Although state-of-the-art method, e.g. 3DGS, can reconstruct 3D avatar with good overall quality, we still observe some limitations, which are the motivations of our work.
Limitation of 3DGS-based reconstruction methods
When resolution of rendering views is way larger than that of training views, artifacts and quality degradation become very obvious. For example, when you zoom-in to a 3D avatar’s face in a VR scenario, the detail-loss and blur on the avatar will harm the immersive experience.

Limitation of existing 3DGS-enhancement method
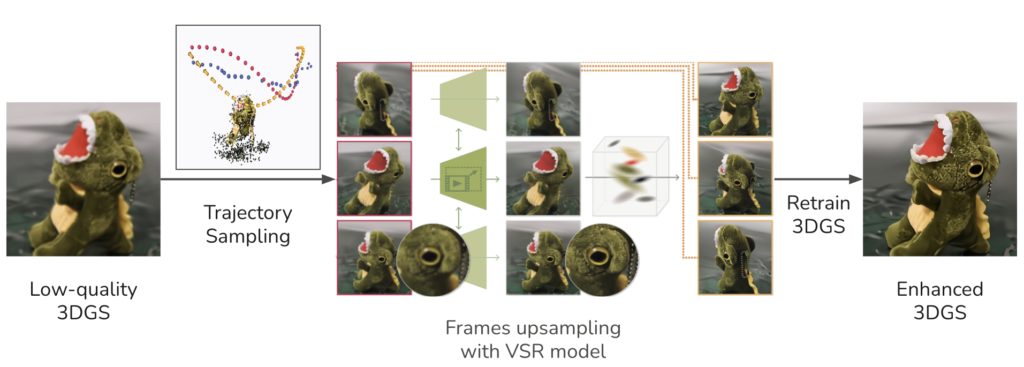
Some works were proposed to solve this quality issue of 3DGS. However, current 3DGS-enhancement methods tend to enhance the 3DGS utilizing pre-trained 2D media enhancement methods, which leads to high overhead.
SuperGaussian uses a pre-trained video super-resolution method to first enhance sampled views from a low-quality 3DGS, then re-train/fine-tune the 3DGS with enhanced multi-views. While it could lead to good improvement of quality, it takes ~30 minutes for the whole enhancement process.