Background
Pressure ulcers affect over 2.5 million people in US hospitals and nursing homes each year. Pressure ulcers occur when pressure is consistent on the same part of the body for a prolonged period of time and the tissue starts to die. The tissue can die at the skin level, through the soft tissue and eventually to the bone. These open wounds are incredibly painful and hard to treat, costing hospital and care facilities over $26.8 billion each year. Luckily the method for preventing them is fairly simple, just moving the patient every few hours. Despite the simplicity of prevention, many in end-of-life care or those unable to move themselves experience pressure ulcers. This is because moving the patient is only effective if the pressure is shifted to new areas, relieving the pressure from the initial position.
Motivation
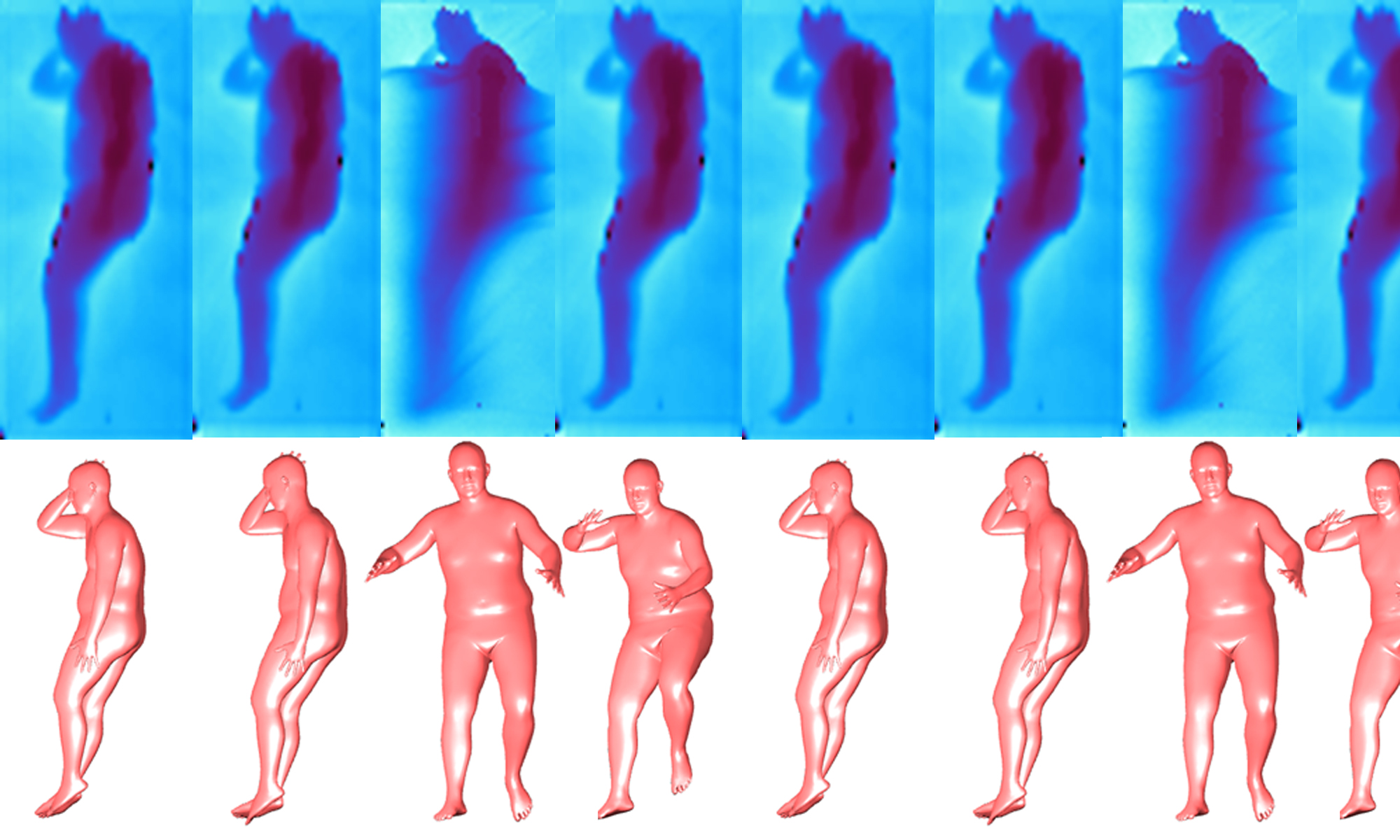
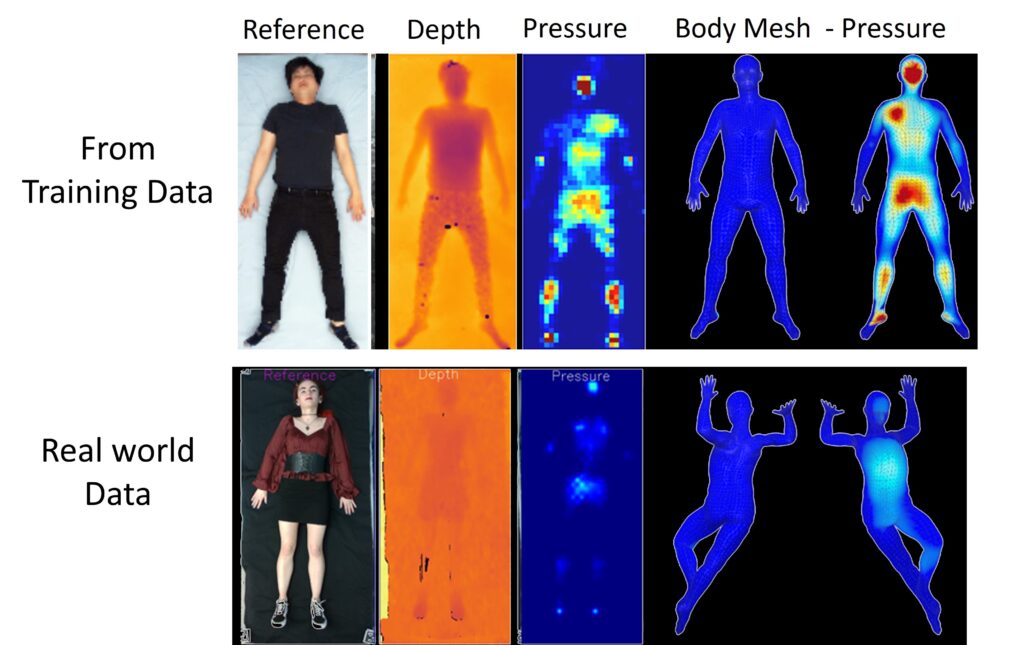
A previous MSCV student, Abishek Tandon, created BodyMap–Jointly Predicting Body Mesh and 3D Applied Pressure Map for People in Bed. Tandon created a model for jointly predicting the 3D pose and pressure of a patient from depth camera and pressure mat data. The output, a combined 3D model and pressure heat map, would allow for caretakers and medical professionals to visualize where the pressure is most concentrated on a patient and move them accordingly. In order to help prevent pressure ulcers, BodyMap needs to be deployed in care settings such as hospitals and nursing homes. As shown in Figure 1 below, BodyMap works great on test data that came from the same set it was trained on. With new real world data BodyMap fails to produce accurate 3D models and pressure heat maps. This occurs because hospital settings are dynamic, and the data taken in the real world does not match the training set distribution. The beds move and elevate, bodies are diverse, and we cannot constrain a hospital setting in the same static way the training data collection environment was. This work focuses on making BodyMap deployable in the real world. Since collecting new real world data for training is expensive and difficult, we need to transform the real world data to better resemble the training data. Allowing us to collect new data in a different environment and still get meaningful results from BodyMap.
Method
We collected nearly 200 sets of RGB, depth, and pressure images, a subset of which are displayed in Figure 2. We need to take this data and transform is some way to get pressure and depth images that better fit the training set distribution, then use the transformed images as input to BodyMap. This process is displayed in Figure 3. We will try several methods to go from the original pressure and depth images to transformed pressure and depth images. Specifically, histogram matching, CycleGAN and Pix2Pix. We also need a way to see how well are doing, we need a way to calculate errors. BodyMap uses posed SMPL models to create the 3D meshes from the depth and pressure inputs. Since BodyMap does not use the corresponding RGB images we can use those to get a pseudo ground truth SMPL models. We use SMPLX, a newer more accurate version of SMPL, to get a posed SMPLX body model from the RGB images. We then convert them to SMPL to be compatible with BodyMap’s output. With a pseudo ground truth we can compute errors between them and the BodyMap output. We specifically are using vertex to vertex error (v2v) and joint error, calculated as shown below. Vertex error is the mean squared error between the positions of corresponding vertices on the meshes, and joint error is the mean squared error between key joint positions of both poses.



Experiments
Histogram Matching
We start off with a simple classical approach to make our real-world data better match BodyMap’s training data, histogram matching. Histogram matching is a classical method to transform the histogram of one image to that of a different (template) image. For each greyscale value r in our input image, we want to map it to the greyscale value, z, that has the same probability in the template image’s probability distribution function (PDF). We want the input image’s PDF, S, to match G, the PDF of the template. So, our goal is as follows in equation 2.


The results from histogram matching are poor as shown in Figure 4. The method is not complex enough to account for the increased detail in the pressure images from BodyMap’s training images. The pressure data from the training set was likely collected on a more expensive pressure mat capable of recording data at a higher resolution, which histogram matching cannot account for. The depth results also suffer from the simplicity of histogram matching not being able to account for the complex transformations required to make the pressure image we took look like the training set.
CycleGAN
Next we tried CycleGAN from Zhu et al. CycleGAN is a type of general adversarial network (GAN) for image-to-image translation, which is exactly what we are trying to do. We train CycleGAN on about 200 real world images as our first class of images and over 4500 images from BodyMap’s training set as the second class. CycleGAN produced poor results, as shown in Figure 5. This is perhaps due to a lack of data or supervision. These results do not resemble BodyMap’s training data and would result in garbage results if inputted to BodyMap.

Pix2Pix
The last method we tried was Pix2Pix from Isola et al. Pix2Pix is also a GAN but is conditional. This means we have to pair our first class of images with those from the second. We need images in our real world set to be paired with images from BodyMap’s training set that have similar poses and body shapes. We first tried to pair data based on our SMPL models from the RGB images and the SMPL data from the training set using the errors from equation 1. The format of the SMPL models in the training set does not seem to be easily compatible with that of our real-world set. This caused incredibly poor pairings. In order to get good data for training we had to pair data manually so we could test Pix2Pix. Ideally, with more time, we would either label more data or determine how to make the ground truth SMPLs from the training set compatible with the ones we generated from RGB images allowing for automatic pairing using equation 1. We were able to label about 25 images for training over the course of several hours. The results from that training are shown in Figure 6. These results are much better than the previous two methods, even with a small dataset. The similarities between the paired images and the fake output are strong and can likely be improved with more training data.

Conclusion
To make BodyMap deployable in care settings we had to accomplish many intermediate tasks. We created a workflow to capture data and run it through BodyMap. WIth that workflow we collected nearly 200 RGB, pressure, and depth images. To allow for error calculation we created a workflow to get “ground truth” SMPL models from our RGB data to compare with BodyMap’s output. We also wrote code that in theory should automatically pair the data we captured with data from BodyMap’s training set. Out of the several methods we tried to perform data transformation Pix2Pix shows the most promise. Even with a small dataset Pix2Pix’s results already remble accurate representations of similar data from BodyMap’s training set. Pix2Pix, or similar methods, seem like a good solution to transform data from a given care setting environment to the match that of BodyMap’s training data. In the future we hope to create a larger paired training set for Pix2Pix, further improving the results and getting accurate and meaningful results from BodyMap.