Abstract
Object pose estimation is a fundamental requirement for robotic manipulation tasks. Most methods that have high accuracy to be deployed in real-world industrial scenarios depend on known 3D object models like CAD models, etc. While these approaches may be sufficient for certain kinds of industries like manufacturing, these approaches cause bottlenecks in scenarios that deal with objects whose appearance and shape are constantly changing, like in the e-commerce warehouses. This project proposes a mechanism to automate this process of model-free pose estimation. We develop a pipeline that enables the system to learn the shape and appearance of novel objects and identify their poses without manual supervision or datasets.
Data

The input data to the system consists of high-resolution RGB images captured from a top view along with left and right grayscale images captured by a stereo camera setup. Corresponding structured point clouds are also available. Along with these images, the camera intrinsics, and extrinsics are also provided.
Initial Experiments
SD-MRCNN
The first step to identify object poses is to identify individual object instances. We chose Synthetic Depth MaskRCNN (SDMRCNN) as our baseline model to evaluate current SOTA in instance recognition on Mujin dataset. We chose SDMRCNN since it is an MRCNN-based approach that utilizes depth data and classifies the objects in the scene as either foreground (objects) or background (tote/container).
The following images show sample results of SDMRCNN pre-trained on the WISDOM dataset and inferred on Mujin data.




These results clearly show the model failed to identify object instances, and as the object complexity increases (no texture, reflection, transparency), the model completely fails to identify anything at all. Training SDMRCNN on these data samples from Mujin would result in better instance recognition, but that would require creating new datasets for these kinds of objects. However, since the object appearing in the warehouse constantly change, it is not feasible to keep creating new datasets. Therefore, we need a better alternative.
Solution Pipeline
To overcome the issues mentioned above, we propose the following multi-stage pipeline to tackle novel object pose recognition.

For each state of the pipeline, we identify a baseline approach to perform the corresponding task. Once the full pipeline implementation is complete, we then focus on each stage to improve results.
Phase-1

Stage-1: First Pick
The first stage of the pipeline is to pick an object from the tote in a model-free approach. It is a costly (in terms of computing, memory, and time) process to be able to identify and pick an object without knowing the 3D model of the object. However, since this process is going to be performed only once for 1000s of objects that may follow, this costly first step is acceptable.
Since there are existing solutions to perform this task, even on complex objects, (ex: Fully Convolutional GQ-CNN by BerkeleyAutomation), we do not tackle this problem in the current scope of the project and revisit it later once we complete the rest of the pipeline.
Stage-2: 3D Recognition
The goal of this stage is to recognize the 3D representation of the object picked up in stage-1. The resulting 3D model should accurately capture the object’s 3D geometry and textures.
While there are several approaches that can be used to recognize and reconstruct the object’s 3D model, (ex: using a multi-view solution or 3D scans, etc), we use NeRS (jasonyzhang.com) as our baseline approach to generate the 3D model of the object.
NeRS
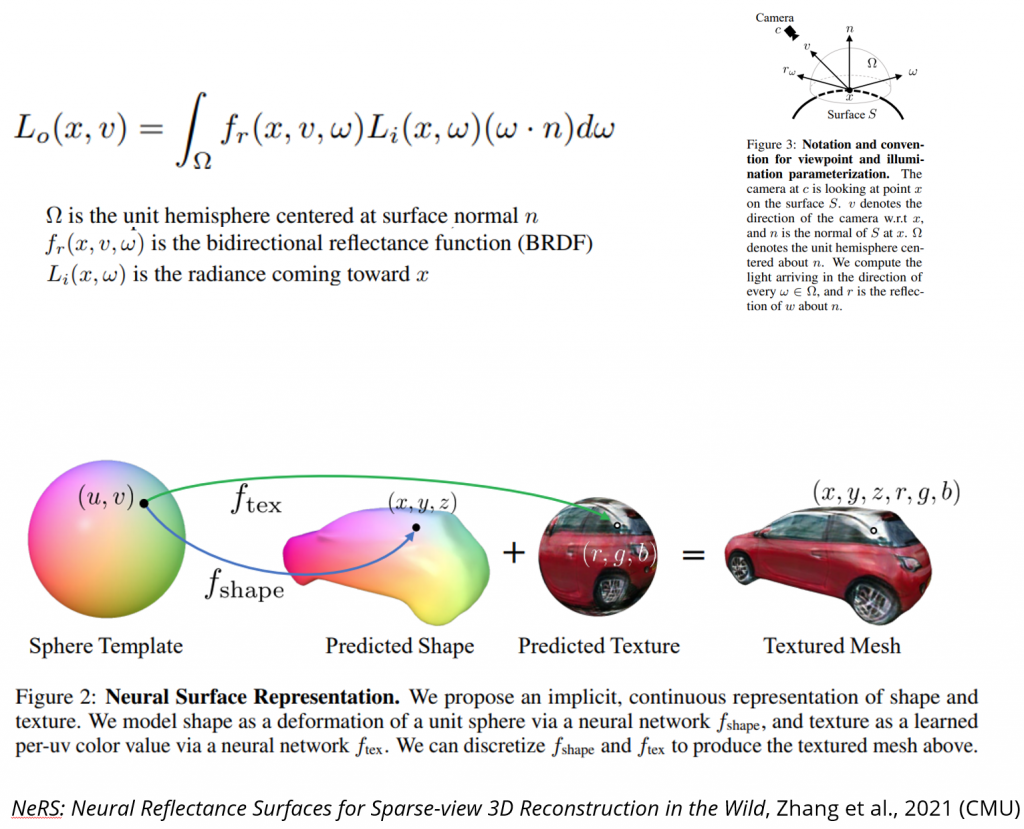
Data
To obtain the initial results (and avoid logistical issues with the camera and robot calibration), we create the input data for NeRS with a handheld object that represents the complexity of objects appearing in Mujin’s warehouse environments. The object masks for these images were created manually for ease of completing the pipeline. This is a trivial task and can be obtained from various automated methods later.
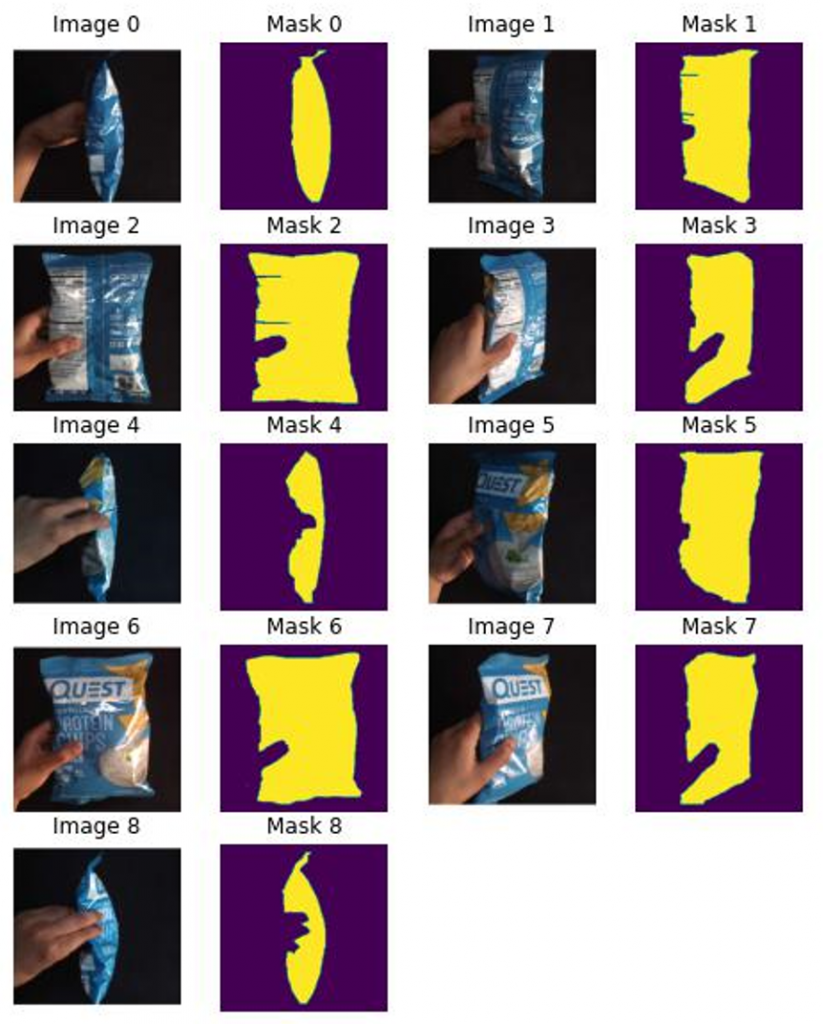
Results


Stage-3: Instance Recognition
In this stage, we generate a instance recognition model that has been fine-tuned on the object picked up in stage-1. We achieve this by generating a instance recognition dataset using the 3D object model from stage-2 and fine-tuning the instance recognition model (SDMRCNN) on this dataset. The resulting model should be able to perform much better than the pre-trained one shown in the initial experiments.
Generating dataset for instance recognition
Naive approach – Generate single instance images from different views of the object. Then overlay and blend these images on a template container image. However, this is not good as the resulting image is not realistic. And blending the depth image of each object instance with a template depth map can lead to incorrect final depth maps.
Alternate & better approach – Use a 3D rendered to render a 3D scene with multiple object meshes inside a template container mesh. The resulting image is more realistic and a custom rasterizer & shader can be used to generate accurate depth maps and object instance masks.
We use this approach and implement it with PyTorch3D as the rendering framework
Prerequisites
- A 3D mesh model of the target object from stage-2
- A 3D mesh model of the template container.
- Scene metadata
- camera settings – FOV, Z-near, Z-far, etc
- Size of the container and distance from the camera
- The relative size of each object w.r.t to the container size
- etc.
Process
- Define a custom rasterizer and shader that can generate object depth maps, masks, and normal textures.
- Place camera and lights at the origin.
- Place a container at a distance ‘z’ oriented towards the camera.
- Instantiate ‘N’ object meshes and apply random rotation transformation to each.
- Identify ‘N’ points inside the container boundary that serves as the center for each of the ‘N’ objects.
- Place each of the ‘N’ objects at these ‘N’ points inside the container.
- Render this scene as seen by the camera using the custom renderer from step1. This generates a single RGB image, depth map, and instance mask.
- Repeat steps 4 to 7 to generate multiple data samples.
- Generate appropriate train-test splits, camera intrinsics, and organize generate data as per the dataset needed for the instance identification model.
Results

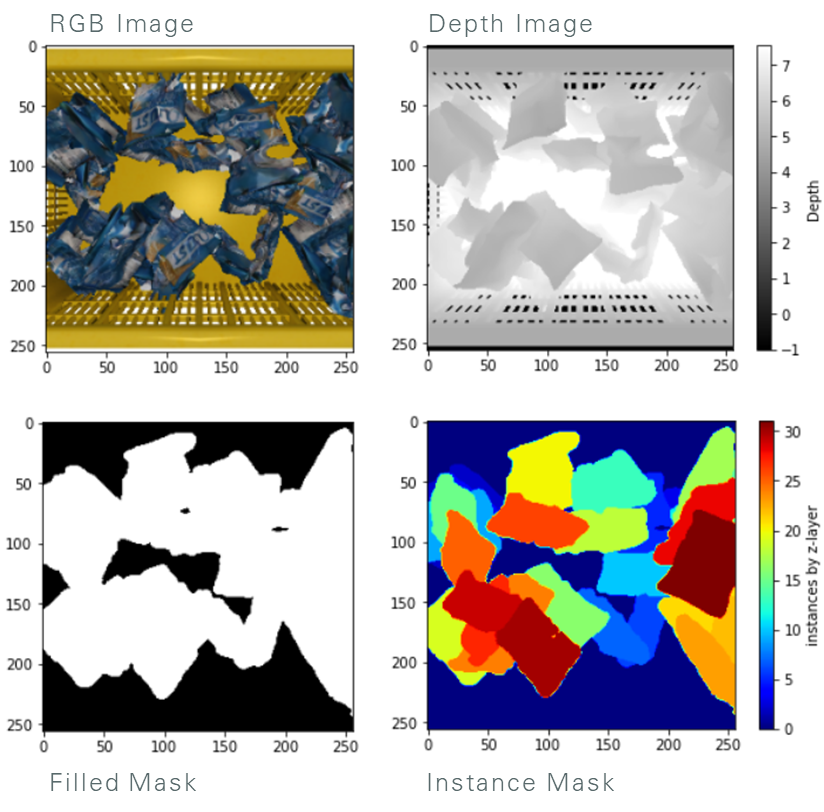

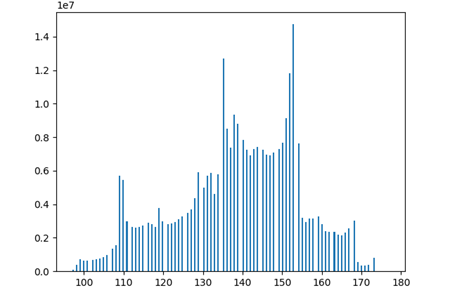
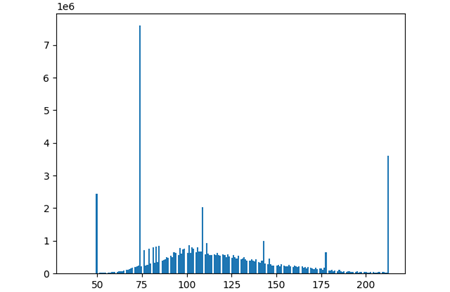
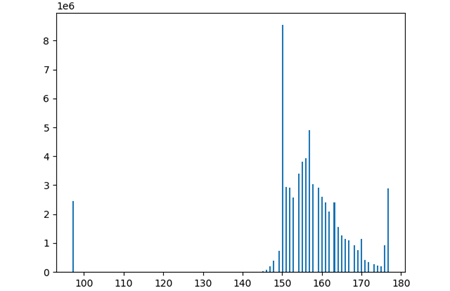
Finetuning Instance Recognition
Once the object dataset is generated, we then finetune our instance recognition model on this dataset. The following results show SDMRCNN recognition on this dataset containing 1000 images with 800 train and 200 test split.
Pretrained: SD-MRCNN obtained from original work implemented in TF and benchmarked in TF
Pytorch SD-MRCNN: Pytorch implementation of the original SD-MRCNN trained from scratch.

However, the results are far from satisfactory. The train-val loss graphs show the model is highly overfitting.
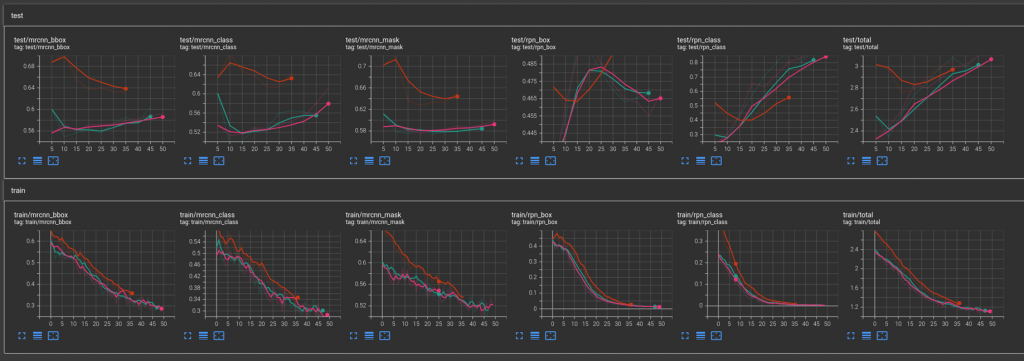
One of the main problems in the generated synthetic data is not realistic. Therefore, in phase-2 of the project, we focus on synthetic data generation to improve instance segmentation, along with revisiting the implementation details of stage-1
Phase-2

Revisiting Stage-1: The First Pick
What is “auto-registration” and “first-pick”?
Mujin’s existing solution for bin picking relies on object registration information to detect object instances first,
then it’s pose, and then finally the best regions of interest for the gripper to pick the object. While this solution
works, it cannot scale to scenarios that require thousands of object SKUs to be registered first and in scenarios where these object’s properties (shape, textures, etc) change over time. These kinds of scenarios forces the need to perform auto-registration of the object at first pick, i.e, when container comes into the cell for the first time, the robot is required to pick the object and perform registration automatically without any manual intervention and the subsequent picks can be performed efficiently using this registered information. To perform this autoregistration, the robot has to initially pick up the object for the first time without any prior information of the object in the container. We refer to this as the first-pick.
Approach
we formulate the problem statement as a task of “Unseen Object Instance Segmentation (UOIS)” – given a single RGBD image object inside a container, the goal is to produce object instance segmentation masks for all the objects inside the container, where the object instances are arbitrary (but belongs to the same semantic class) and are not assumed to have been seen during a training phase.
Relevant Papers
Segmentation with RGB-D
- Unseen Object Instance Segmentation for Robotic Environments (2021) – Introduces UOIS, UNet like baseline arch, late fusion
- Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation (CoRL 2021) – UNet like arch (UCN – improves upon 1), late & early fusion
- Unseen Object Instance Segmentation with Fully Test-time RGB-D Embeddings Adaptation (2022) – UNet like arch (reuses 2), late fusion, improves models at test time
- Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling (ICRA 2022) – MRCNN based arch, late fusion, improves handling occlusions
- Category-agnostic Segmentation for Robotic Grasping (2022) – focuses on how to train with synthetic data, evaluates both MRCNN(4) and UNet(2) like arch, late fusion.
Synthetic Datasets
- BOP Dataset – Benchmark and dataset for object detection and pose estimation
- Nvidia HOPE Dataset – Synthetic dataset of common 3D groceries objects
- DoPose Dataset – Synthetic dataset of common 3D groceries objects inside a container.
- Stillleben – generates a realistic arrangement of rigid bodies to generate synthetic datasets.
Overview
The following solution is derived from the four papers mentioned above (Segmentation with RGB-D). 1 introduces the problem statement task. The main network architecture, training and testing procedures is
derived from 2. Few key ideas from 3, 4, and 5 are also incorporated in the proposed solution.
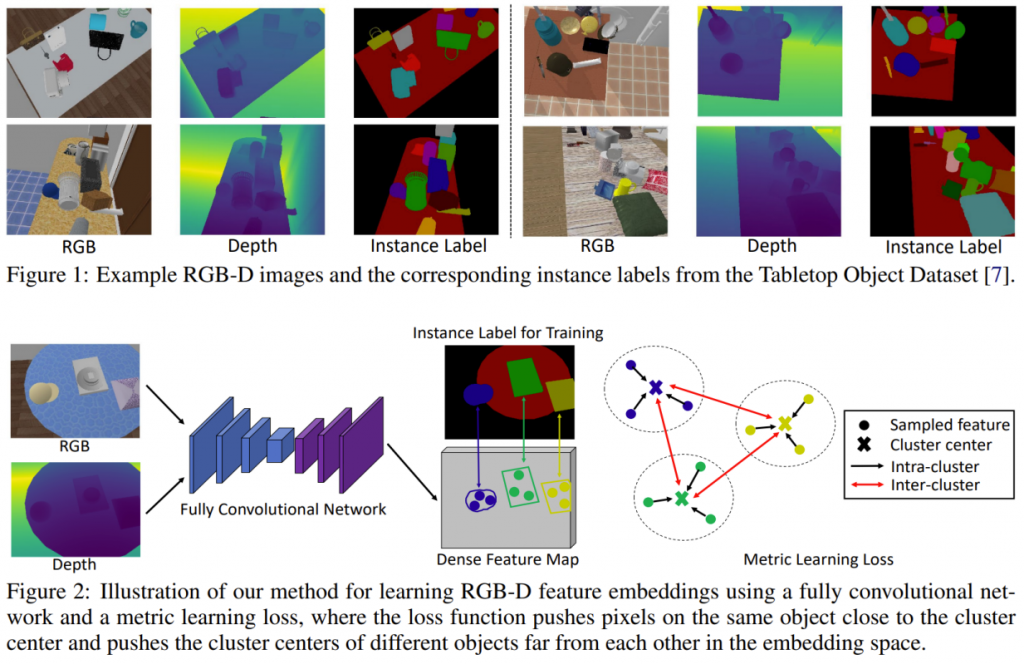
Our FCN here is U-Net like network using a backbone network and a set of deconvolutional layers to generate the dense feature map. Different backbone networks can be used, ex: VGG, ResNet, etc. The paper implementation uses a ResNet-32-8s. We can reuse the same network and backbone for the initial implementation. For our final implementation, we can use the network design from Yolact++, which is a fast segmentation network designed to process images at real time.
Learning RGB-D Feature Embeddings
- Given RGB image (H,W,3) and a depth image (H,W,1), back project the depth image into an organized point cloud (H,W,3) i.e, (x,y,z), using camera calibration params.
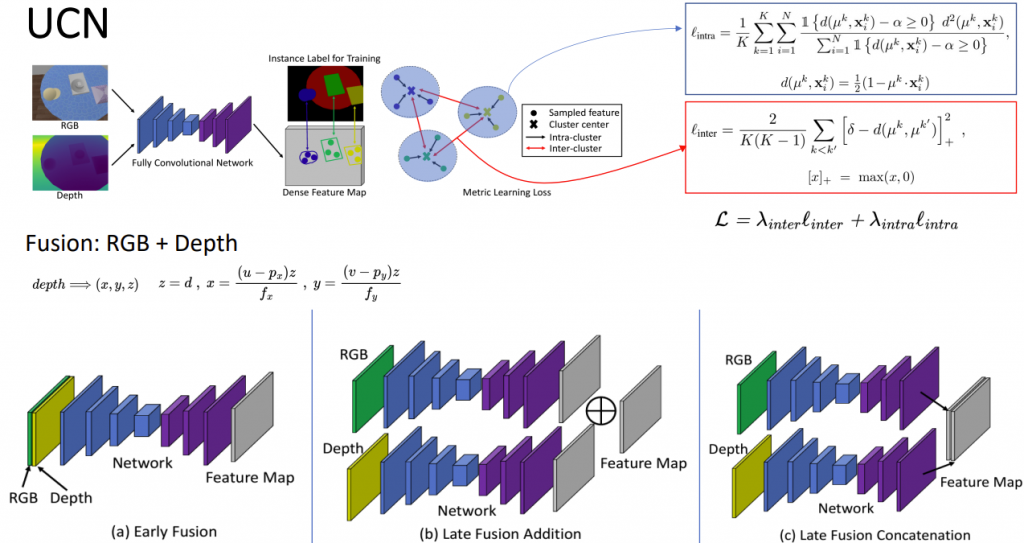
- The FCN takes in the RGB image and point cloud image and generates a dense feature map (H,W,C) where C is the dimension of feature embeddings (as shown below). The FCN for RGB image uses a pretrained backbone weights, whereas the weights for point cloud image backbone is trained from scratch. The two feature maps are combined using an “addition” operation.
- These feature embeddings are normalized to have unit length and a mean shift clustering algorithm is applied to group pixels using this latent space.
- The network is trained with a metric learning loss function that ensure pixels belonging to the same object lie closer to each other and the pixels belonging to other objects are separated farther away. (background is treated is one of the objects)
- Loss = loss_intra + loss_inter
- The final clustering result provides the segmentation masks. These masks are coarse and are refined in the next step.
Segmentation Mask Refinement
For objects lying close to each other, their corresponding pixels may be computed as a single cluster and, therefore, as a single instance mask. To improve such segmentation masks, a second-stage refinement network is employed to specifically handle objects lying close to each other or on top of each other.
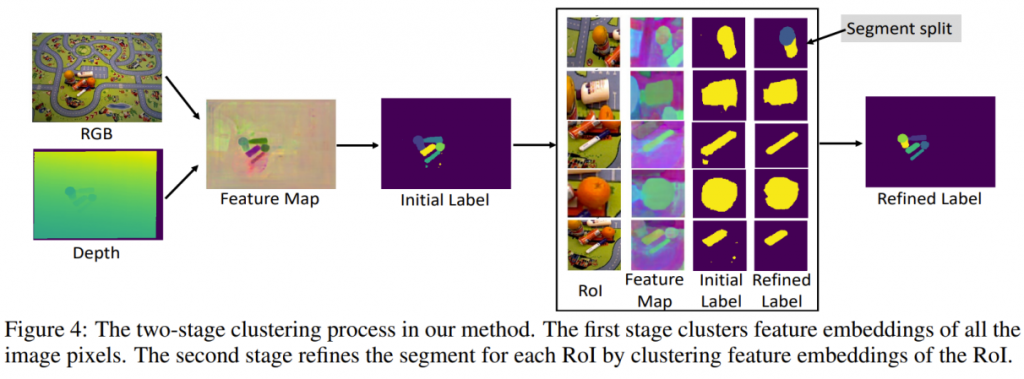
- For each cluster in the feature embedding space, a corresponding RoI is cropped from the RGB-D image.
- A second network is trained on this cropped RoI image, and masks are generated similarly as above.
- If RoI masks contain multiple objects, then only the objects that overlap larger than a predefined threshold with the original mask from stage 1 are retained.
- The final segmentation labels for the whole image are computed by simply aggregating the segments from all ROIs.
Additional Improvements
Once the above method works reliably, the following improvement can be made.
- Amodal instance segmentation masks can be generated by incorporating the ideas mentioned in paper 4
- Better dataset creation and training to improve accuracy can be obtained from paper 5
- Paper 3 provides methods to improve model accuracy at test time on real-world data.
UCN Expectations Vs Reality
The below images show the expected results with the UCN model. The feature map and the generated instance label clearly identify individual object instances.
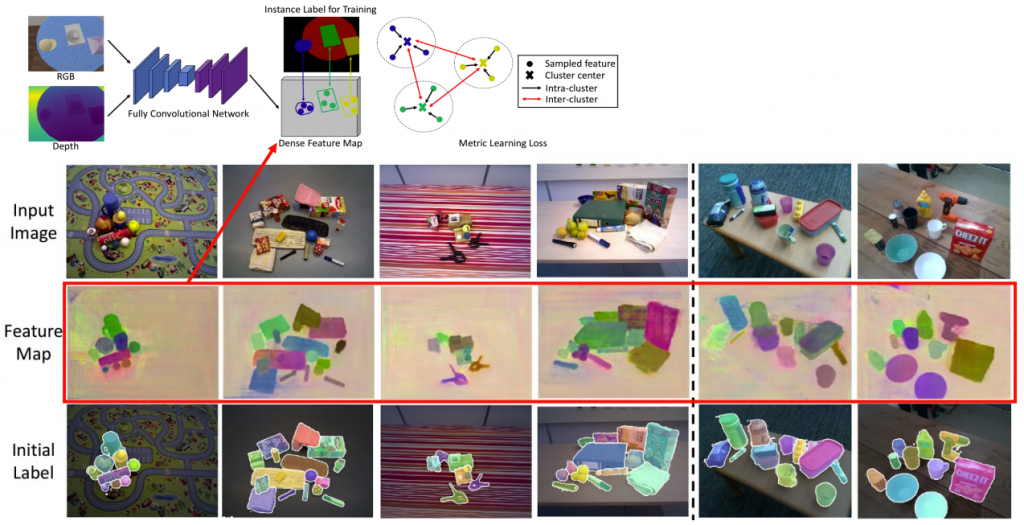
However, UCN results on the real-world Mujin dataset look like the image below.

The pre-trained model does not recognize any object instances. This is expected as the UCN model has never been pre-trained on Mujin data. So the obvious next step is to fine-tune the model on the Mujin dataset and perform inference. However, we do not have any real-world Mujin dataset. This creates a need to have a real-world synthetic dataset. Therefore, we generate a synthetic dataset, fine-tune on this synthetic dataset and then infer it on the Mujin dataset.
Synthetic Datasets Generation
- Papers mentioned in dataset_papers provide all the necessary initial datasets to evaluate the models and also tools to create new synthetic datasets.
- All the datasets in this problem space follow the BOP dataset and benchmark format. BOP dataset also provides a set of scripts using BlenderProc to generate new synthetic datasets.
- NVIDIA HOPE and DoPose provides dataset and 3D models of common groceries object, which we can use to generate more datasets as required.
- These datasets mentioned above are standard public datasets containing multiple SKUs in a single scene. We need to generate our own single SKU synthetic dataset that models our projects.
Object Models
We use BlenderProc to generate our synthetic data following the BOP dataset standard. We use 25 rigid and box-shaped object models of small, medium, big, thin, and long object sizes. Some of the examples are as shown below.




















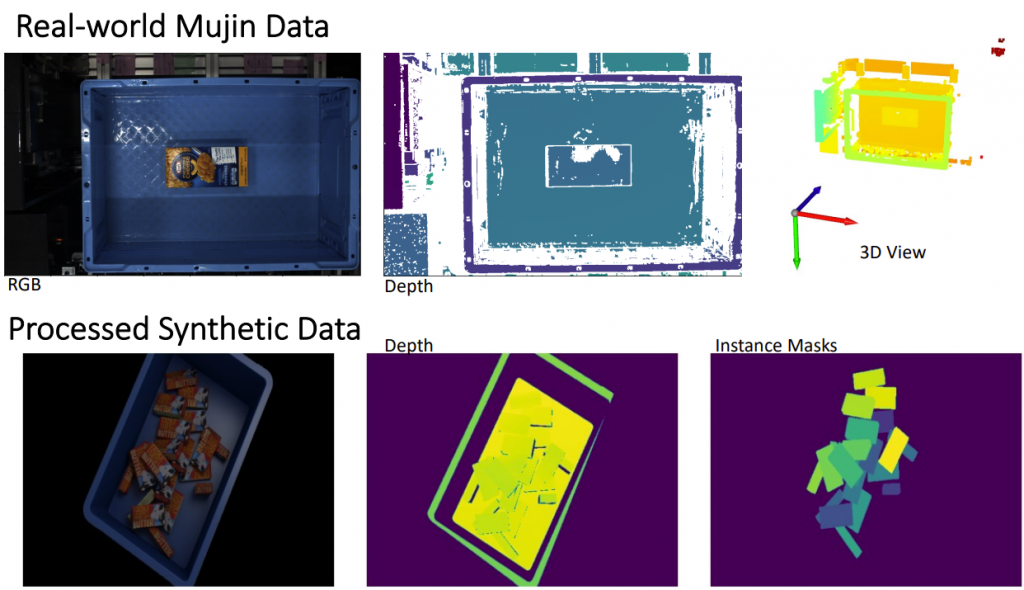
We provide configurable options to select scenes that control the camera, lighting, container, and the object and also select a packing type – ordered, semi-ordered, or random. Our generated dataset comprises of 13500 train set, 1100 validation set, and 3460 test set. Since the real-world data has a lot of noise and holes in the depth data, we post-process the synthetic data to remove surfaces pointing to the viewing camera to mimic the structured light depth sensor and make the synthetic data resemble real-world Mujin data. The resulting dataset sample is shown below.
Our data generation framework is able to generate 25 images at 640×480 resolution with segmentation masks using HDF5 writes in 63.7 seconds. This is a ~45% improvement over the original BlenderProc framework.

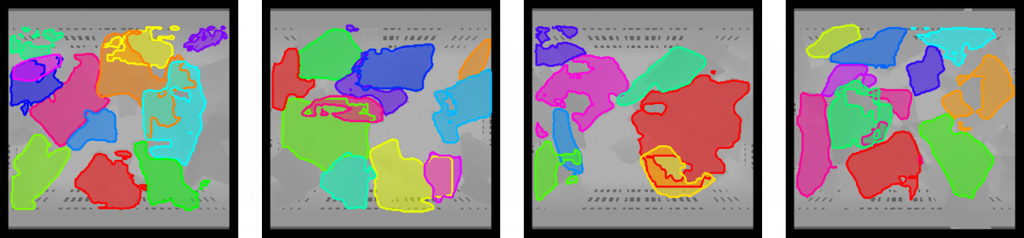
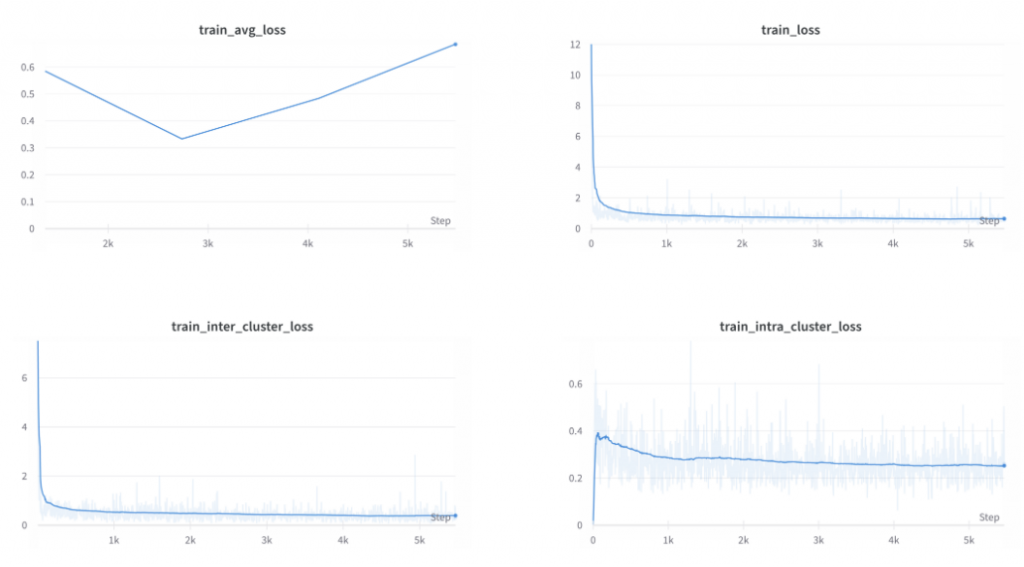
Fine-Tuning UCN
Using the generated dataset, we fine-tune the pre-trained UCN model with 10K train images comprising of 9 object models and evaluate on 3.5K test images comprising 12 unseen models. The train & test sample visualizations are shown below.


As expected, the fine-tuned model works satisfactorily well on the synthetic dataset. Also, we observe the fine-tuned model works reasonably well on the real-world Mujin dataset as well. Here is an example showing the inference result between the fine-tuned and pre-trained model on a sample Mujin data.

Improving fine-tuned UCN
Looking at the feature maps of UCN on Mujin data, we can see a lot of unwanted background activations going on. This can be attributed to the fact that the current loss only penalizes the combined features of the RGB and Depth branches. In some cases, RGB features are better; in some other cases the depth features are better and vice-versa. Therefore, we introduce additional components to the total loss to specifically penalize RGB and depth features. The new total loss now becomes

This results in removing the unwanted background activations, as shown in the same images below


We also analyzed weighted RGB and depth loss, but it doesn’t provide better results. To quantitatively compare these model variants, we compute and analyze these models’ precision, recall, and F1 scores. The below table summarizes the results of these experiments.
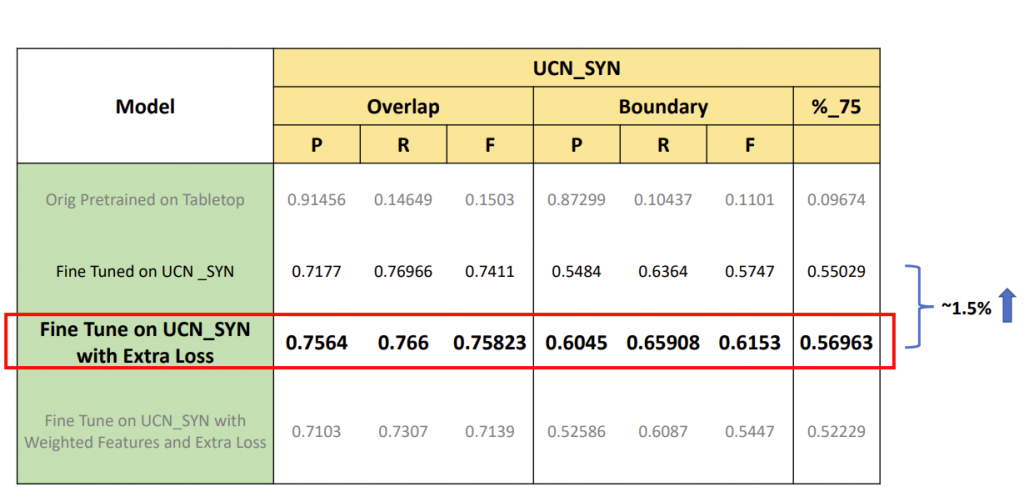
Therefore, we use the UCN model with extra loss as our final model for integrating with Mujin robots.
Integrating with Mujin Robots
The final goal of these tasks is to integrate with the Mujin robots to perform automatic piece-picking of unseen objects in warehouse scenarios. Although we have not focused on stage-4 and stage-5 of the pipeline, we use the existing control & planning infrastructure of Mujin to integrate our UCN model. The existing Mujin pipeline expects a cost volume/affordance map to perform picking. Therefore, we convert the instance segmentation masks provided by UCN into cost maps and input them into the picking pipeline for the robots to pick. An example input and output of UCN in the pipeline is as shown below.

The below visualizations showcases the full pipeline in action, where the robot is able to pick up an unseen object from the container using the detections provided by our fine-tuned UCN model.
https://www.youtube.com/watch?v=nDMNgQCBxmk
