
Abstract
This project aims at understanding kitchen in 3D to enable robot learning by watching video demonstrations. Humans are really good at watching demonstration videos and imitating given instructions such as cooking recipes but robots haven’t achieved that level yet where they can understand the 3D scene around them just by looking at 2D videos. Robots with such abilities can significantly impact the automation industry, not limited to kitchens or restaurants. We have found that the main bottleneck in accomplishing this task is training robots to learn generalizable manipulations skills because of variation in similar objects around us and lack of real-world datasets. Our goal in this project is to develop a data capture system that can yield a variety of human-level and scene-level annotations without relying on an expert for labeling that can further act as priors for robot learning algorithms.
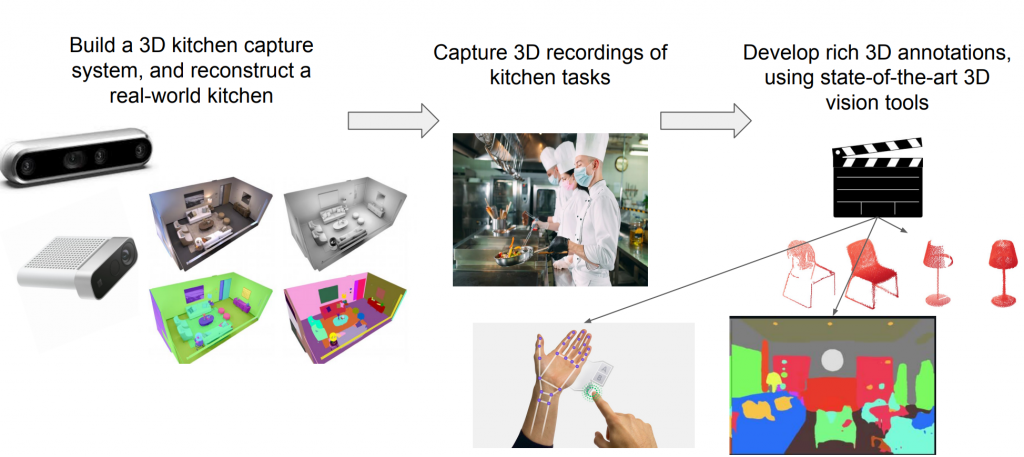
Research Objectives
- Develop a multi-camera 3D kitchen capture system
- Investigate algorithms for human-level annotations like human body pose and hand pose
- Develop an unsupervised 3D scene segmentation algorithm leveraging foundation models
Motivation
Among related datasets on the Internet, we found GMU Kitchen and ScanNet the most relevant to our task of scene understanding; however, none of them have 3D information, human activity, and kitchen environments simultaneously. Therefore, we are building a pipeline to collect our own dataset in a kitchen environment that includes both 3D information and human activities.
| Dataset | 3D Information | Human Activity | Kitchen |
| Epic Kitchen | ✘ | ✔ | ✔ |
| GMU Kitchen | ✔ | ✘ | ✔ |
| MSR Action3D | ✔ | ✔ | ✘ |
| ScanNet | ✔ | ✘ | ✘ |

