
This section shows all the progress we made in Fall 2022. Note that since receiving our data, the goals of the project and our method changed significantly in Spring 2022. However, the investigation we carried in Fall helped provide additional context during Spring.
Classical Stereo Depth Estimation
Depth estimation using stereo is a well-researched area and has many different approaches. The classical methods for stereo depth estimation are fairly straightforward and don’t involve any learning or need for data. These methods consist of the following steps:
- Extracting features from both images.
- Construct a cost volume that captures how the left and right feature maps match each other on different disparity levels.
- Using epipolar geometry, calculate disparity from the computed cost volume. (Looking for which disparity has the highest confidence)
The main limitation of the classical stereo methods is that they are limited by the handcrafted features extracted in the first step.
Learning-Based Stereo Depth Estimation
Several different architectures have been proposed for stereo depth estimation using CNNs. PSMNet. Given two images, each image is first fed through the same encoder which creates image features. Then these image features are compared to each other to construct a cost volume where for each pixel there is an associated probability distribution over a set of discrete pixels. Posing this as a classification problem results in issues with sub-pixel disparity errors. Instead, we use a typical regression loss function and try to minimize the error between the weighted sum over the disparities and the ground truth disparity.
Deep Hierarchical Stereo Matching builds on top of PSM net and several other works to focus on specifically improving the performance of high-resolution images. Typical models would suffer from high-resolution images, however, deep HSM addresses these issues by using a coarse-to-fine strategy for depth estimation.
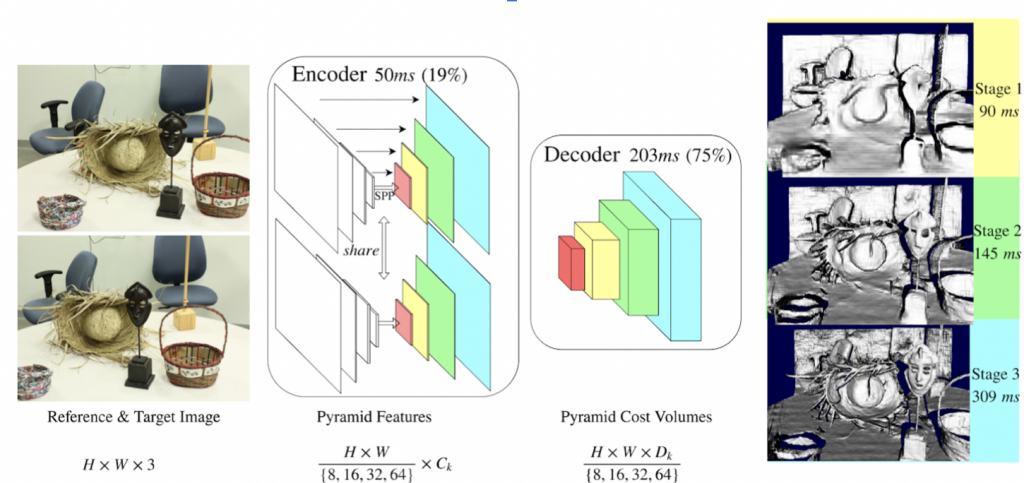
As shown above, deep HSM follows similarly to PSMNet using CNNs to extract image features for each image pair. However, a key difference is that Deep HSM retrieves the features at different resolutions. Each resolution feature map is matched with each other to create a 4D cost volume. In the decoder, 3D convolutions are applied to get a disparity map for the given resolution, as well as a new cost volume to bias the next finer resolution. Overall, Deep HSM is able to perform much better on higher resolution imagery by following this coarse to fine strategy.
Domain Adaptation
One possible solution for low-light stereo is using supervised learning methods trained on low-light/night-time data. However, obtaining proper disparity ground-truth data that is dense and independent of glow or flare is extremely difficult.
Domain Adaptation is the ability to apply an algorithm trained in one or more source domains to a different target domain. In our context, we tried to use this technique to leverage the existing daytime data(along with daytime ground truth) to learn a low-light/night-time stereo model. The primary challenge here is that the input images have some geometric consistency which might not remain when passed individually through domain adaptation networks. In the example below, when converting a stereo pair from synthetic to real, we see that the resulting images have new artifacts introduced that are not consistent:

Our method uses a CycleGAN architecture to change from daytime to nighttime and vice versa. Below is the architecture diagram for this method:
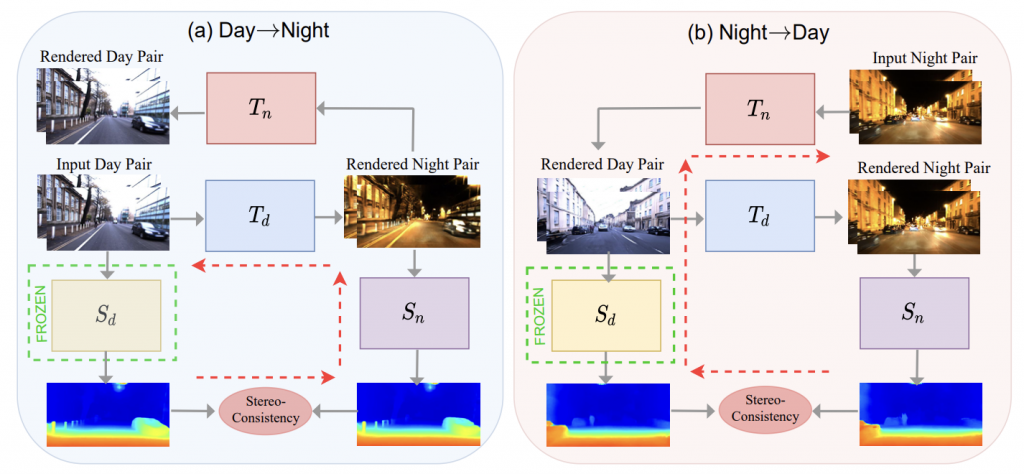
The key contribution of this method is the way in which consistency is maintained in the generated images. This is called the structure-consistency constraint and is enforced by a structure preservation loss. This loss is based on the idea that the features obtained from the input image pair should be similar to those of the rendered image pair. A pre-trained VGG-16 is used to extract these features. Given an input night pair (xnl , xnr) and the corresponding rendered nighttime image (zdl , zdr), we can define the structure preservation loss as,
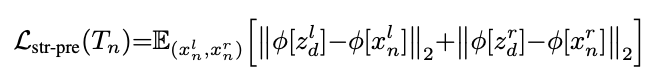
Where 𝜙 denotes the VGG-16 feature extraction function.
Here are a few results obtained from this method:

The limitation of this method is that the domain gap between day and night time images is too huge to be covered by a single model. In cases where the input image is extremely dark, the rendered image is extremely noisy. To overcome this, we considered the use of an intermediate domain to reduce the domain gap.
Thermal Based Stereo
Another modality that we considered using is thermal images. The advantages of using thermal cameras are that are passive and are mostly unaffected by lighting. Thermal data can also be used for domain adaptation as the gap between day and night thermal images is much smaller than the gap between day and night RGB images. We are looking to explore more in this domain next semester.

Stereo Depth Estimation Confidence
Confidence metrics provide additional context to downstream components which can utilize the information to act accordingly. For example, a motion planner may avoid the high uncertainty in a particular region compared to highly-certain regions. We use entropy as one such metric that provides uncertainty information for our predicted disparity map. Specifically, we calculate the entropy of the discrete disparity probability distribution for each pixel.


In addition to entropy, we are also interested in potentially predicting confidence from the model directly. Several works have tackled this problem which has led to an improvement in performance, which we hope to reproduce in the near future.
Datasets
Traditional Stereo Datasets
Due to the difficulty of getting labeled ground truth depth estimates, there are only a limited number of datasets. The most popular ones are KITTI, Middlebury, and ETH3D. However, these datasets are almost entirely focused on daylight with very few low-light environmental conditions.
Oxford Robot Car
Contains a large number of outdoor driving around Oxford at day and night time, as well as various weather conditions.
NREC Collected Data
The above datasets, while may be helpful to some extent, are certainly not in the same domain as the environments for our targeted application. Mainly, our environment contains not just low-light but also off-road environments for which there aren’t any publicly available datasets yet. As such, NREC has collected their own data at various locations that are closer to our actual domain. An example of one such locations during day-time is shown.

Results
Evaluation Metrics
We use standard evaluation metrics listed below from KITTI and Middlebury datasets.
- Average Error – The average error between ground truth disparity and predicted disparity over the entire image and dataset.
- Bad-X Error – The percentage of pixels in the entire image which have an error > X in disparity.
We trained and evaluated Deep HSM on the KITTI dataset. The Deep HSM model was initially trained on a large synthetic dataset, and then fine-tuned on KITTI. Below are the results.
| Distance (meters) | Average Error | Bad-1 % | Bad-4 % |
| 0-25 | 1.245 | 27.1 | 3.5 |
| 25-60 | 1.147 | 27.7 | 3.9 |
| 60-115 | 1.196 | 39.0 | 4.3 |
| 0-115 | 1.231 | 30.4 | 4.1 |
Visualization Results
We showcase the following:
Input Image
Predicted Disparity Map






Entropy
We observe that edges of objects have the highest uncertainty as well as overall there is higher entropy in darker images as shown in the examples below.


References:
- Sharma, A., Heng, L., Cheong, L.-F., & Tan, R. T. (2019). Nighttime Stereo Depth Estimation using Joint Translation-Stereo Learning: Light Effects and Uninformative Regions.
- Song, X., Yang, G., Zhu, X., Zhou, H., Wang, Z., & Shi, J. (2020). AdaStereo: A Simple and Efficient Approach for Adaptive Stereo Matching.
- Vertens, J., Zürn, J., & Burgard, W. (2020). HeatNet: Bridging the Day-Night Domain Gap in Semantic Segmentation with Thermal Images.
- Yang, G., Manela, J., Happold, M., & Ramanan, D. (2019). Hierarchical deep stereo matching on high-resolution images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5515-5524).
- Maddern, W., Pascoe, G., Linegar, C., & Newman, P. (2017). 1 year, 1000 km: The Oxford RobotCar dataset. The International Journal of Robotics Research, 36(1), 3-15.
- D. Scharstein, H. Hirschmüller, Y. Kitajima, G. Krathwohl, N. Nesic, X. Wang, and P. Westling. High-resolution stereo datasets with subpixel-accurate ground truth. In German Conference on Pattern Recognition (GCPR 2014), Münster, Germany, September 2014.
- T. Schöps, J. L. Schönberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, A. Geiger, “A Multi-View Stereo Benchmark with High-Resolution Images and Multi-Camera Videos”, Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- Chang, J. R., & Chen, Y. S. (2018). Pyramid stereo matching network. In Proceedings of the IEEE conference on computer vision and pattern recognition(pp. 5410-5418).
- Zhang, F., Chen, Y., Li, Z., Hong, Z., Liu, J., Ma, F., … & Ding, E. (2019). Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 6798-6807).