Datasets
- nuScenes dataset [5]:
- We evaluate on the nuScenes dataset and build a dedicated motion-forecasting set by sweeping the entire dataset with a past 2s / future 6s context window. For each scene, we render an ego-centric BEV map covering a fixed spatial range of x∈[−80m,80m] and y∈[−80m,80m], aligning LiDAR points, HD-map elements (lane centerlines/dividers, crosswalks), traffic lights, and annotated agents into a common coordinate frame. This preprocessing yields 12,782 samples, split into train/val/test = 8:1:1, providing consistent multi-modal BEV context for training and evaluating multi-agent motion prediction models.
- Below shows an example of BEV rendered map including the HD map elements, such as lane center, road divider, stop lines, traffic light and pedestrian crossing, agents’ history motion (colored dashed line behind a colored point) and current position (colored circle point)/heading (colored arrow), and the ego car’s history trajectory (colored dashed line behind the black circle point at the center of the map) and current position/heading.

Figure 1. BEV Rendered Map
Metrics
We evaluate model performance using three standard trajectory forecasting metrics: minADE and minFDE. These metrics assess the spatial accuracy of predicted agent trajectories compared to the ground truth, based on the best of multiple rollout predictions.
- minADE (Minimum Average Displacement Error): Measures the best average L2 distance between predicted and ground-truth positions over all timesteps. It is defined as

- minFDE (Minimum Final Displacement Error): Measures the L2 distance at the final timestep TTT between the ground-truth position and the closest predicted endpoint among all rollouts:
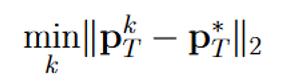
Qualitative Results
We show some visualization of our prediction results below. The green lines in front of each agents (colored circle points) are the ground-truth future trajectories, and the yellow dashed lines are the predicted future trajectories. the black point in the middle of each figure is the ego car. If there is not green line in front of an agent, it means the agent is stationary at that point.

Figure 2. Predicted Result Example #6

Figure 3. Predicted Result Example #19

Figure 4. Predicted Result Example #32

Figure 5. Predicted Result Example #77
Figure 2 illustrates a signalized intersection scenario with dense multi-agent interactions, where vehicles execute left turns, go straight, and yield under traffic-light control. The predicted trajectories closely follow lane centerlines and respect stop lines and signal constraints, showing that the model captures both interaction dynamics and traffic-rule-aware behavior in complex intersections.
Figure 3 shows a curved road segment with continuous traffic flow, where multiple agents travel along parallel lanes with minimal interaction. The model produces smooth, lane-consistent predictions that align with the road geometry, demonstrating strong map adherence and stable long-horizon forecasting in less ambiguous scenes.
Figure 4 depicts an intersection with mixed maneuvers, including straight driving and turning agents under sparse but nontrivial interactions. The predicted trajectories remain well-aligned with lane geometry and avoid collisions, indicating the model’s ability to jointly reason about agent intent and surrounding context in moderately complex settings.
Figure 5 presents a highly complex road topology with sharp curvature and diverse agent behaviors, where agents navigate bends, merges, and crossings simultaneously. Despite increased uncertainty and interaction density, the model maintains coherent and feasible trajectory predictions, highlighting its robustness in challenging, non-linear driving scenarios.
Quantitative Results
We evaluate our approach on the nuScenes motion prediction benchmark using standard metrics minADE and minFDE, which measure average and final displacement error over multiple predicted trajectories. We compare our method against representative state-of-the-art models that leverage lane topology, interaction modeling, and transformer-based architectures. All methods are evaluated under the same prediction horizon and evaluation protocol.

Table 1. Our predicted results compared with nuScenes leaderboard.
Table 1 reports the quantitative comparison. Our model achieves competitive minADE while significantly improving minFDE, indicating more accurate long-term trajectory forecasting. In particular, our method reduces minFDE from 3.624 (DGCN_ST_LANE) and 6.702 (CASPFormer) to 2.346, demonstrating stronger ability to predict final agent positions in complex, multi-agent scenes.
Overall, these results show that integrating BEV-based multi-modal perception, JEPA self-supervised representation learning, and traffic-rule-aware reasoning leads to more stable and accurate motion predictions, especially over longer horizons where interaction and scene understanding are critical. While minADE remains comparable to strong baselines, the substantial gain in minFDE highlights the effectiveness of our approach for long-term, interaction-consistent multi-agent motion prediction.