
PointPillars:
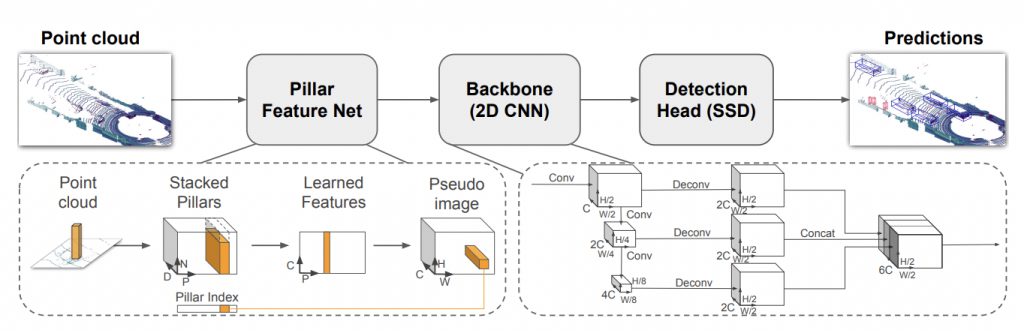
PointPillars is a pioneering object detection system specifically designed for efficiently detecting and localizing objects in 3D point clouds, typically obtained from LiDAR sensors. It operates by transforming the irregularly spaced point cloud data into a structured format to enable precise object recognition. The approach utilizes a two-stage architecture, where the first stage generates preliminary voxel-based representations of the point cloud, and the second stage refines these representations to predict object attributes like position, size, and orientation. Its key strength lies in its ability to achieve high accuracy in object detection while maintaining computational efficiency, making it well-suited for real-time applications in autonomous vehicles and robotics.
One notable aspect of PointPillars is its focus on optimizing both accuracy and speed in 3D object detection. By leveraging a sparse convolutional neural network (CNN) architecture, PointPillars efficiently processes the volumetric data obtained from LiDAR sensors. This approach significantly reduces computational costs compared to traditional dense CNNs, enabling faster inference times without compromising accuracy. Additionally, PointPillars incorporates a novel set of anchor-free prediction heads, allowing it to precisely locate objects in the point cloud without relying on predefined anchor boxes, contributing to its adaptability and robustness across diverse environments.
The effectiveness of PointPillars lies in its ability to handle complex real-world scenarios, including varying object sizes, occlusions, and cluttered environments. Its robustness and accuracy in detecting objects like vehicles, pedestrians, and cyclists in challenging conditions make it a valuable tool for enhancing the perception capabilities of autonomous vehicles, enabling safer navigation and decision-making. Despite its advancements, ongoing research and development efforts continue to refine PointPillars and address challenges related to scalability, further optimizing its performance across different scenarios and sensor configurations.
SOLOv2
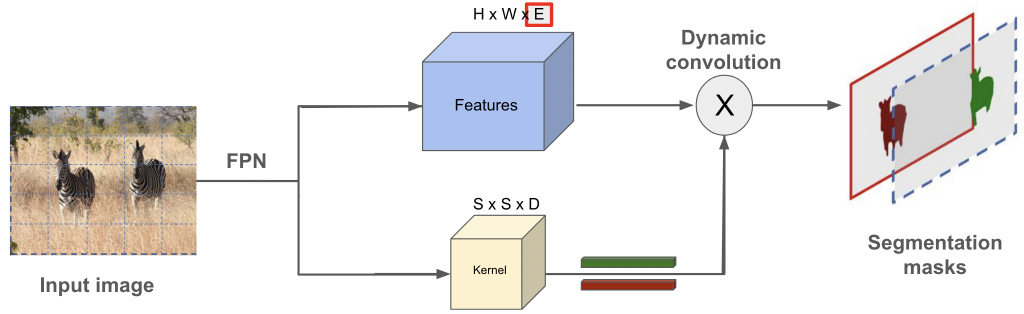
SOLOv2 is a simple, direct, and fast framework for instance segmentation in 2D images. It is empowered by an efficient and holistic instance mask representation scheme, which
dynamically segments each instance in the image, without resorting to bounding
box detection. SOLOv2 significantly reduces the inference time with a novel matrix non-maximum suppression (NMS) technique. The authors propose to learn adaptive and dynamic convolutional kernels for the mask prediction, leading to a much more compact and powerful design, which yields better results.
We propose to use the SOLOv2 architecture for segmenting 2D range image representation of our point clouds. This will ensure that the 3D point cloud segmentation can be done in real time.
References
[1] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
[2] Wang, Xinlong, Rufeng Zhang, Tao Kong, Lei Li, and Chunhua Shen. “Solov2: Dynamic and fast instance segmentation.” Advances in Neural information processing systems 33 (2020): 17721-17732.