
Method
Our work focuses on to reducing the embodiment gap between humans and humanoid robots by performing retargeted reconstruction. Conventional learning-from-demonstration pipelines first reconstruct a human using a parametric body model such as SMPL, followed by a separate retargeting step to obtain a humanoid pose. This paradigm becomes limiting when an appropriate parametric mesh is unavailable, particularly for non-humanoid robots.
In contrast our approach leverages meshes that already exist in physics simulators and directly reconstruct the geometry of a posed robot from an image of its biological counterpart (e.g., reconstruct a quadruped from a dog or a humanoid from a human).
By avoiding an intermediate reconstruction and retargeting step, our approach produces outputs directly in the target robot geometry, enabling pose learning in an interpretable and end-to-end manner.
We demonstrate a specific example use case of our approach by reconstructing a G1 humanoid from humans.
Method Overview
We propose a reconstruction pipeline trained on a wide diversity of labelled data, generated using generative models. We provide an overview of our proposed method below:

Our pipeline consists of three stages:
- Data generation
- Point map prediction
- Joint angle estimation
For training, we generate paired data of synthetic humans with their corresponding ground-truth humanoid pose and geometry. We then use this data to train our point map predictor and joint angle estimator.
At inference time, we take in image sequences of real humans and predict out the corresponding equivalent robot geometry and robot joint angles.
Data Generation
Our data generation pipeline synthesizes humans of a similar morphology as the G1 humanoid by leveraging generative models. We show an example of a generated sequence below:

Creating robot motions
We leverage motion is sourced from the MoVi dataset, which provides paired videos and SMPL-H body meshes. We retarget SMPL-H to the G1 humanoid robot using Perpetual Humanoid Control to obtain robot joint angles that faithfully reproduce the original motion. This provides us with a diverse set of robot motions which we leverage for training and real human-robot pairs for validation.

Generating Diverse Images
We generate a diverse set of human images by prompting Image GPT to generate images of people of different ages, ethnicity, clothing and backgrounds.

Editing to create Human-Robot data pairs
We then reanimate these images of people such that they are in the same morphology and pose of the G1 robot using MagicDance. We use the driving motion in the video below to demonstrate how we animate a G1 robot and then use the tracked keypoints to generate humans of a robot’s morphology for training our model.

Extracting Ground truth 3D geometries
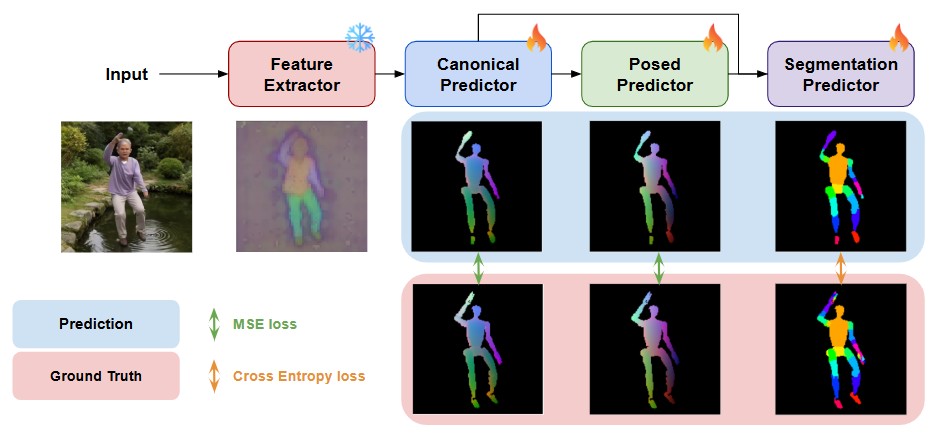
Given the posed robot we extract layered point maps that represent the 3D robot geometry with Depth Peeling using NvDiffRast. This allows us to obtain both canonical and posed pointmaps as well as part segmentations for every frame.

Layered Point map Regression
We then adopt a DualPM inspired approach to regress per-frame 3D geometries in both canonical and posed spaces, allowing us to capture deformation dynamics and part segmentations.
Here is an example output of the predicted posed point maps when tested on real data:

Joint Angle Estimation
We adapt PointNet to perform regression rather than classification. During training, we use the ground-truth point maps and segmentation masks produced by our synthetic data-generation pipeline. For each training iteration, we extract all foreground points across the L layers and uniformly sample 5,000 points to form the input point cloud.
The network is supervised to regress the joint angles θ that were used in MuJoCo to render the corresponding point maps. Since most humanoid joints are 1-DOF hinge joints, we employ the geodesic L1 loss on the circle to correctly account for angular periodicity.
At test time, the PointNet regressor operates on sampled point clouds obtained from the predicted point maps and segmentation masks produced by our Point Map Predictor, enabling a fully feedforward human image to humanoid pose estimation pipeline without any online retargeting or optimization.
