
Overview

Motivation
Recent video generation models have emerged as strong world foundation models, acting as virtual environments where physical AI can grow and learn. They generate high quality RGB videos that serve as the visual representation of the world.
However, generating RGB alone is not enough. If we want a world model that truly mimics our real world, it should generate additional modalities, such as depth, that capture underlying geometry and physical structure.
In this project, we consider the task of joint multimodal generation:
Given an RGB video input and/or a text prompt, the model should jointly generate:
- An RGB sequence
- A depth sequence
These sequences should be physically plausible and mutually coherent: the depth should explain the RGB, and the RGB should be consistent with the implied 3D structure.
We specifically aim for joint generation within a single model, rather than first generating RGB video and then running a separate RGB-conditioned depth model. A unified model that generates both appearance and geometry encourages a shared, geometry-aware representation of the world.
Architecture
We build on NVIDIA’s Cosmos Diffusion-based World Foundation Models, with the following architecture:



Method
Our method mainly consists of 2 stages:
- Training the Cosmos video tokenizer to additionally encode depth information
- Training the diffusion transformer to generate tokens that can be decoded into RGBD videos
Stage 1 Autoencoder Training
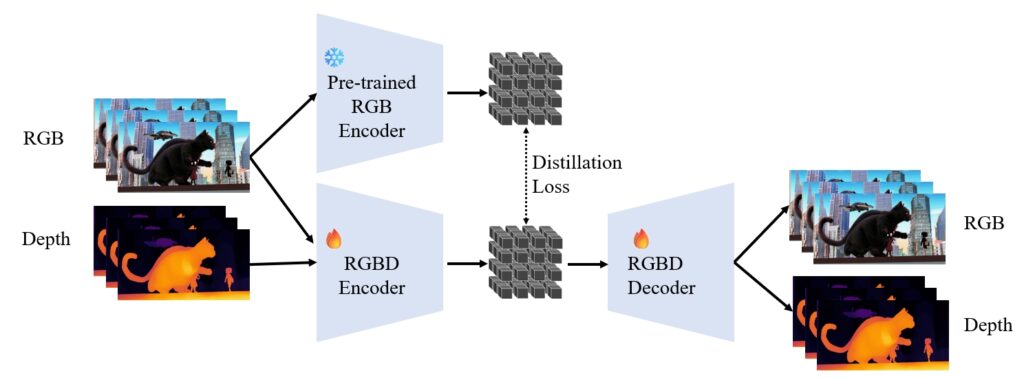
We add one input channel and one output channel to the video tokenizer to process depth. The tokenizer is then trained with paired RGB-D videos from synthetic datasets, using affine-invariant disparity(normalized to a median of 0 and mean deviation of 0.5). Apart from standard reconstruction losses used in AE training, we also adopt a distillation loss to align our RGBD latent space with the original RGB latent space. This is so that we can preserve diffusion priors from the original Cosmos video generation model.
Stage 2: Diffusion Model Training
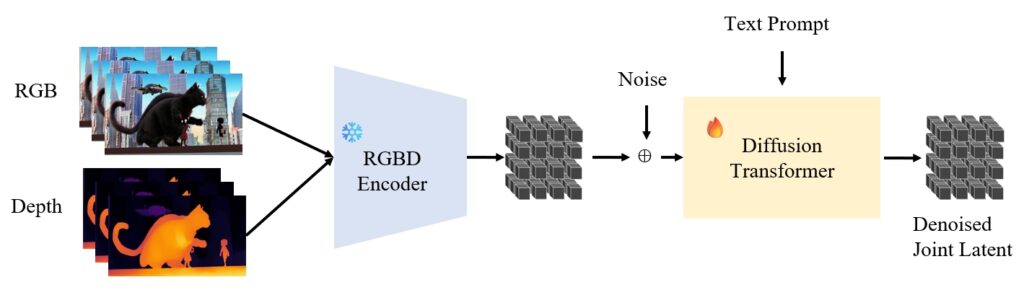
In stage 2 we plan on training the diffusion transformer with paired RGBD videos. Before training, we will also curate more video datasets, not only including synthetic datasets but also pseudo-labelled real datasets, and generate text captions for training.
Results
Currently, we only have results from the first stage of our method, i.e. RGBD autoencoder reconstruction results. For every sample shown, the left side is the input RGB and depth videos, and the right side is the reconstructed RGB and depth videos.
Reconstruction sample 1




Reconstruction sample 2




Reconstruction sample 3




Reconstruction sample 4




Conclusion & Future Work
As seen in the results, we yielded reasonable reconstructions and showed that Cosmos’s latent space can, in principle, support depth. However, fine details and sharp boundaries were consistently degraded, highlighting the difficulty of naïvely packing RGB and depth into a single, capacity-limited latent space.
Future directions include exploring factorized latent representations for appearance vs. geometry, increasing latent capacity, and improving loss design and supervision for depth.
Resources
Video Presentation:
https://drive.google.com/file/d/1jaXofzv7DgGcxXxojCbXH8B5QiGaznIv/view?usp=sharing