
Abstract
Object permanence in humans is a fundamental cue that helps in understanding persistence of objects, even when they are fully occluded in the scene. Present day methods in object segmentation do not account for this amodal nature of the world, and only work for segmentation of visible or modal objects. Few amodal methods exist; single-image segmentation methods cannot handle high-levels of occlusions which are better inferred using temporal information, and multi-frame methods have focused solely on segmenting rigid objects. To this end, we propose to tackle video amodal segmentation by formulating it as a conditional generation task, capitalizing on the foundational knowledge in video generative models. Our method is simple; we repurpose these models to condition on a sequence of modal mask frames of an object along with contextual pseudo-depth maps, to learn which object boundary may be occluded and therefore, extended to hallucinate the complete extent of an object. This is followed by a content completion stage which is able to inpaint the occluded regions of an object. Perhaps surprisingly, we do not require RGB (appearance and texture) information, which allows us to better transfer to real-world videos with learning from synthetic datasets. We benchmark our approach alongside a wide array of state-of-the-art methods on four datasets and show a dramatic improvement of upto 13% for amodal segmentation in an object’s occluded region.
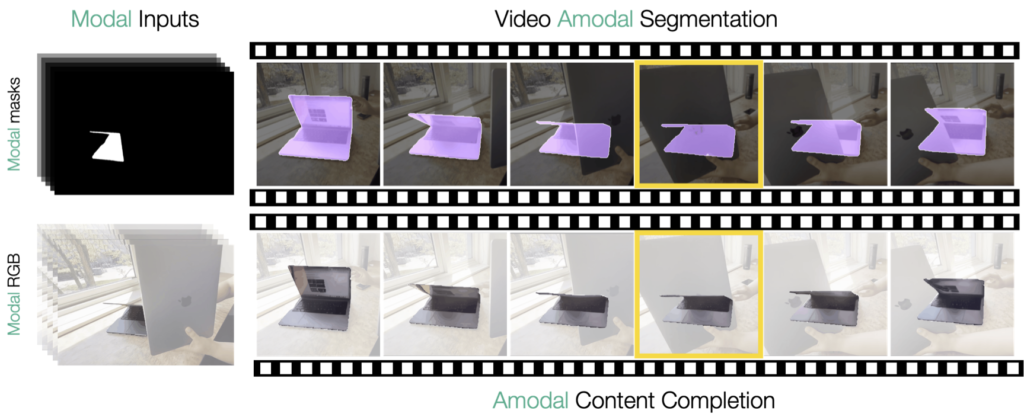
Figure 1: An example of video amodal segmentation and content completion
In this work, we develop a two-stage method that generates object’s amodal (visible + invisible) masks and RGB content. Our method is effectively able to handle severe occlusions and generalizes across diverse object categories, achieving state-of-the-art results on synthetic and real-world datasets. We show one such example of an unseen deformable object category ‘laptop’ that undergoes a complete occlusion in the highlighted frame.
How to achieve video amodal segmentation and content completion?
Please refer to our Technical Report section.
For more details:
arXiv: https://arxiv.org/abs/2412.04623
project webpage: https://diffusion-vas.github.io/