
2025 MSCV Capstone project of Daniel Yang, Tianzhi Li
Supervised by Katia Sycara, Yaqi Xie
Motivation
Video Question Answering (VideoQA) requires reasoning over actions that occur at drastically different timescales — from short, atomic gestures like picking up an apple to long-term goals like shopping in the supermarket. Traditional vision-language models struggle to capture such temporal diversity, particularly in long videos where long, overarching intentions and fine-grained actions coexist.
We propose a temporally hierarchical scene graph representation to address this. Scene graphs encode video content as compact <Subject – Relation – Object> triplets, enabling structured and explainable reasoning. By building scene graphs at multiple temporal resolutions — from frame-level interactions to high-level goals — we can preserve both fine-grained actions and overarching intentions.
This approach offers a scalable, interpretable, and resource-efficient method for long-form video understanding, making VideoQA more tractable across diverse tasks and durations.

Datasets
The EgoSchema benchmark contains over 5000 very long-form video language understanding questions spanning over 250 hours of real, diverse, and high-quality egocentric video data. Many videos feature complex scenes with cluttered rooms, where we could take full potential of scene graphs.

NExT-QA is a VideoQA benchmark targeting the explanation of video content. It challenges QA models to reason about the causal and temporal actions and understand the rich object interactions in daily activities. NExT-QA contains 5,440 videos and about 52K manually annotated question-answer pairs, grouped into causal, temporal, and descriptive questions. The videos are about 35 seconds long and focus on interactions between people and sometimes pets.

Proposed Method
We plan to simultaneously generate a hierarchical structure of scene graphs and utilize them to tackle VideoQA tasks.
Since we don’t have access to higher-level scene graphs beyond frame-by-frame image scene graphs, we have to construct the higher-level scene graphs in a self-supervised manner.
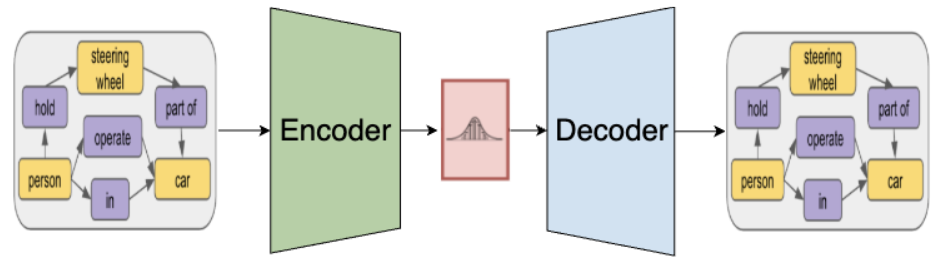
We outlined the steps to generate high-level scene graphs that express short clips from image-level scene graphs.

- Dense low-level scene graph prediction from video frames
- Densely predict scene graph for each frame with off-the-shelf scene graph generator; collapse identical and continuous scene graphs.
- Each node has a node embedding, initialized with image embedding & word embedding.
- Self-supervised scene graph encoding
- Given the lack of supervision for scene graph encoding, we adopt a Variational Autoencoder (VAE) to learn embeddings in a self-supervised manner.
- The encoder maps the scene graph into a continuous latent vector, enforcing semantic smoothness across similar graphs.
- We also adopt a contrastive loss to align the latent vector of temporally adjacent scene graphs.
- Local action segmentation & scene graph reconstruction
- Given the sequence of latent vectors from the scene graph encoder, we segment the video into coherent action segments.
- Aggregate latent vectors within segments via self-attention to obtain high-level segment embeddings.
- Utilize the VAE decoder to reconstruct segment-level scene graphs, forming a higher-level abstraction.
- Video QA end-to-end finetuning
- Tokenize higher-level scene graphs and input them to an LLM for question answering.
- Finetune the entire system end-to-end, with LoRA-based updates on the LLM and full updates on upstream modules
- For subsequent QAs, we should be able to discard the original video and answer questions with our hierarchical scene graph structure.
References
[1] Mangalam, K., Akshulakov, R., & Malik, J. (2023). EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding. arXiv:2308.09126. https://arxiv.org/abs/2308.09126
[2] Xiao, Junbin, et al. “Next-qa: Next phase of question-answering to explaining temporal actions.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[3] Wang, Guan, et al. “OED: towards one-stage end-to-end dynamic scene graph generation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[4] Islam, Md Mohaiminul, et al. “Video recap: Recursive captioning of hour-long videos.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[5] Liang, Weixin, Yanhao Jiang, and Zixuan Liu. “GraghVQA: Language-guided graph neural networks for graph-based visual question answering.” arXiv preprint arXiv:2104.10283 (2021).[6] Nag, Sayak, et al. “Unbiased scene graph generation in videos.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.