
Motivation
Harmful bias is an issue that has persisted with the development of computer vision. Among the potential causes, a major bias contributor is the training dataset. Biases in training datasets often manifest as spurious correlations, which are unintended associations with nuisance attributes that undermine both model effectiveness and fairness. Gender biases are evident in datasets such as MS-COCO, Figure 1., where image captions associate activities with gender stereotypes, and CelebA Figure 2., which exhibits disparities in attributes such as hairstyles and hair color across genders.
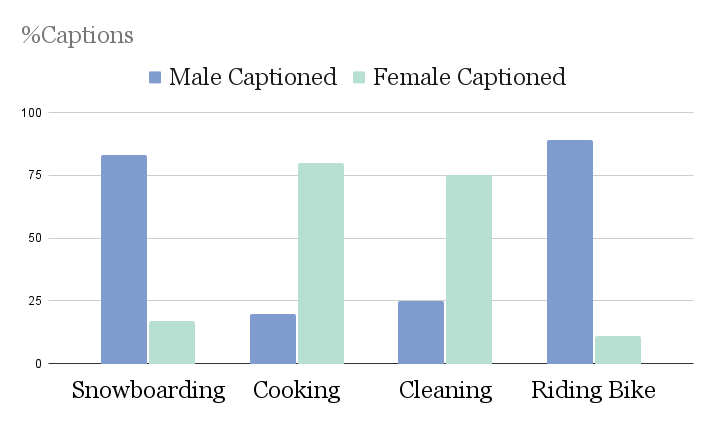

Problem Statement

Consider, a toy cat/dog image classification task in Figure 3, if the training data predominantly features orange cats and black dogs, a model may mistakenly associate fur color, a nuisance attribute, with the species label, leading to misclassification of bias-conflicting samples, e.g., a dog with orange fur. As computer vision datasets grow increasingly large and complex, there is a critical need for automatic and systematic debiasing strategies to ensure models learn robust features.
In this project, we aim to leverage the rich CLIP embedding space for automatic vision classifier debiasing without requiring any manual explanation or explicit bias information.