Our approach intends to experimentally evaluate the robustness of monocular depth estimation (MDE) models. Specifically, we seek to develop a diagnostic toolbox that can allow you to systematically sample failure modes for common MDEs. This objective can be effectively seen below.

Camera Parameterization
To identify failures in an MDE model, we parameterize the camera with nine parameters: six for orientation, R={r1,…,r6}, and three for position, . Following prior work, we use for rotation due to its smoother optimization landscape .
We also needed to pick a good camera parameterization to ensure that the model optimizes well. Specifically, the SO(3) parameterization is prone to many local minimas and unstable optimization gradients. To tackle this, we use a R6 overp-arameterization defined as,
Baselines and Dataset Generation
Dataset Generation
While datasets such as 3D-FRONT and Hypersim exist, there remains a notable lack of diversity in synthetic indoor datasets that are compatible with differentiable renderers like PyTorch3D. To address this gap, we construct a small but diverse dataset of 10 texture-rich indoor scenes. Our pipeline integrates Blender and PyTorch3D, enabling us to bake high-quality textures in Blender into a single 8K texture map, while ensuring compatibility with PyTorch3D’s differentiable rendering framework.
Our process is as follows:
- Convert publicly available 3D assets originally made for Blender into formats compatible with PyTorch3D.
- Merge all objects in each scene into a single mesh.
- Generate a unified UV map using Blender’s Smart UV unwrap.
- Bake all object textures into a single 8K texture map using Blender’s Cycles Renderer.
- Load the processed mesh and texture into PyTorch3D while preserving spatial relationships.
- Create a repository of converted 3D assets for direct rendering in PyTorch3D.
- Streamline workflows for 3D rendering and analysis using the converted assets.

Viewpoint Initialization
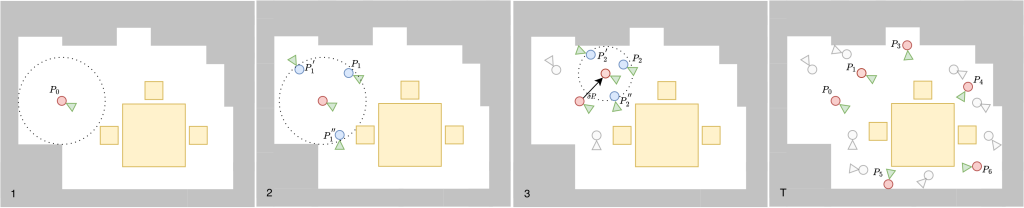
We use a guided seeded random sampling approach to initialize our viewpoints. We begin by taking a point inside the scene mesh. Then at each iteration we find the distance to the closes mesh face, define a collider and then perturb the camera pose inside that “safety sphere”. We define this as,
This process is followed by culling where we remove degenerate camera poses using semantic diversity in the scene. Finally, we run this for 100 iterations to sample 50 valid candidate poses.
The culling is defined as,
Current Approach
Beyond the baselines that we have sampled, our current approach is straightforward. Here, we use a differentiable rendering pipeline to optimize the camera pose based on the z-buffer depth prediction.

Instead of conventional pixel-wise regression losses such as or , we incorporate a patch-wise ordinal loss into the objective function. The motivation for this design choice is that our primary concern is not strict numerical accuracy of depth values on an absolute scale, but rather the preservation of relative depth relationships and the avoidance of distributional inconsistencies (e.g., incorrect foreground–background ordering).
Instead of enforcing point-wise agreement, the patch-wise formulation evaluates depth relationships over local regions, encouraging consistent ordinal structure within each patch. This makes the loss more robust to global scale and shift ambiguities that commonly arise in monocular depth estimation. By operating at the patch level, the loss captures local geometric context and penalizes violations of relative depth ordering that are perceptually significant but may be weakly reflected in pixel-wise metrics.
Our final objective function is therefore defined as follows:
Then the overall patchwise loss is given as,
On top of the patchwise loss, we also define a collision regularization term,
Giving us the final loss defined as,
Overall, this approach combines the advantages of various approaches as shown below.

Metrics
To quantitatively assess the accuracy of predicted depth maps, we use commonly adopted metrics in monocular depth estimation that capture both relative and absolute errors.
1. Absolute Relative Error (AbsRel).where and are the predicted and ground-truth depth values for pixel i, and is the number of valid pixels. AbsRel measures the fractional error relative to the true depth, highlighting overall magnitude discrepancies.
2. Accuracy under Threshold.
We specifically use the delta1 scores.
This metric evaluates the percentage of pixels where the predicted depth is within a multiplicative factor of the ground truth. Common choices are capturing increasingly relaxed tolerances. Higher indicates better depth alignment.
3. Interpretation.
Lower AbsRel indicates closer absolute agreement with ground truth depth values.
Higher indicates better relative ordering and consistency of depth predictions.
These metrics together provide a balanced view of depth prediction quality: AbsRel captures absolute scale errors, while captures relative depth consistency, which is particularly relevant when evaluating robustness to adversarial viewpoints or across different camera configurations.