
Dataset
First, we collected some images and videos that were downloaded from public repositories or captured by our lab.
The BDD100K dataset is a large and diverse driving video dataset, designed for the development and evaluation of autonomous driving and computer vision systems. It features over 100,000 videos captured in a wide range of weather conditions, times of day, and urban and suburban environments, making it a valuable resource for training and testing robust machine learning models.
The DENSE dataset is a specialized collection designed for enhancing automotive perception systems, particularly in adverse weather conditions. It includes a rich variety of sensor data—such as camera, radar, and lidar—collected under various challenging scenarios like fog, rain, and snow, making it ideal for developing and testing algorithms aimed at improving visibility and reliability in poor weather.
And we have some driving videos that were collected with an iphone or camera under different weather conditions and times of day.
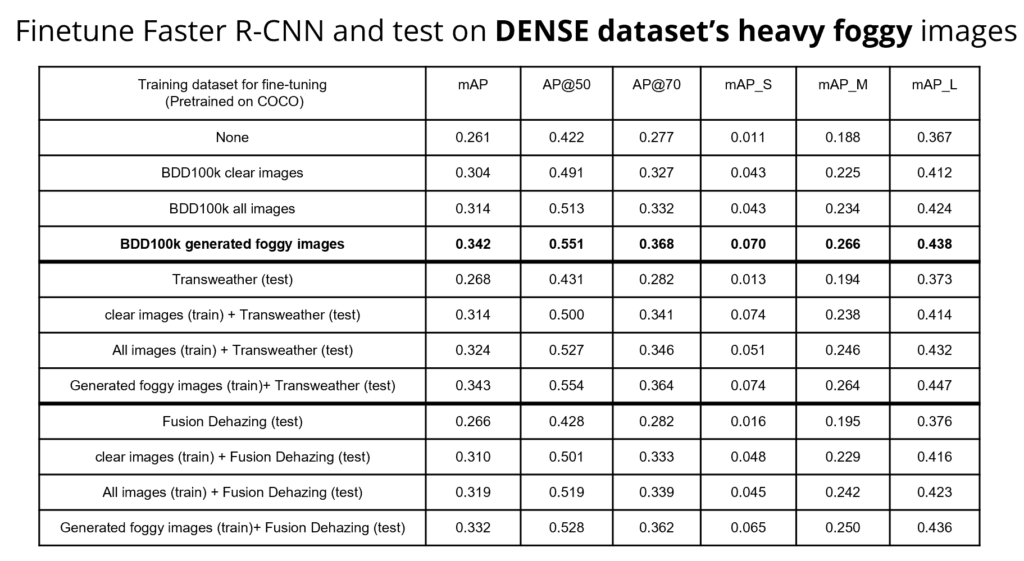
Here are the quantitative results. The experiment using foggy images generated from the BDD 100K dataset to finetune has the best mAP, which means using foggy images to finetune the Faster R-CNN detector can improve the object detection accuracy.
Here are some qualitative results. On the left is the ground truth, the middle is finetuned on clear images, and the right is finetuned on generated foggy images. We can see that after finetuning on generated foggy images, the detector can identify more objects and detect more accurately, while just finetuning on clear images would make some fake detections.

Next, we applied our fine-tuned Faster R-CNN detector to infer trajectories in unlabeled driving videos under foggy conditions.
Since the objects in the video are obscured by fog, it greatly increases the difficulty of detection, and the detector will produce some false detections, which are false positives. We minimize the False Positives by filtering out the trajectories whose lengths are shorter than 20 frames, enhancing the accuracy of our detection.
We also visualize the trajectory in the video. In this graph, each line is a trajectory of a vehicle, and around frame 500, it becomes evident that our fine-tuned detection model enhances the length of trajectories.
To further extend the tracking duration, we employ the bounding boxes from the current frame as region proposals to facilitate backward tracking. This is achieved through the ‘tracking by detection’ method, which is compatible with any two-stage detector.