
Our method mainly consists of 2 stages:
- training the Cosmos video tokenizer to additionally encode depth information
- training the diffusion transformer to generate tokens that can be decoded into RGBD videos
Stage 1 Autoencoder Training
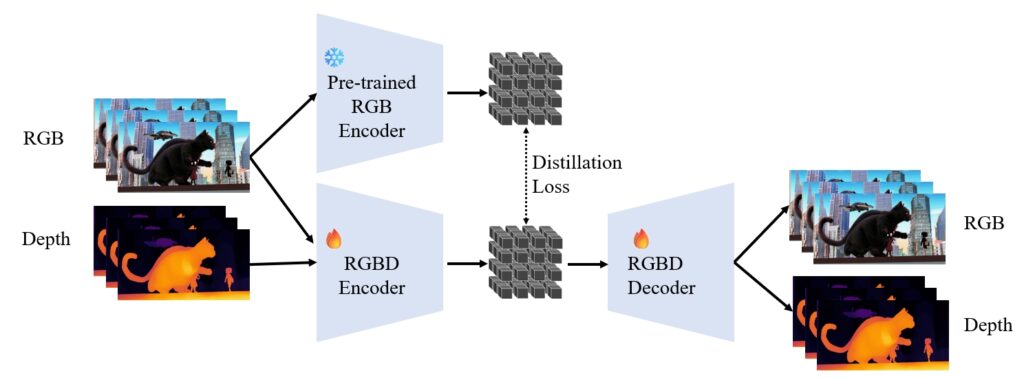
We add one input channel and one output channel to the video tokenizer to process depth. The tokenizer is then trained with paired RGB-D videos from synthetic datasets, using affine-invariant disparity(normalized to a median of 0 and mean deviation of 0.5). Apart from standard reconstruction losses used in AE training, we also adopt a distillation loss to align our RGBD latent space with the original RGB latent space. This is so that we can preserve diffusion priors from the original Cosmos video generation model.
Stage 2: Diffusion Model Training
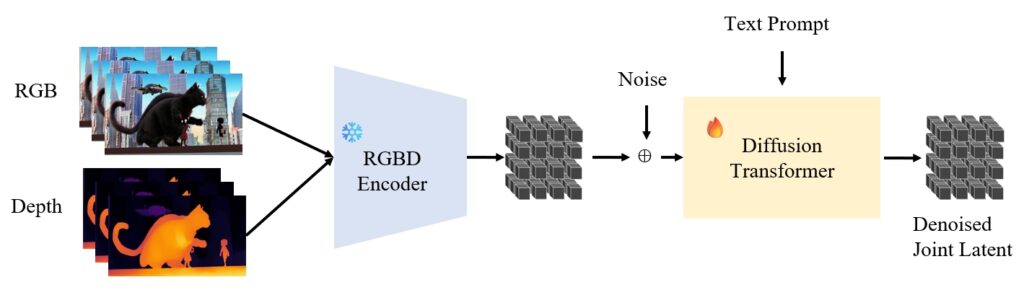
In stage 2 we plan on training the diffusion transformer with paired RGBD videos. Before training, we will also curate more video datasets, not only including synthetic datasets but also pseudo-labelled real datasets, and generate text captions for training.