and be much more economical in large-scale deployment.
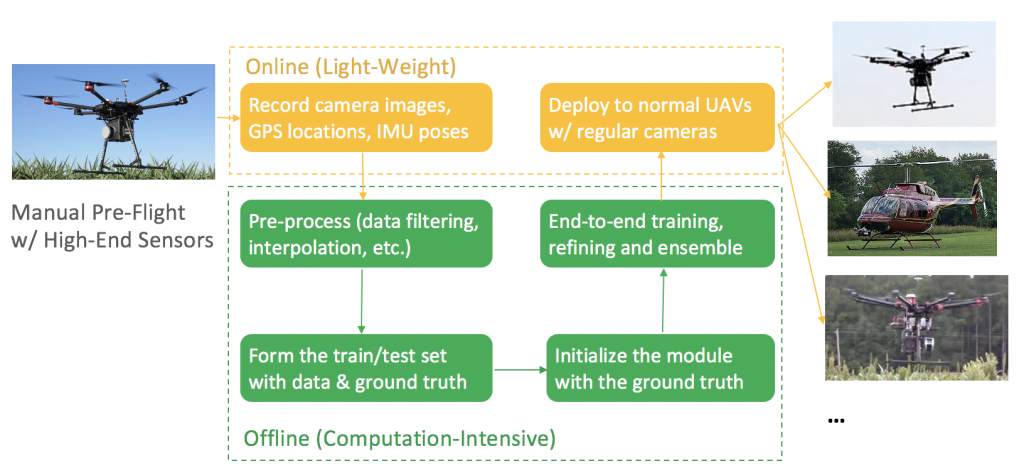
By keeping the learning phase offline, the UAV only needs the camera images on-the-fly for inference. The re-localization module is a separate approach from conventional visual odometry as a fail-safe plan. Therefore, it should be less susceptible to what conventional odometry fails at, such as drifting and tracking lost, and be able to work in the absence of GPS, network connection, etc. And of course, it should be accurate during pose estimation.
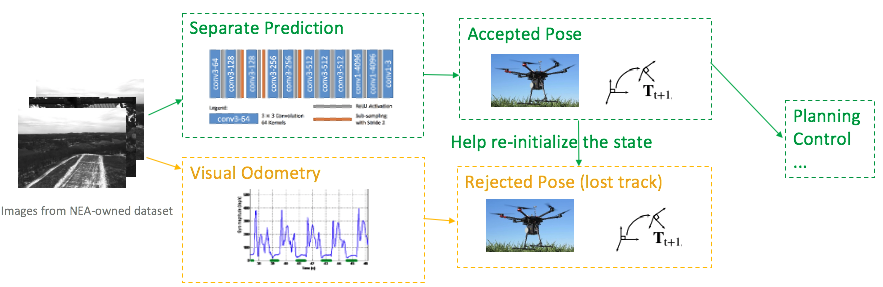
We thereby propose 2 methods to achieve such goals. One is to develop a separate localization module. In case of a lost track, this module can independently predict a pose for planning and control, meanwhile help to re-initialize a state for the visual odometry. Because this is an independent prediction, it is safe even when VO loses its tracking entirely.
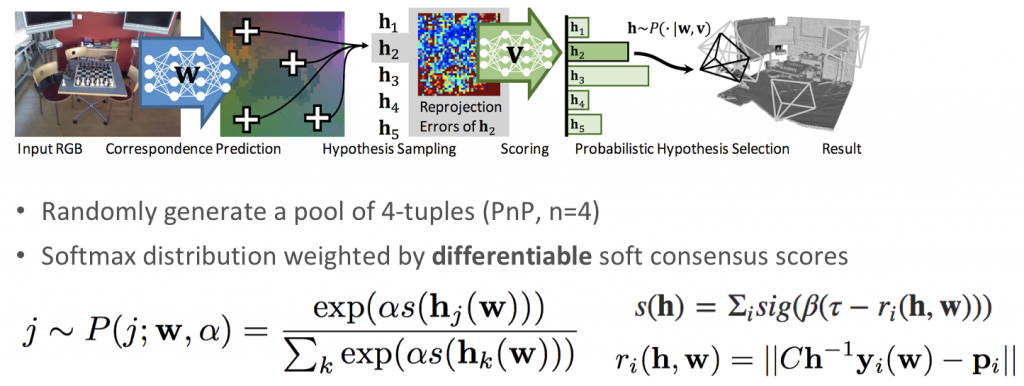
Our first approach is to develop a separate prediction module, based on scene coordinate regression plus differentiable ransac. Given the input image, the network predicts the corresponding spatial xyz coordinates for the pixels in the input. The output scene coordinates are selected by a soft RANSAC and then go through the PnP algorithm to generate the estimation of the camera pose. From RANSAC we generate a pool of pose estimations, and then we back-project the ground truth scene coordinates into the camera frame to evaluate how well it is aligned with the estimation, and select the best one as the final output.

Alternatively, we can also train a network which, instead of proposing its own prediction, but rather tries to correct the output of the visual odometry.This approach is more actively engaging with the visual odometry to reduce the possibility of losing a track. It should work better than a separate prediction when visual odometry is only off by a small amount, but may be challenged when VO is off by too much, in which case we can still fall back to a separate prediction.
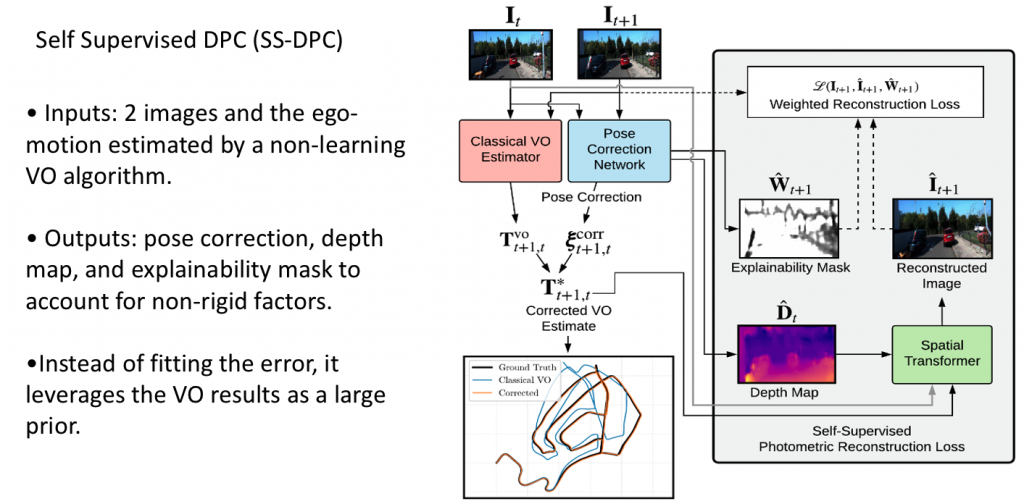
The input to the network is two images and the ego-motion estimated by a non-learning VO algorithm. The pose correction network will output pose correction, also depth map to guide the reconstruction of images between different frames, and use the reconstructed image to compute the photometric reconstruction loss. The network also outputs an explainability mask to filter out the outlier regions, for instance, moving objects, occlusions, etc. Using photometric reconstruction loss seems more reasonable than just fitting the pose difference.