Project Motivation & Description:
The problem and motivation stems from the fact that there is a need for high resolution depth, which can be used in applications such as SLAM,AR, etc. however, most RGB-D sensor provide with a high-resolution RGB Image and a low-resolution depth image. While High resolution RGB is easily accessible, getting high resolution depth remains a hard problem. Moreover, the high-resolution RGB image does have a lot of structural information which we can use to refine the low-resolution depth to obtain a high resolution depth image. Thus our problem statement is to estimate high res depth through guidance from RGB.
While we are attempting to solve RGB Guided Depth Super Resolution, we shift the research towards general super resolution and present interesting findings that provide a better understanding of the Super Resolution process, and at the same time can be extended to RGB Guided Depth Super-Resolution.
We focus on a novel way to recover the high-res depth image in an unsupervised way by exploiting properties of Convolutional Neural Networks and Natural Image statistics.
Proposed Solution:
Super resolution is an inverse problem – and the objective being to recover the high-resolution (good) image from the low-resolution (bad) image. At the same time, there is a paired relationship between the bad and good image, and an easy way is to apply Supervised Learning in order to learn the mapping from low-res (data) images to high-res (labels) images. However, supervised learning itself draws into dataset bias, heavily reliant on the type of data, etc, which restricts its generalizability. Another way to view this problem is to view it as a traditionally black box optimization problem, where you have 2 terms to optimize, : a data term (penalty) and a regularization, which generally captures the prior . The benefit of this method is it doesn’t rely on the High resolution pairs, that one would need during supervised learning, but at the same time it ignores all the advantages and power of deep networks.
Towards the best of both the aforementioned methods, we can formulate a self-supervised method that uses a learnable CNN (taking advantage of deep learning) but at the same time derive as much self-supervision from the low-resolution image. So basically the optimization becomes a self-supervised learning process, where our High-resolution image is parameterized by the weights of the CNN
Capturing the prior & Towards Super-Resolution
It was later argued in the paper form Dmitry Ulyanov et.al (Deep Image Prior, CVPR 2018), that in the above formulation, there is no need for an explicit regularization. The structure of a CNN can offer implicit regularization . (see slides for the explanation of this regularization) . We use this property of the CNN for formulating the super-resolution problem as a self-supervised learning problem (with only implicit CNN regularization )
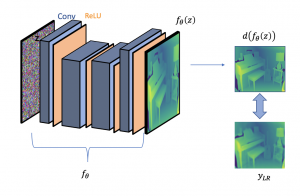
RGB Conditioned Depth-SR
While using Deep Image Prior, we set the input tensor as a random input tensor sampled form a normal distribution. The network then iteratively regresses to form the good / High-resolution depth map. This enables to super-resolve the depth map, but we are still not incorporating the structural information from the RGB Image (which is high-res)
To infuse structure from the RGB, we then try to incorporate edge aware losses in the loss function : however there is a fundamental drawback : i.e. that RGB edges comprise of depth edges as well as texture edges, whereas we want to supervise it with depth edges only.
Next, we can try to force the DIP network to output RGB + D , this enforcing structural supervision through RGB : however, this leads to the texture copy artifacts in the depth image, thus making the depth image incorrect.
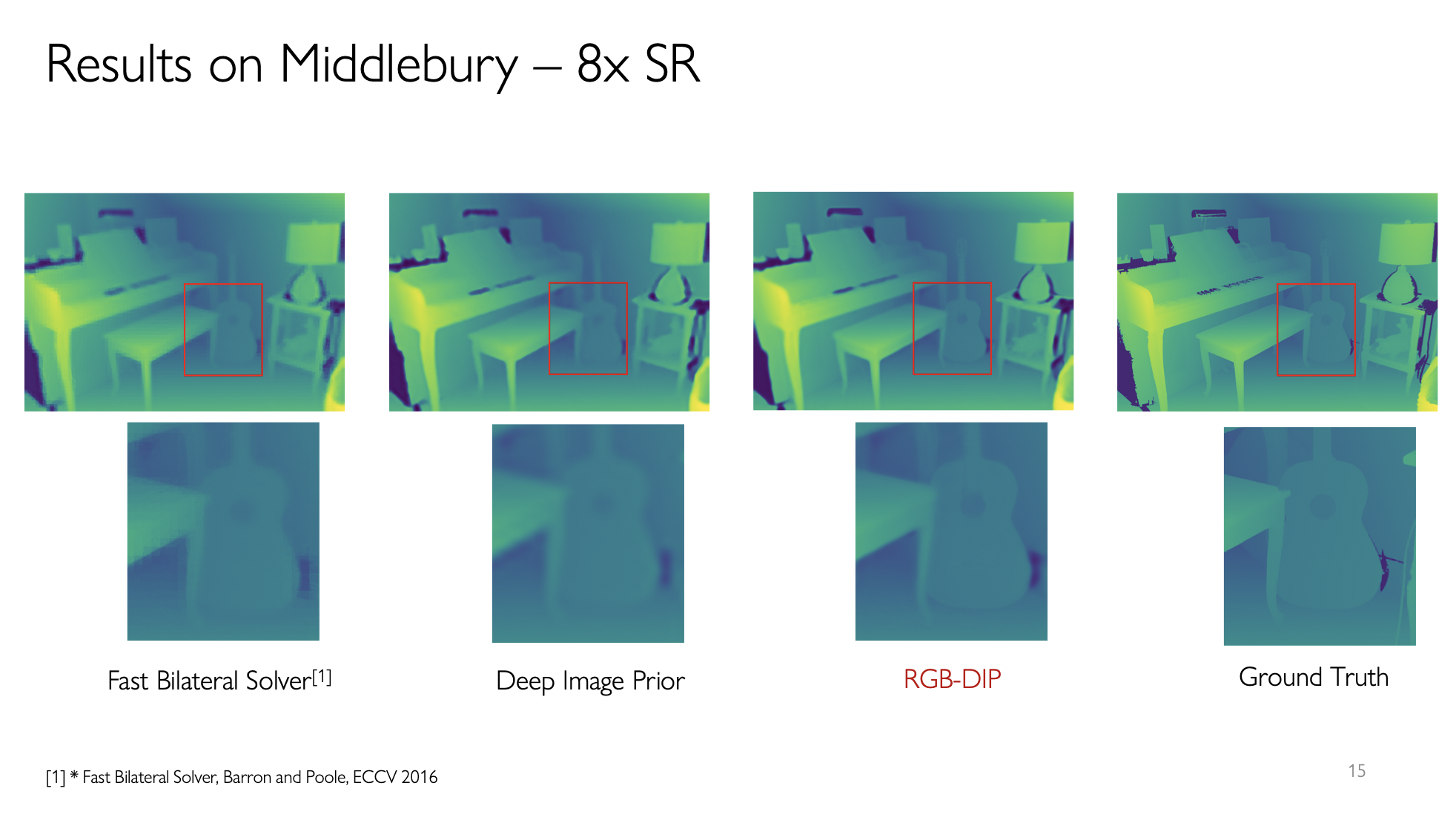
Lastly, we see that setting the input to the RGB image itself instead of the random tensor, works well. RGB as an input infuses the structural information through the CNN , thereby conditioning the Depth Super Resolution on RGB itself.
Results