
Overview
Motivation
Robots hold immense promise in transforming society—supporting disaster response assisting in eldercare, performing hazardous inspections, and enhancing productivity across industries. Yet despite recent hardware advancements, robot learning remains far behind the progress seen in computer vision and natural language processing. While vision and language models benefit from massive web-scale datasets, robots still rely heavily on simulation or narrowly curated demonstrations. As a result, they struggle to generalize to the real world.
Problem Statement
Despite improvements in perception and control, robot learning faces three major challenges: sparse rewards in reinforcement learning, limited access to diverse motion data, and a fundamental embodiment gap between animals and machines. These barriers prevent current methods from scaling and generalizing effectively.
- Sparse Rewards in Reinforcement Learning
Sparse rewards in reinforcement learning makes it difficult for robots to efficiently acquire complex behaviors. This is because success is observed only after long, complex trajectories. The delay in providing reward feedback makes training slow and learning hard. - Limited Robot Learning Datasets
Most robot learning datasets are small, domain-specific, and costly to collect. In contrast, computer vision benefits from abundant internet-scale data. The lack of large scale, diverse datasets hampers the ability of robots to learn from a wide variety of scenarios. - Embodiment Gap
Even for robots inspired by real creatures, a significant embodiment gap remains between the robot and its biological counterpart. Biological creatures exhibit flexible, high-degree-of-freedom motion, while robots are constrained by their structure and actuators. This mismatch makes it difficult to directly imitate behaviors from human and animal videos.

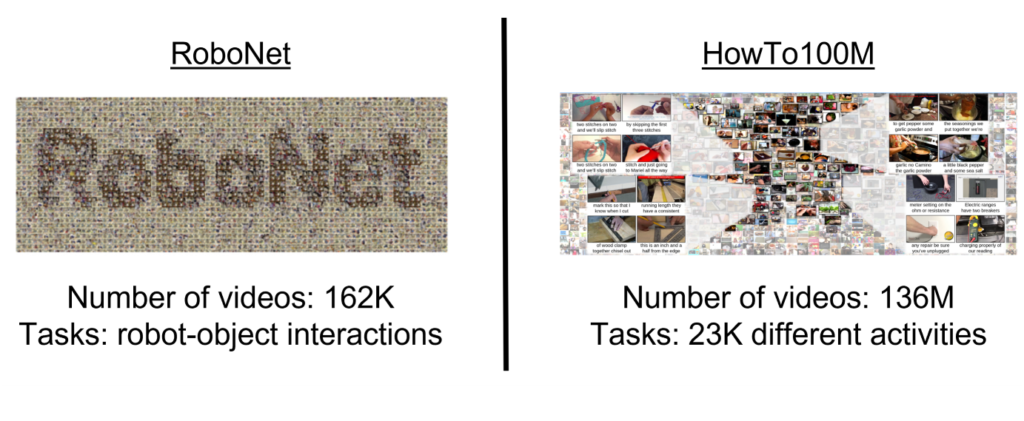
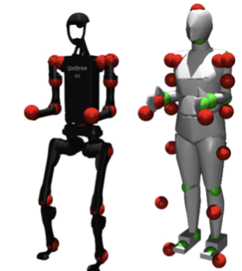
Our Goal
To address these challenges, our project aims to leverage reconstruction to help robots learn from large-scale, in-the-wild video data by extracting motion representations that are both visually grounded and compatible with robotic embodiments. By creating a framework that leverages visual data from the real world to generate transferrable robot motions, we aim to enable scalable learning of diverse behaviors grounded in everyday human and animal motion.