
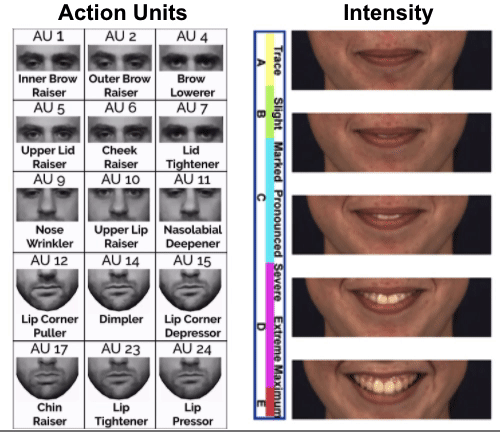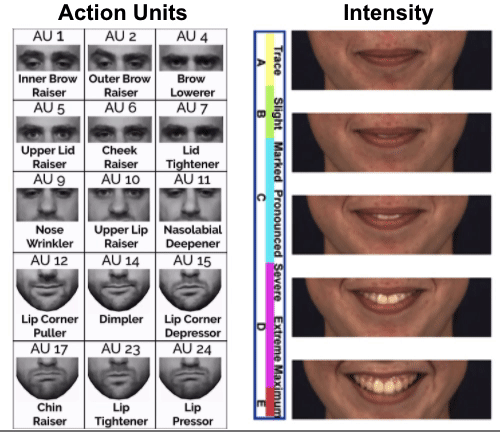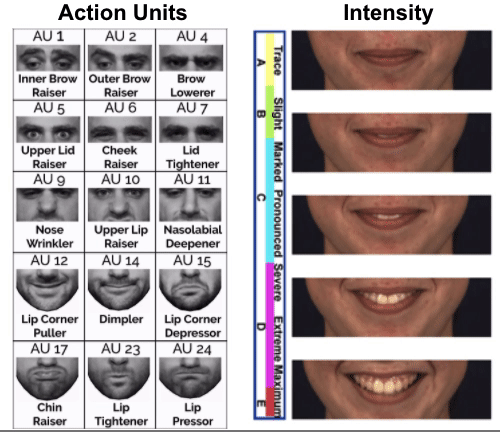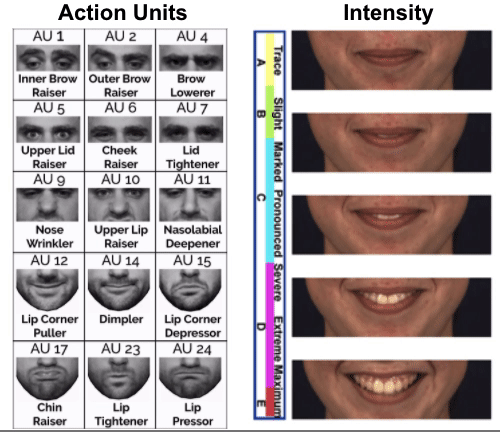
Semantic Facial Image Manipulation is a conditional generation task. The goal is to synthesize a facial image conditioned on both identity and target expression (In our settings, identity information is provided as a 2D image and target expression is provided as a FACS code).
Social Motivation
Fujitsu is interested in using FACS-based expression analysis to analyze viewer’s behavior for advertising and to provide feedbacks for video conferences, remote training, etc. But FACS annotated data is limited in amount and often suffer from skewed distribution. Some expressions and Action Units are much more frequent than others. Using facial expression manipulation can generate FACS annotated data while controlling the distribution of generated data (i.e. we can generate expressions and Action Units we want).
Technical Motivation
2D based methods like GANimation [1] manipulates faces in 2D image space, which often results in artifacts in generated images and failures under extreme head pose and lighting condition.
Proposed Pipeline
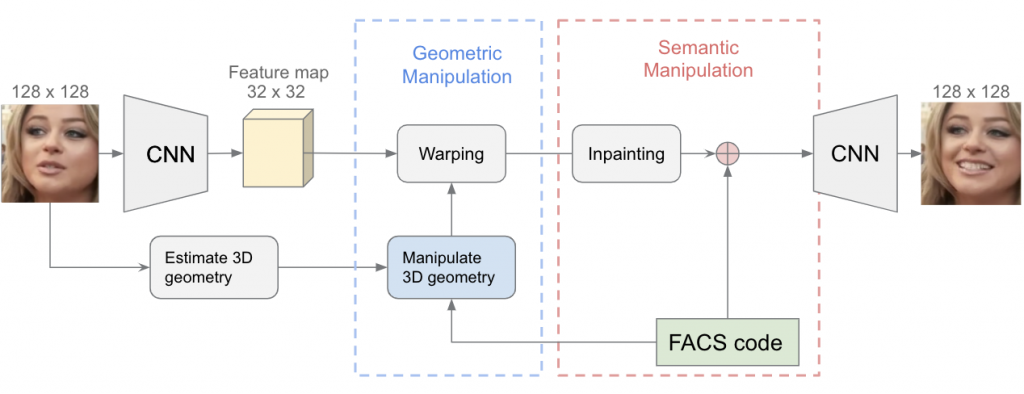
We proposed an encode-manipulate-decode pipeline mainly consisting of two modules, geometric manipulation module and semantic manipulation module. The geometric manipulation module warps the feature maps of input image guided by estimated 3D geometry. In this way, artifacts are reduced by moving the manipulation from image space to feature space. The 3D geometry introduced here helps handle extreme head pose and lightning condition. The warped feature maps are then fed to semantic manipulation module which synthesizes information that was not the input image
References
[1]Pumarola et al. GANimation: Anatomically-aware Facial Animation from a Single Image, ECCV2018
[2]Ekman, Paul, Wallace V. Friesen, and Joseph C. Hager. “Facial action coding system: The manual on CD ROM.” A Human Face, Salt Lake City (2002): 77-254