

Upon discussions with our project sponsor, we converged on two main pipelines that would allow the user to easier generate pipelines.
The first, shown on top, is Control via Demonstration – a method by which the user can generate a trajectory by recording it on their phone, and the robotic camera rig will mimic this output to the best of its ability, while recognizing its physical constraints. Further details are included in the corresponding page.
The second, shown on the bottom, is Control via Natural Cinematographic Prompts – a method where the user can either type or speak a prompt directing what the shot will look like, and the system will generate a 3D grounded trajectory that the robotic rig can then follow. This is done by our Intent-to-Motion Layer, which builds upon the methodology introduced by Liu et al. in 2024 [1]. It has three key components: LLM Agent, a Text-To-Trajectory model, and an anchor detector. Further details are included in the corresponding page.
A final Trajectory Refinement Layer is used to ensure the trajectory fits within physical constrains of the robotic rig, while maintaining the directorial intent behind the input or generated trajectory.
Trajectory Refinement and Execution Layer
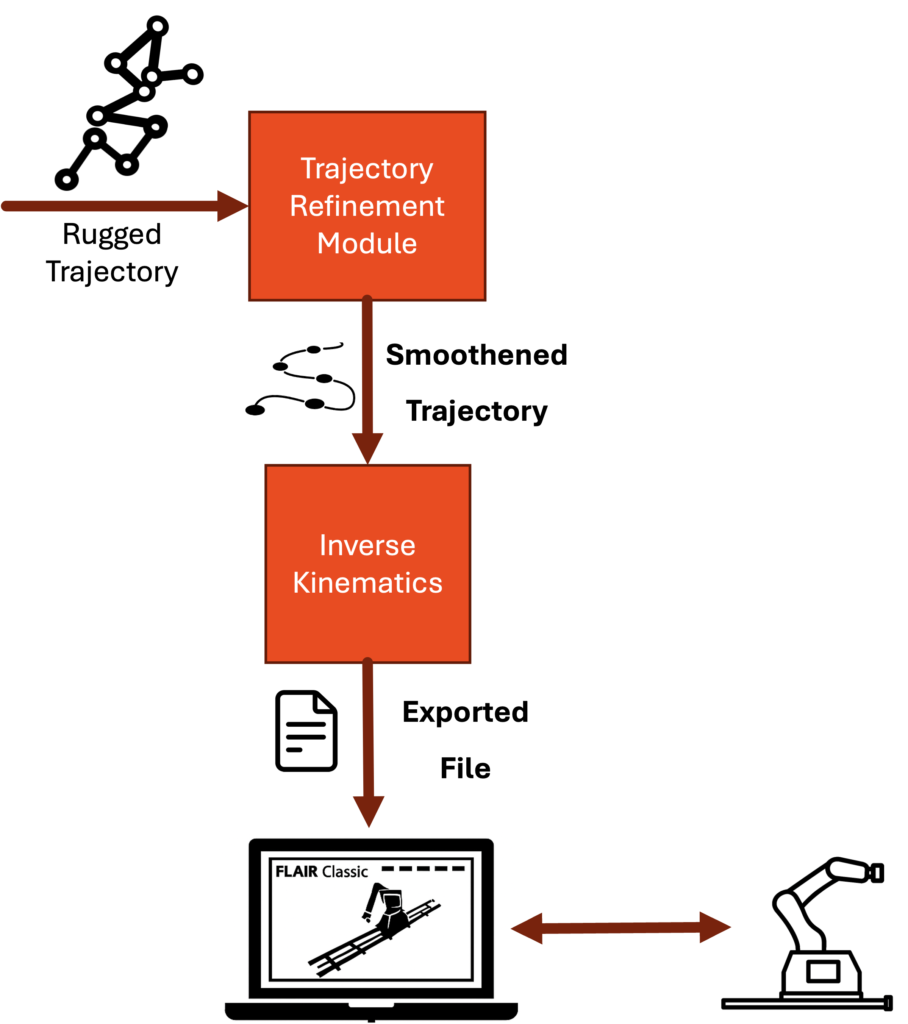
Trajectory generation may result in a non-smooth trajectory with rapid angle and speed changes. This module is responsible for generating a smooth trajectory based on predefined heuristics.
Once we have a trajectory, we need to convert it to control commands that can be understood by the robotic rig.
The inverse kinematics module solves for various control values given the 3D position in the world coordinate system.
We assume a 7-DOF cinematic robot arm as shown in Figure 3.

Assuming dynamics of a 7-DOF cinematic robotic arm, we solve for the values for 4 control joints (Arm, Lift, Rotate, and Track) by solving the set of equations below in a least squares manner. While many of these are accounted for by Flair, we have to solve for the Arm value ourselves, necessitating this inverse kinematics model.
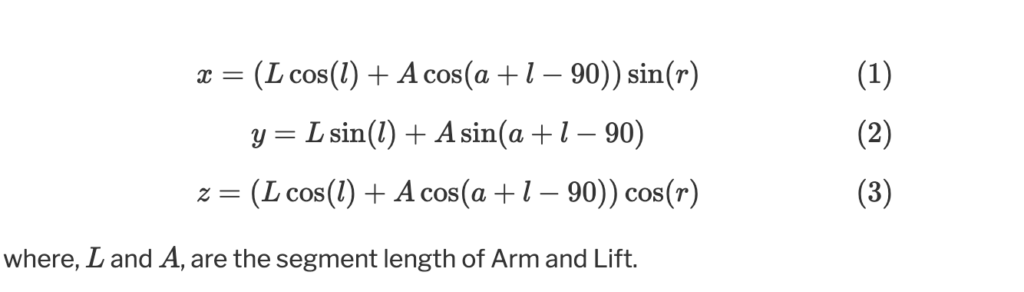
References
[1] Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. ChatCam: Empowering camera control through conversational AI, 2024.