Proposed Model Architecture
To address the challenges of multi-agent motion prediction under occlusion, complex interactions, and rare traffic-rule scenarios, we propose a vision–language–augmented, multi-modal architecture that jointly reasons over scene dynamics and traffic semantics. The model integrates agent history, inter-agent relationships, camera and LiDAR perception, and HD-map context, while explicitly incorporating traffic-rule knowledge distilled from a vision–language model (VLM). Unlike conventional approaches that rely solely on trajectory patterns or visual cues, our design introduces rule-aware reasoning as a first-class signal, enabling safer, more interpretable, and legally consistent trajectory prediction in ambiguous driving situations.

Figure1. Model Architecture
As illustrated in the figure, the architecture consists of three main components. First, a Scene Encoder processes multi-modal inputs—including agent states, agent interactions, camera images, LiDAR point clouds, and map features—using modality-specific encoders followed by cross-modal attention to produce unified scene embeddings for all agents. In parallel, a Traffic-Rule-Aware Encoder renders the transportation context into BEV maps and leverages a teacher VLM to extract high-level semantic signals (intentions, affordances, scenarios, and traffic rules), which are distilled into a lightweight student model for efficient inference. These scene and rule embeddings are then fused via dual attention and passed to an autoregressive Transformer decoder, which jointly predicts future trajectories for all agents. This modular design enables the model to capture interaction-aware motion dynamics while enforcing rule-compliant behavior, even when critical cues are visually occluded or underrepresented in the training data.
Input Data and Scene Encoder
The Scene Encoder takes multi-modal input data—including agent state history, lane centerlines from HD maps, traffic light signals, agent–agent interactions, and ego-centric camera and LiDAR observations—and projects all modalities into a unified embedding space. Each modality is encoded independently using modality-specific attention encoders, after which cross-modal self-attention is applied to fuse spatial and semantic information across agents and sensors. This fusion produces a unified scene representation that captures both global scene context and local inter-agent dynamics. The resulting scene embedding has shape (R,N,L,H), where R denotes the number of rollouts, N the number of agents, L the temporal sequence length, and H the hidden dimension.
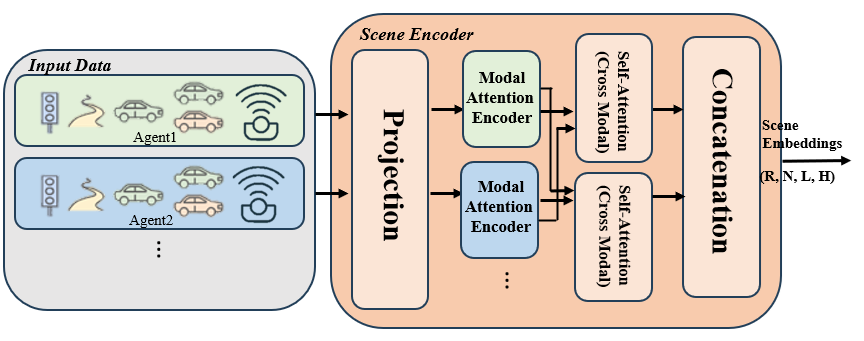
Figure 2. Input Data and Scene Encoder
Agent State History
Encodes past positions, velocities, and headings of each agent, providing temporal cues about motion trends, maneuver intent (e.g., turning or braking), and short-term dynamics.
Lane Centerlines (HD Maps)
Provide high-definition lane geometry and topology, helping align predicted trajectories with drivable space and enforcing structural constraints of the road layout.
Traffic Light Signals
Encode the spatial location of nearby traffic lights, supplying critical information about motion legality and right-of-way at intersections.
Agent Interactions
Capture relative positions, velocities, and headings between nearby agents, enabling the model to reason about interactions such as yielding, following, merging, and cut-ins.
Camera Images
Offer rich semantic information—including lanes, traffic signs, pedestrians, and road markings—that is essential for understanding scene context and visual affordances.
LiDAR Point Clouds
Provide precise 3D geometry and distance measurements, complementing camera perception and remaining robust under challenging lighting or weather conditions.
Traffic-Rule-Aware Encoder
The Traffic-Rule-Aware Encoder is designed to explicitly inject traffic-rule semantics into multi-agent motion prediction. Given the input scene, we extract rule-relevant spatial context—including agent positions, lane geometry, traffic lights, crosswalks, and intersection layouts—and rasterize it into a structured bird’s-eye-view (BEV) representation. This BEV map is paired with a carefully constructed prompt that includes auto-generated scene descriptions, predefined semantic categories, traffic-rule definitions, and a strict output format, augmented with few-shot examples to ensure consistent reasoning. The prompt–BEV pair is fed into a teacher vision–language model (Qwen2.5-VL), which performs high-level reasoning to infer traffic semantics that are not always directly observable from raw sensor inputs.
To enable efficient inference, the teacher VLM’s outputs are distilled into a lightweight student model that predicts structured traffic-rule embeddings without querying the VLM at test time. The student is trained using Binary Cross-Entropy (BCE) losses against predefined ground-truth labels, producing interpretable and temporally aligned rule embeddings with shape (R,N,L,D), where R is the number of rollouts, N the number of agents, L the sequence length, and D the total embedding dimension. These traffic-rule-aware embeddings are later fused with scene embeddings via dual attention, enabling the decoder to generate trajectories that are both interaction-consistent and legally compliant, even under occlusion or rare traffic scenarios.
IASR Embedding Definition
- Intentions (I): Encode the agent’s intended maneuver (e.g., go straight, turn left/right, stop, lane change) as a weighted one-hot vector in , capturing high-level motion intent beyond short-term kinematics.
- Affordances (A): Represent the legality or feasibility of possible actions (e.g., can turn left, must stop, must yield to oncoming traffic) as a binary vector in, reflecting actionable constraints imposed by traffic rules and scene context.
- Scenario Types (S): Describe the high-level traffic scenario (e.g., straight road, signalized intersection, stop-controlled intersection, pedestrian crossing, merge area) as a binary vector in, providing global contextual grounding.
- Rules (R): Explicitly encode applicable traffic rules (e.g., stop line ahead, crosswalk ahead, through-lane priority, no stopping in lane) as a binary vector in, enabling interpretable rule enforcement during prediction.
The overall IASR loss is defined as:

This enables the model to align predicted traffic-rule embeddings with structured, interpretable ground truth labels.
Vision-Language Model (VLM)
- Receives prompt and BEV rendered maps.
- Trained using Binary Cross-Entropy Loss to match GT-IAS labels from teacher VLM Qwen2.5VL model.
- Outputs legal-aware traffic embeddings.
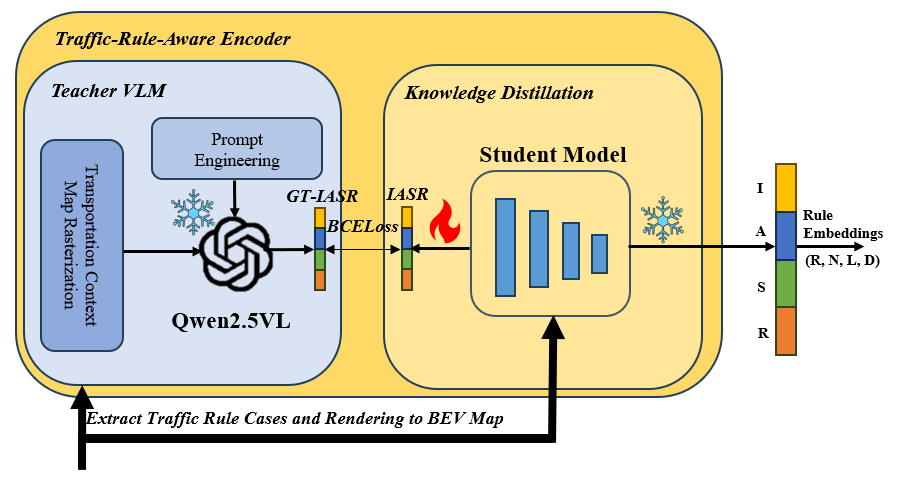
Figure 3. Traffic-Rule-Aware Encoder Architecture
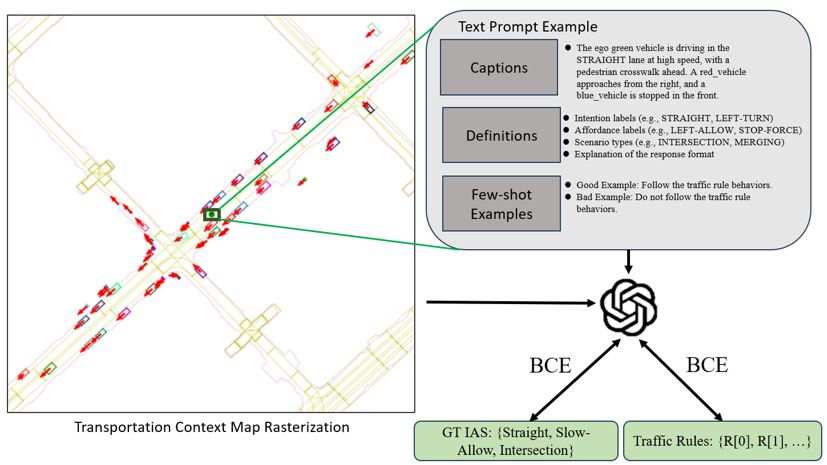
Figure 4. Prompt Engineering Schema
Prompt Engineering
- Transportation Context Map Rasterization converts dynamic and static traffic elements into BEV maps.
- Captures stop signs, lights, lanes, and agent context to structure the prompt input.
- Text Prompt is autogenerated with captions describing the scene and actions
- Provides rule definitions and few-shot examples to guide the teacher VLM output.
BEV Encoder and JEPA Self-Supervised Enhancement
A BEV encoder combines camera semantics and LiDAR geometry into BEV features; JEPA self-supervised pretraining improves robustness and generalization by learning scene structure and dynamics directly in BEV space.
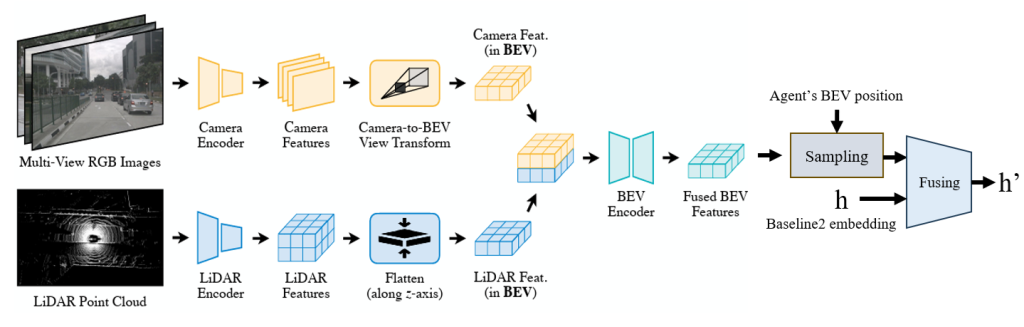
Figure 5. BEV Encoder

Figure 6. BEV-JEPA Self-Supervised Pretraining

Figure 7. BEV-JEPA Downstream Fine-Tuning Example on 3D Object Detection (Optional)
BEV Encoder and Fusion with Agents
We construct a unified BEV feature map by fusing multi-view camera and LiDAR signals in BEV space. For the camera branch, we adopt a pull-based BEV fusion strategy: for each BEV grid cell, we back-project the cell center into each camera view, sample the corresponding image feature from the multi-scale feature maps, and then aggregate features across views to obtain a BEV-aligned camera representation. In parallel, LiDAR point clouds are voxelized/encoded and projected into BEV to provide geometry-accurate features. We then fuse the BEV camera features and LiDAR BEV features (e.g., via concatenation + MLP/conv fusion) to capture both rich semantics (lanes, signals, markings) and 3D structure (free space, object geometry). For motion prediction, we extract agent-aligned BEV embeddings by sampling (or locally pooling) BEV features at each agent’s BEV location, and fuse them with the agent’s history and interaction representations to form the final per-agent token used by the trajectory decoder.
BEV-JEPA Self-Supervised Pretraining
We pretrain the BEV encoder using a JEPA-style objective to learn scene structure and dynamics directly in BEV space. Given a BEV feature map from the context encoder, we apply a random mask to a subset of BEV cells and use a predictor to infer the missing content (spatial JEPA) and/or future BEV features (temporal JEPA). A target encoder (EMA of the context encoder) produces the target BEV features with stop-gradient, preventing representation collapse. Training combines a reconstruction loss with variance/covariance regularization to encourage informative, diverse embeddings.
Loss Definition:
Let:
- : predicted BEV feature map (predictor output)
- : target BEV feature map (EMA encoder output, stop-grad)
- : set of supervised BEV cells (e.g., masked cells for spatial JEPA, or all cells for temporal JEPA)
- : mask indicator for Ω (1 if supervised)
1) Reconstruction MSE loss:(Equivalently, implement with a mask : average MSE only over masked/supervised cells.)
2) Variance regularization loss (avoid collapse)
First flatten spatial dims and compute per-channel std over samples:Then enforce a minimum target standard deviation (e.g., ):(You can apply this to , , or both; commonly applied to the predictor output.)
3) Covariance off-diagonal regularization loss (decorrelate channels)
Center features and compute covariance:
Penalize off-diagonal entries:This encourages different channels to encode complementary information rather than collapsing to redundant dimensions.
Combined Objective
Decoder
The decoder generates future trajectories for each agent by integrating scene and traffic-rule-aware embeddings information into an autoregressive generation process. It leverages dual cross-attention to fuse two modalities—scene context and legal reasoning—and produces sequential outputs step-by-step. The decoder is trained using teacher forcing and evaluated autoregressively at test time.
- Dual Attention Fusion: Combines scene embeddings (R,N,L,H) and traffic-rule-aware embeddings (R,N,L,D) via bi-directional cross-attention for comprehensive context modeling.
- Autoregressive Generation: Predicts future coordinates step-by-step, using prior outputs, self-attention, and cross-attention to the input embeddings.
- Training & Inference: During training, teacher forcing is used (ground truth fed into next step). At inference, previous predictions are recursively used as inputs.
- Output Format: The decoder outputs a motion sequence of shape (R,N,T,2), where 2 corresponds to predicted (x, y) positions at each timestep.

This motion loss maximizes the likelihood of predicted future positions given the agent history A before t and scene context S, averaged over all agents and time steps.
The following shows the decoder details. The decoder takes two inputs—scene embeddings (R,N,L,H) from the Scene Encoder and traffic-rule-aware embeddings (R,N,L,D) from the traffic-rule-aware encoder—each passed through an MLP to align dimensions. These are further fused using a Dual Attention module, which applies bi-directional cross-attention between the two modalities. The resulting fused embeddings are fed into a multi-layer autoregressive decoder composed of self-attention and cross-attention layers, allowing the model to generate future coordinates step-by-step while attending to both past predictions and contextual inputs. During training, teacher forcing is used by feeding in ground-truth positions, while inference is conducted autoregressively, relying on previously predicted outputs.
