DiSRT-In-Bed: Diffusion-Based Sim-to-Real Transfer Framework for In-Bed Human Mesh Recovery

Jing Gao
Introduction
In-bed human mesh recovery can be crucial and enabling for several healthcare applications, including sleep pattern monitoring, rehabilitation support, and pressure ulcer prevention. However, it is difficult to collect large real-world visual datasets in this domain, in part due to privacy and expense constraints, which in turn presents significant challenges for training and deploying deep learning models. Existing in-bed human mesh estimation methods often rely heavily on real-world data, limiting their ability to generalize across different in-bed scenarios, such as varying coverings and environmental settings. To address the challenge of limited training data, utilizing synthetic data presents a promising solution. Large-scale simulated depth datasets can be efficiently generated without preserving any personally identifiable information, leading to eliminating the need for sensitive real-world data. Building on this strategy, prior work has demonstrated good performance in the in-bed human mesh recovery task. However, they struggle to effectively bridge the domain gap between synthetic and real-world data, leading to significant performance degradation when the proportion of real-world data in the training set is low, as shown in the following figure.

To address this, we propose a Sim-to-Real Transfer Framework for in-bed human mesh recovery from overhead depth images, which leverages large-scale synthetic data alongside limited or no real-world samples. We introduce a diffusion model that bridges the gap between synthetic data and real data to support generalization in real-world in-bed pose and body inference scenarios.
Method
We utilize the SMPL model, a parametric human body model representing 3D human bodies as a mesh of 6,890 vertices, controlled by pose and shape parameters. Our framework tackles the challenge of in-bed human mesh recovery with minimal real-world data by leveraging synthetic data and limited real-world samples. It consists of three stages: synthetic data generation, model design, and pipeline training and fine-tuning, as illustrated in the following figure.

Synthetic Data Generation
Obtaining labeled data for in-bed healthcare scenarios is challenging, limiting deep learning deployment. Simulation offers a low-cost solution, generating high-quality depth data with ground truth annotations for human mesh in resting positions. Using prior information like bed dimensions and camera-to-bed distance, we simulate realistic environments. Following BodyPressure, a physics-based simulation pipeline, we generate synthetic in-bed human depth data by simulating SMPL-based bodies resting on a soft mattress with a fixed camera. By sampling human shapes, joint angles, and translations, we create diverse data representing various body types and coverings.
Diffusion-Based In-Bed Mesh Recovery
In contrast to the diffusion process used in image generation, which operates directly on images, we conduct forward noise-adding and reverse denoising processes on the SMPL body parameters for in-bed human mesh recovery.
In the forward process, we follow

to obtain noisy versions xt of the initial SMPL body parameters x0 over t timesteps.
In the reverse process, we incorporate depth image c as a conditional input to the diffusion model, modifying the equation as follows:

we diffuse toward the initial sample x0 to ensure consistency throughout the denoising process, as illustrated in the framework. The estimated initial SMLP parameters can be represented as:

The objective of training and fine-tuning the diffusion model D for in-bed human mesh recovery is to minimize:

In the inference, the learned mean can be formulated as:
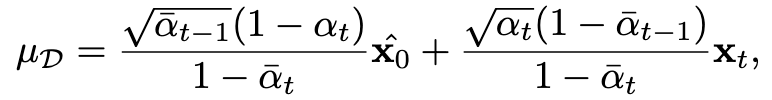
Then, we sample from the transition distribution in each denoising step to compute xt-1 as follows:

Following this reverse process, we iteratively denoise the SMPL latent from noise xT at timestep T down to the target SMPL latent x0 at timestep 0.
Model Architecture
We introduce a network that takes noisy SMPL parameter latent, depth images , and timestep as inputs and outputs the denoised SMPL parameters, as illustrated in the following architecture figure. The depth images condition the reverse diffusion process, while an MLP encoder processes noisy latent, a uniform sampler generates the time embedding. Inspired by the diffusion U-Net design, the network employs residual and attention blocks with adaptive normalization layers initialized to zero. The SMPL latent and time embedding are aligned to enable dynamic adjustments of normalization parameters via a linear MLP. The architecture consists of down-sampling residual blocks, attention blocks, and a regressor that maps output latents to SMPL parameters. The SMPL model then generates the human mesh and 3D joint positions, controlled by gender flags. This design effectively processes conditional information, enabling accurate human mesh recovery.

Training Strategy
- Synthetic Training Stage:
Focuses on building a strong prior using diverse synthetic data, decoupling synthetic and real-world training to address the data imbalance. The diffusion network is trained solely on synthetic depth data with a fixed learning rate to ensure stability and avoid local optima. - Fine-Tuning Stage:
Adapts to the available real-world data using a linearly adjusted learning rate scheduler for faster convergence and improved generalization to real-world scenarios. - Loss Function:
Combines SMPL parameter loss and vertex position loss to optimize the diffusion model.
Experiments
For synthetic dataset, we use BodyPressureSD, which is generated usingthe physical simulation and serves as a benchmark for sim-to-real tasks.
For real-world dataset, we use Simultaneously-collected multimodal Lying Pose (SLP) provides a comprehensive collection of in-bed resting poses across home and hospital settings. For the home setting, data from 102 participants were collected under three occlusion conditions (thin sheet, thicker blanket, no covering). Ground truth SMPL labels ~\cite{clever2022bodypressure} are available for the first 80 participants (10,665 samples) used for training and the remaining 22 participants (2,970 samples) used for evaluation. The hospital setting includes data from 7 participants without SMPL labels, evaluated qualitatively.
We evaluate pose and shape accuracy using 3D mean-per-joint position error (MPJPE) and 3D per-vertex error (PVE), which measure the mean Euclidean distance between inferred and ground truth positions of 24 joints and 6,890 vertices, respectively.


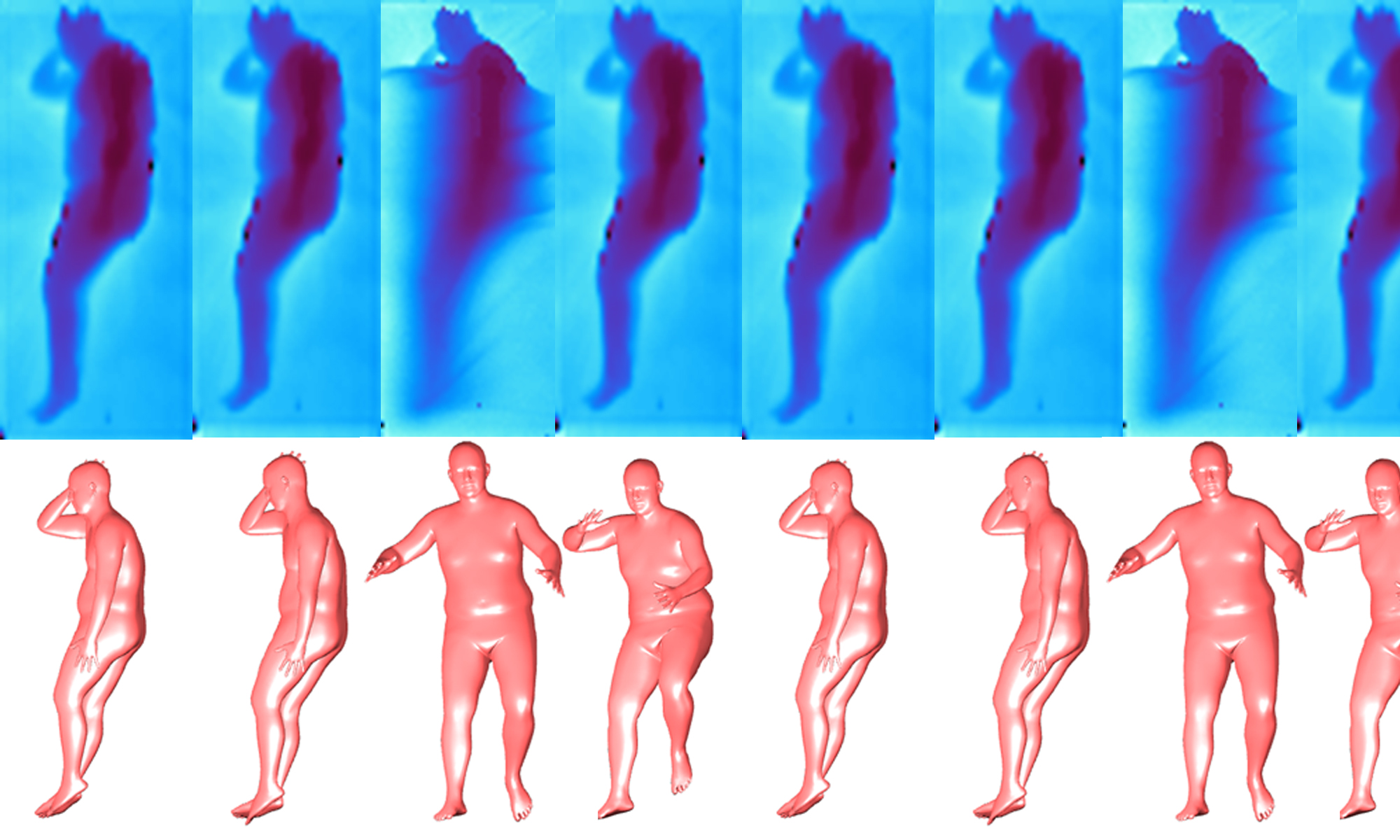
Visualization of Human Mesh Estimated from
limited Real-World Data in Home Settings

Visualization of Human Mesh estimated from the
Real-World Data in Hospital Settings
