
- Introduction
We’re trying to build realistic human models for virtual reality. The goal is to build human body models from multi-view RGB images given camera parameters, with highest possible level of detail. The high quality human we reconstruct may help overcome the uncanny valley problem, and eventually enable the next generation of gaming and social applications in VR context.
- Device and Setting
There are more than one hundred cameras, all of 4K resolution, half of which are colored and the other half are grayscale. All cameras are pre-calibrated. The subject being captured is inside a capture room with static background.


On the left is an image of our capture room. All the black dots are cameras. On the right is a showcase of a standard capture setup, with a subject standing inside the room.
- Pipeline
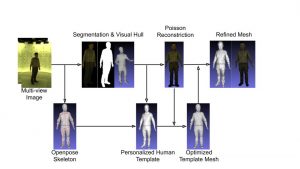
The pipeline consists of several components. First, dense multi-view reconstruction is performed on all the images captured. We perform foreground segmentation for each image to acquire a high-resolution human mask, which builds a visual hull that constraints the reconstruction. After that, a parametrized, personalized human template mesh will be optimized to fit its shape and pose to the reconstructed mesh. This involves an optimization process developed by us, including several loss terms which will be introduced later. Finally, some additional optimization will be applied to the human template, which further improves the level of details.
- High-Resolution Foreground Segmentation
In order to deal with all the difficulty induced by shadow, color confusion and grayscale images, we developed an end-to-end encoder-decoder network for high-resolution human foreground segmentation. We trained this network with synthetic data and it’s able to generate masks with pixel-level accuracy regardless of color or grayscale. Checkout the detailed structure in our slides. Here are some example results:


- MVS and Poisson Reconstruction
Standard multi-view stereo reconstruction only gives us a pointcloud. We use Poisson reconstruction to turn that into a mesh. In this process we leverage a visual hull generated by the segmentation masks to improve the result mesh: outlier points with wrong normals can be filtered out. This is implemented by inspecting the indicator oct-tree nodes. Here are some examples of colored Poisson reconstruction mesh.



- Fitting Personalized and Parametrized Body Template
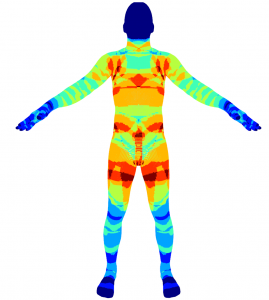
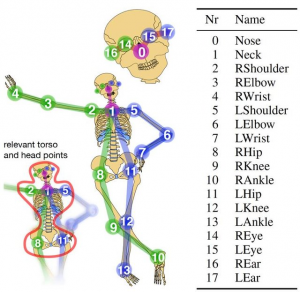
In this step we optimize the pose and shape parameters of a personalized body template to fit it closely with the reconstructed mesh. The template mesh uses linear blend skinning model to model how the skeleton affects surface shape. There is a kinematic chain as shown in the figure below. We also demonstrate a visualization of the human-designed skinning weights.
Here is an example of a reconstructed mesh and the fitted mesh.


- Further Refinements
There are two additional refinement steps after fitting the parametrized body mesh. The first one is called local blendshape model. The body mesh is divided into a large number of small patches, each of which has its own blendshape model and parameters. The second one is per-vertex deformation, where each vertex will have a 3-vector assigned to it to further model the finest surface deformation. Here we show the comparison with and without these refinements.


- Results


A video example:
https://drive.google.com/file/d/1DRDD-aDxc1NHQz9e09BxA6yzq_s0F0H1/view?usp=sharing