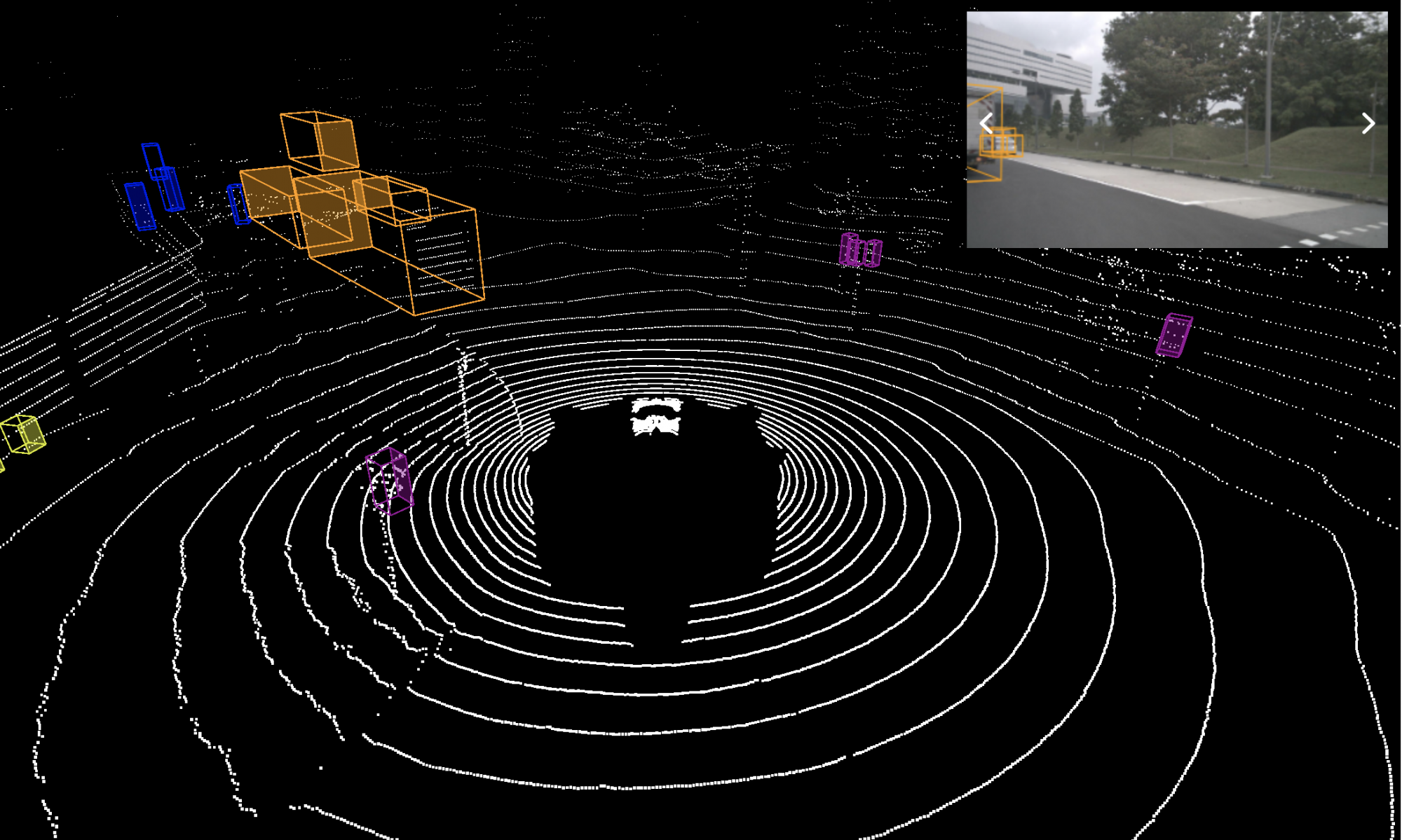
Self-supervised 3D object detection
Object detection in lidar point cloud data is a fundamental component of autonomous driving. As annotation for 3D tasks is hard to obtain, currently publicly available datasets have few hours of data which is arguably not sufficient to train a reliable object detector. At the same time we have a large amount of unannotated data available. The goal of this project is to use self-supervised methods to train or improve the classification and regression branch of an existing object detector. Specifically, for classification branch, we are using the idea that points are more likely to belong to the same object if they are close by and are moving together; they are less likely to belong to the same object if they are farther apart and moving separately. For the regression branch to estimate the orientation, we use the complementary motion information provided by the scene flow output by a self-supervised scene flow model
Advisor: Prof. David Held
Sponsor: Argo AI
Project Description and Methods
Methods for the classification branch
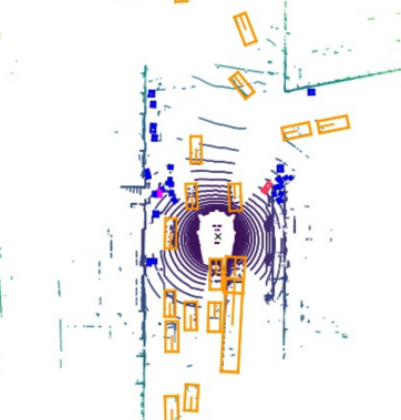
Clustering to generate pseudo ground truth
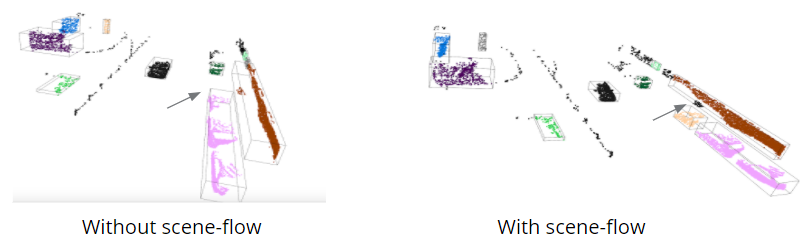
We cluster the points using its xyz coordinates as well as the scene flow vectors (treated as the motion of a point). By particularly tuning the parameters, we can get a better clustering result than just using the xyz coordinates (say now we can deal with the case when two objects are near each other but have different motion, as the figure below shows).
Evaluate a metric for each given anchor
We think that if a group of points moving together, then they tend to belong to the same object. This means that we should penalize the case when the sceneflow vectors in a given anchor box are not consistent. The concept is illustrated in the figure below.
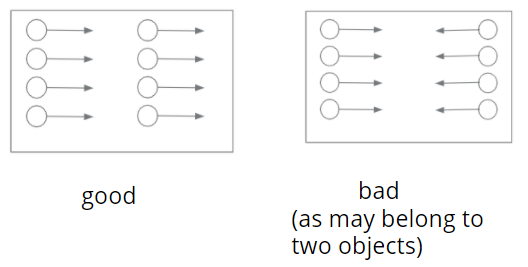
Based on this philosophical idea, we propse a variance metric to evaluate the variance of motion vectors (scene flow vectors) of points within a given anchor box, as shown in the figure below.
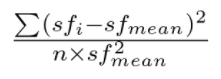
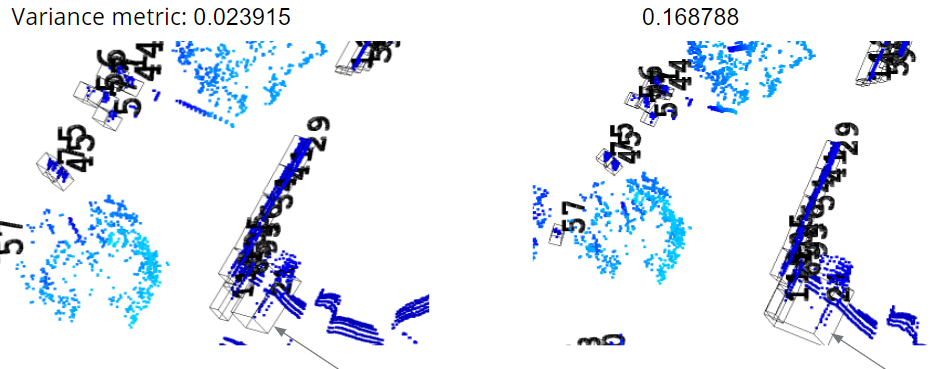
We validate this metric on some hand-manipulated cases. In the figure blow, we choose a moving ground truth bbox that is close to static bbox. We double its size and make a shift for its center location so that after this manipulation, this anchor box also include the points in another static bbox. We evaluate the variance metric for this case before and after manipulation, and find that the variance metric after is higher than before, which validates our idea.
After we have this metric for each anchor box, we can train the classification branch either using policy gradient methods or using some representation learning methods (although we switch gears to another direction later and did not finish this part).
Methods for the regression branch
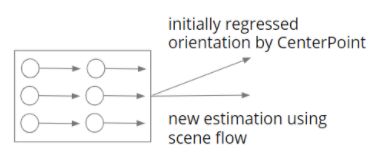
The idea to improve the orientation estimation is embarrassingly simple. We have an initial estimation that is regressed by a 3D object detector say CenterPoint. We have an estimation from the scene flow (the average of the flow vector). At test time, if we are confident about the estimation from scene flow, we directly replace the initial estimation with this one. The concept figure is as below.
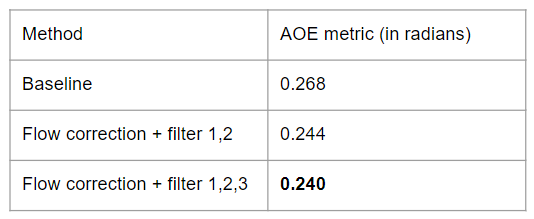
For evaluation metrics, we use the Average Orientation Error, one of the True Positive metrics in nuScenes dataset, since the mAP metric in nuScenes does not account for the orientation, and only rely on the center of a predicted bbox.
In order to filter out the “reliable” scene flow vector, we use several filters: we get rid of the case when there are few points in a bbox, when it is a static object (the norm of average flow vector is small), when the variance of the scene flow vectors within a bbox is large.
In the end, we get an improvement on the orientation on the remaining bboxs, as shown in the table below.
Self-supervised Shape completion
When navigating in urban environments, many of the objects that we need to track and avoid are heavily occluded. Planning and tracking using these partial scans can be quite inaccurate. The aim of this work is to complete these partial point clouds, giving us a full understanding of the object’s geometry using only partial and noisy observations. Previous methods achieve this with the help of complete, ground-truth annotations of the target objects, which are available only for simulated datasets. However, such ground truth is unavailable for diverse, real-world LiDAR data. In this work, we present a self-supervised point cloud completion algorithm, which is trained only on partial scans without assuming access to complete, ground-truth object model annotations. Our method achieves this via inpainting.
This work was done in collaboration with Himangi Mittal and Brian Okorn at RPAD Lab, CMU.
Architecture
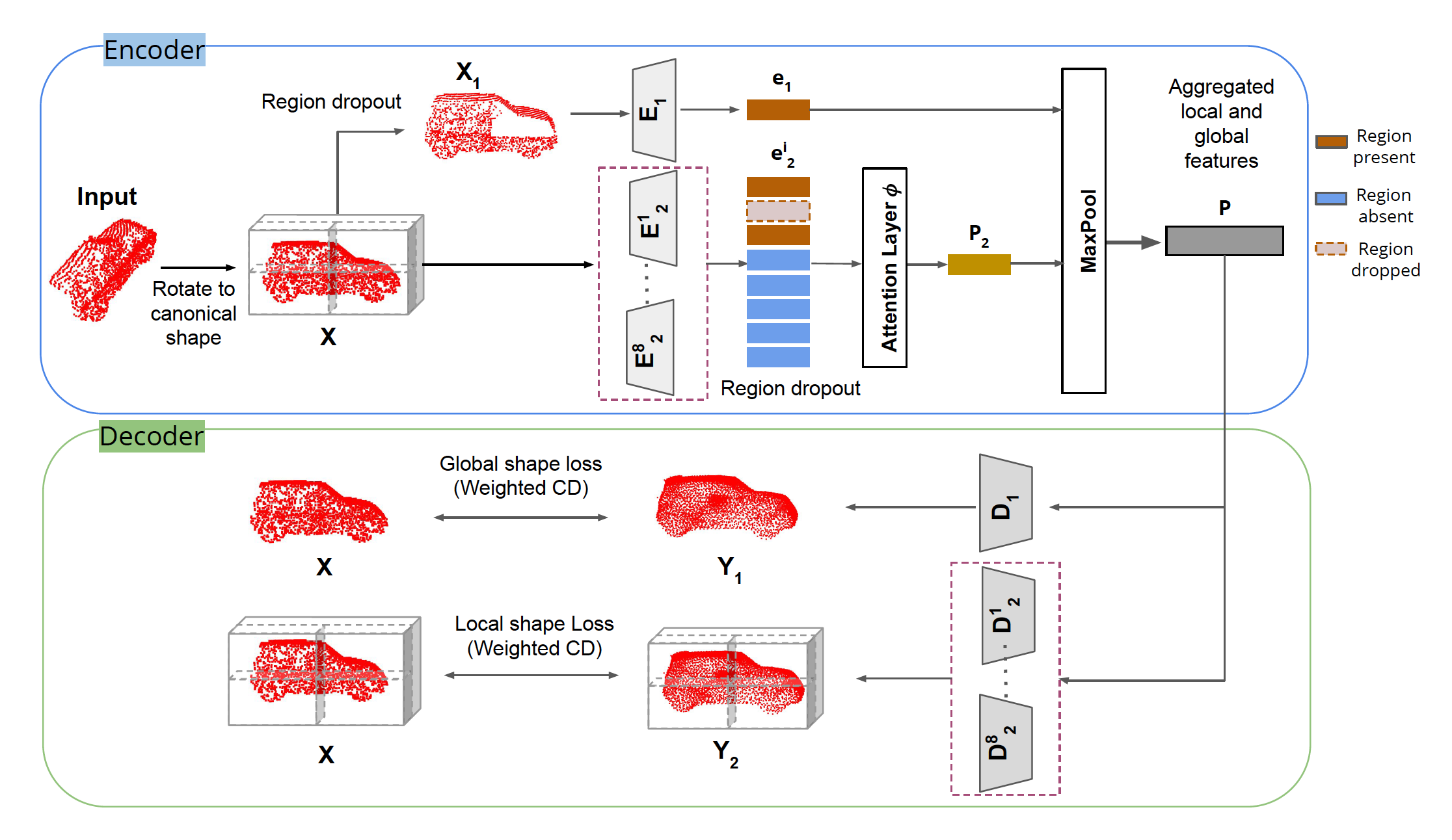
In summary:
1. A novel inpainting-based self-supervised algorithm that enables the network to learn to fill missing local regions in an incomplete point cloud without the need for a ground-truth complete point cloud.
2. Multi-scale encoder-decoder based architecture, partitions the canonicalized point clouds to learn a combination of local and global shape priors to reduce overfitting and better generalize to unseen point clouds.
3. The approach outperforms existing methods for self-supervised point cloud completion when evaluated on the ShapeNet and SemanticKITTI datasets.