
Leveraging Geometric Foundation Models (VGGT) for Robotic Manipulation
We adopt the environmental setup and evaluation protocol used in Diffusion Policy (DP3). We utilize the Adroit simulation environment, built on MuJoCo, to evaluate the proposed method. Adroit provides a set of dexterous manipulation tasks involving a 24-DoF anthropomorphic robotic hand, making it an good benchmark for fine-grained visuomotor control and imitation learning. Specifically, we focus on the Adroit Hammer task, in which the hand must grasp a hammer and drive a nail into a wooden block
In the experiments below, we compare different bottle-necking and polling strategies to downsample features to a compact 3D representation. We also experiment on which layers of the VGGT model would be most suitable for a manipulation task. Further to demonstrate the advantage of VGGT 3D features by comparing against DINOv2 features.
MLP Bottleneck
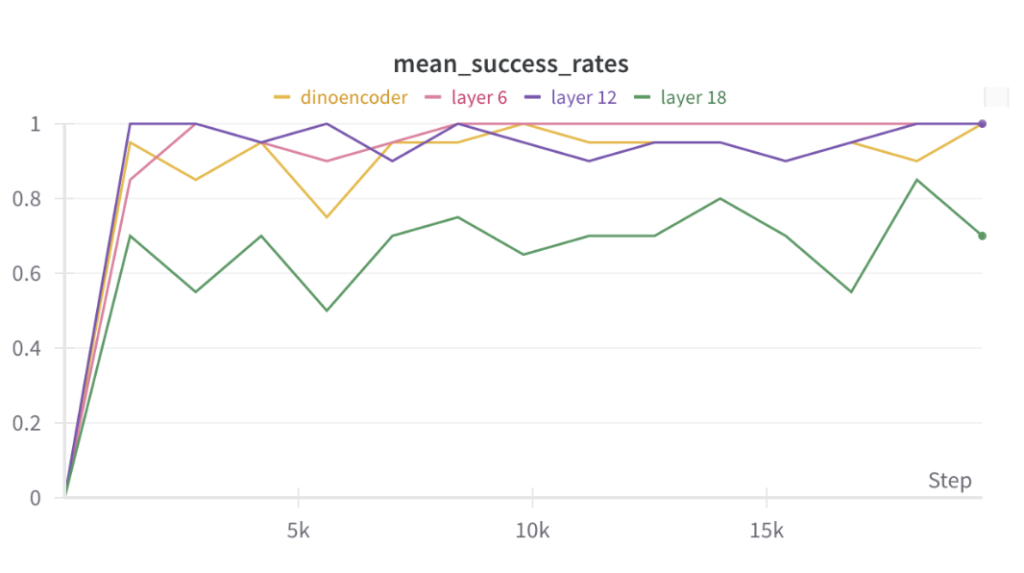
We compare the mean success rates when using VGGT features from layer 6, layer 12 and layer 18 when using an MLP bottleneck for downsampling. The best performance was achieved with features from layer 6, indicating that earlier layers yield better results.

Conv Bottleneck
We compare the mean success rates when using VGGT features from layer 6, layer 12 and layer 18 when using an Conv bottleneck for downsampling. Similar to the MLP bottleneck above, best performance was achieved with features from layer 6, indicating that earlier layers yield better results.
When comparing MLP and Conv bottlenecks, the MLP strategy consistently yields better results.

Polling Strategies
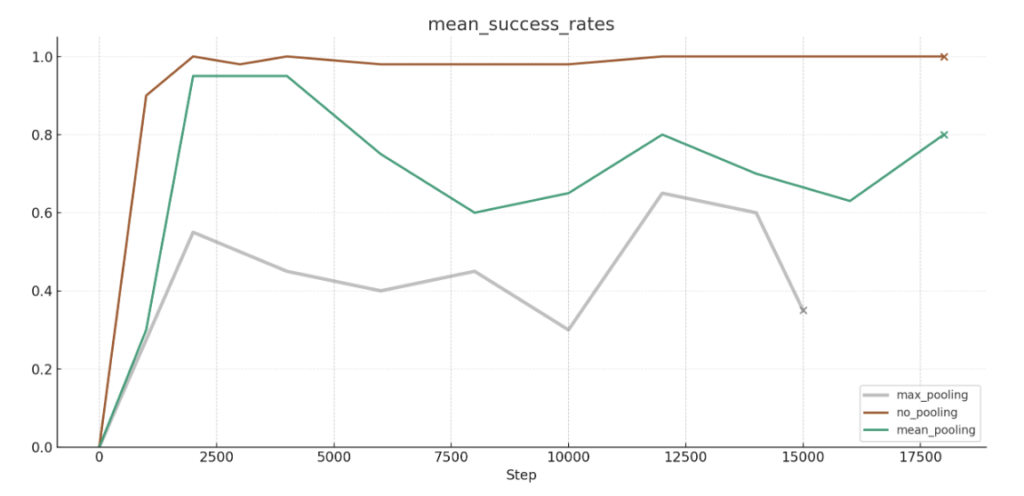
To reduce the dimensionality of VGGT features, we also explored various pooling strategies. Our results showed that using a linear layer without any pooling achieved the best performance, suggesting that the information loss introduced by pooling negatively impacts results.
3D features (VGGT) vs 2D features (DINOv2)
To assess the benefits of a 3D-aware model like VGGT, we compare it against strong image feature representations from DINOv2. VGGT shows a slight performance gain, suggesting that 3D-aware features can offer valuable advantages for manipulation tasks.
Quantitative Results: Adroit Environment
The table below presents the mean success rates on tasks from the Adroit environment. Despite operating with reduced input information (RGB only), our method leverages VGGT features to achieve performance that is nearly on par with the strongest baseline, DP3, which benefits from RGB-D input and ground-truth point clouds. Notably, our approach significantly outperforms the vanilla Diffusion Policy when both methods operate under the same RGB-only setting, demonstrating the effectiveness of the proposed representation.

Improving Grasping with Learning-based Shape Completion Networks
The table below summarizes our fine-tuning results on the GraspNet dataset. When replacing the original single-view RGB-D point clouds with RaySt3r-completed point clouds, we observe no significant change in grasping performance across Novel and Similar object splits. We believe this outcome is largely due to the GraspNet point clouds already containing relatively complete geometry with limited occlusion, reducing the potential benefit of 3D completion.
These results suggest that the true advantages of RaySt3r-based completion may emerge in settings with heavier occlusion, sparsity, or partial observations—scenarios where shape completion provides new geometric information that the grasp planner cannot otherwise infer. Evaluating on such datasets is therefore an important next step.

Grasping performance (AP, AP@0.8, AP@0.4) on Novel and Similar object splits of the GraspNet Dataset