Framework
Basline
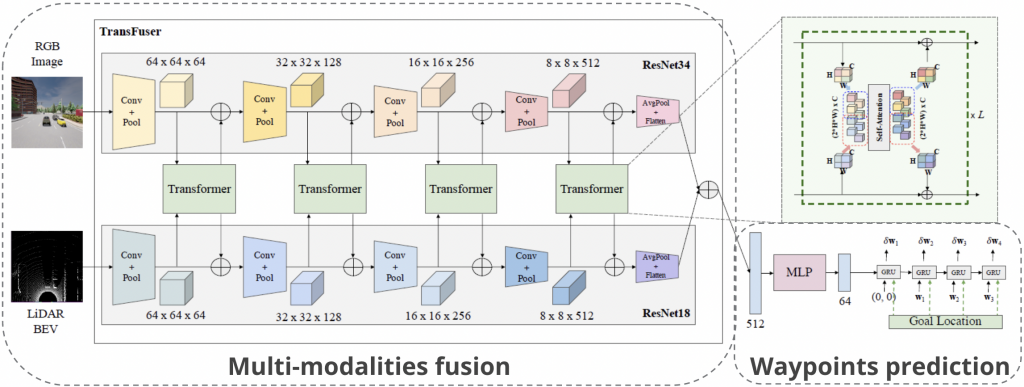
The framework we use is based on the Transfuser [1] model, which contains two parts (1) a Multi-Modal Fusion Transformer for integrating information from multiple modalities (single-view image from the frontal camera and LiDAR in this case), (2) an auto-regressive waypoint prediction network for predicting the discretized future trajectory of the self-driving vehicle.
The supervision of the baseline model is designed as the L1 loss between the predicted waypoints and the ground truth waypoints:
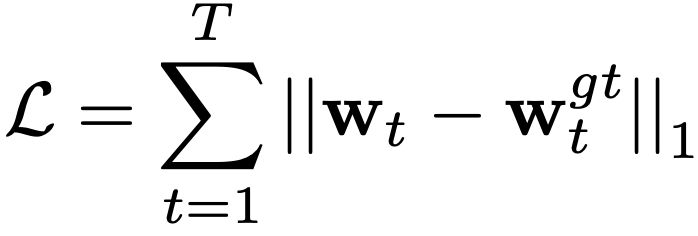
1
Auxiliary Freespace Forecasting Task
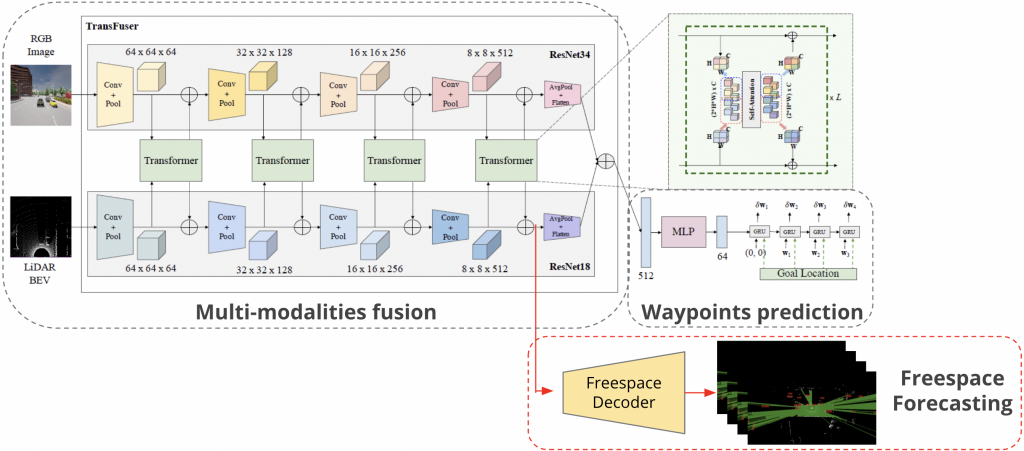
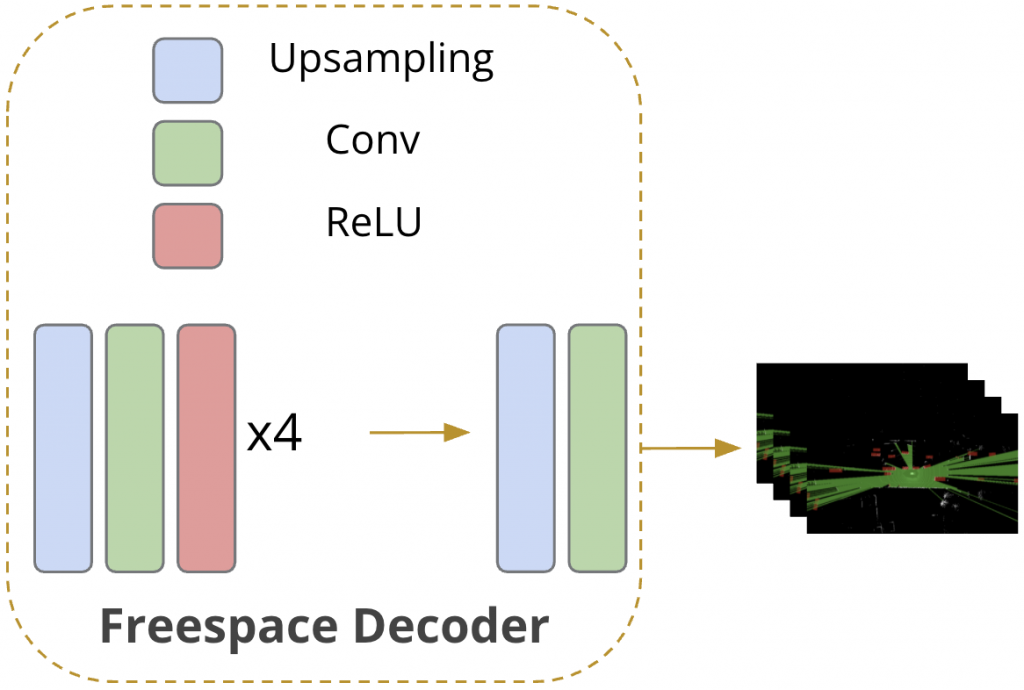
Inspired by [2], we introduced freesapce forecasting as an auxiliary task and designed an additional freespace forecasting decoder (shown in the red block above), using the fused feature from LiDAR branch before the final average polling layer, because the features in this layer are fully extracted and at proper size. The freespace decoder consists of 4 layers of Upsampling-Conv-ReLU combination and another Upsampling-Conv layer (shown in the bottom figure), following simplicity principle in order not to dominate the main waypoints prediction task.
Our intuition behind adding the assistant freespace forecasting task is that, the original loss function, which is a simple waypoints deviation punishment restricting the L1 distance between the ground waypoints and predicted waypoints is too weak. Consider the spareness of the waypoints loss (only several points) compared with the dense RGB and LiDAR input (2D matrix or even 3D tensor if taking history as input). It is highly likely that even if the model learns from ground truth after thousands of epoches, it just learns similar behaviors instead of the reasons behind.
Another reason why we introduced freespace forecasting is becasue it is self-supervised. Given a Bird Eye View LiDAR frame, the freespace can be directly computed by raycasting. Consequently, we do not need expensive human annotations to get ground truth freespace, which makes it convenient to add the task. The following is an example of freespace forecasting centering at the self-driving vehicle, where Red denotes vehicles and Green denotes freespace. The corresponding timestamps from left to right are t, t+1 and t+2.

For freespace forecasting, we use Binary Cross Entropy as supervision, and the total loss is the weighted combination of wapoints prediction loss and the freespace forecasting loss. In our experiments, we set alpha equals to 1.
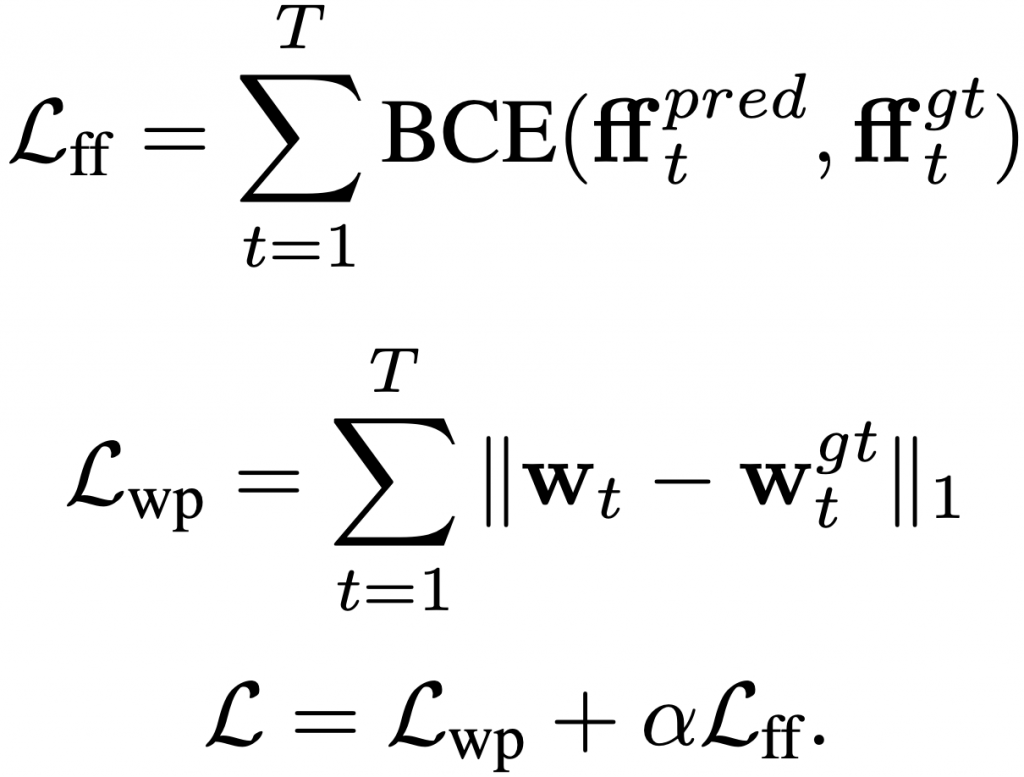
1
Learning to Predict Future Cost Map
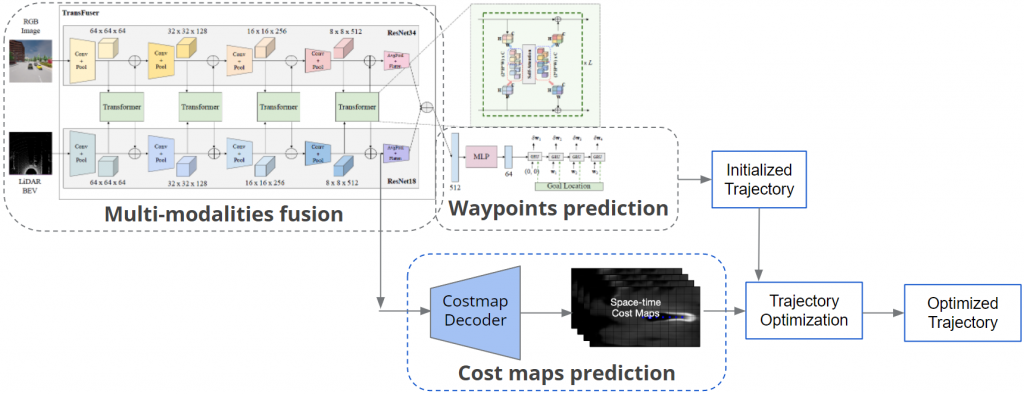
In order to predict cost maps, we introduced costmap decoder (shown in the blue block above), using the fused feature from LiDAR branch before the final average polling layer. The predicted cost maps will be used to optimize the initialized trajectory to obtain the final trajectory.
Cost Map Settings
Waypoint cost maps. Waypoints cost maps cover the area of the correct lane and direction, which aim to guide the vehicle to follow the lane exactly.




Collision cost maps. Collision cost maps refer to all other vehicles and pedestrians, playing the role of collision avoidance.




Traffic sign cost maps. Traffic sign cost maps are defined as an instant rectangle area in front of the self vehicle, indicating the status of the traffic light that is currently affecting the self vehicle.



Reference
[1] Prakash Aditya. Multi-Modal Fusion Transformer for End-to-End Autonomous Driving. CVPR 2021. Link: https://arxiv.org/pdf/2104.09224.pdf
[2]. Hu, Peiyun, et al. “Safe Local Motion Planning with Self-Supervised Freespace Forecasting.” CVPR, 2021. Link: https://openaccess.thecvf.com/content/CVPR2021/papers/Hu_Safe_Local_Motion_Planning_With_Self-Supervised_Freespace_Forecasting_CVPR_2021_paper.pdf