
Architecture
Match Anything
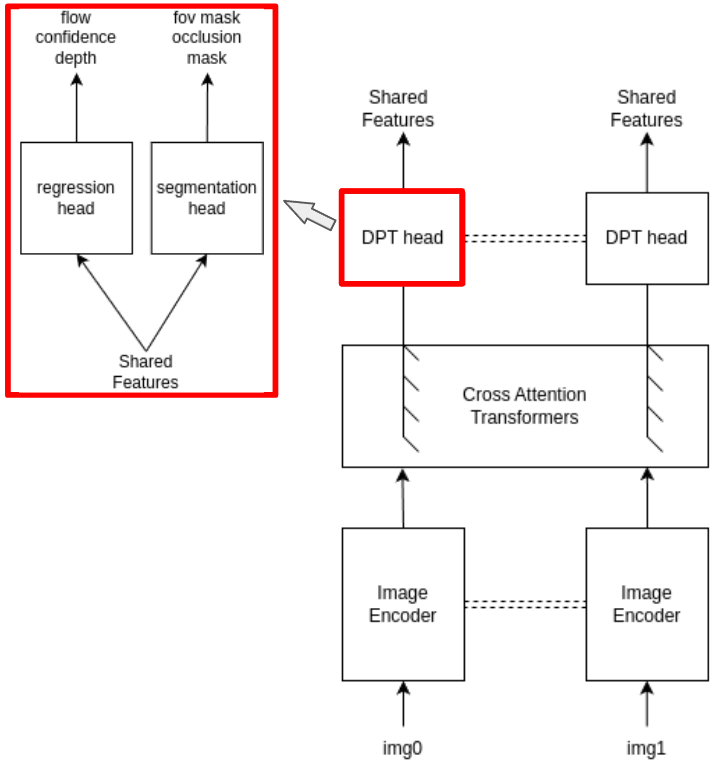
1. Simplify the architecture to be more generalizable
· Include more dataset for training
2. Only predict flow in the co-visible region
· This makes matching a 2D problem, as the network don’t need to reason about occlusions/geometry!
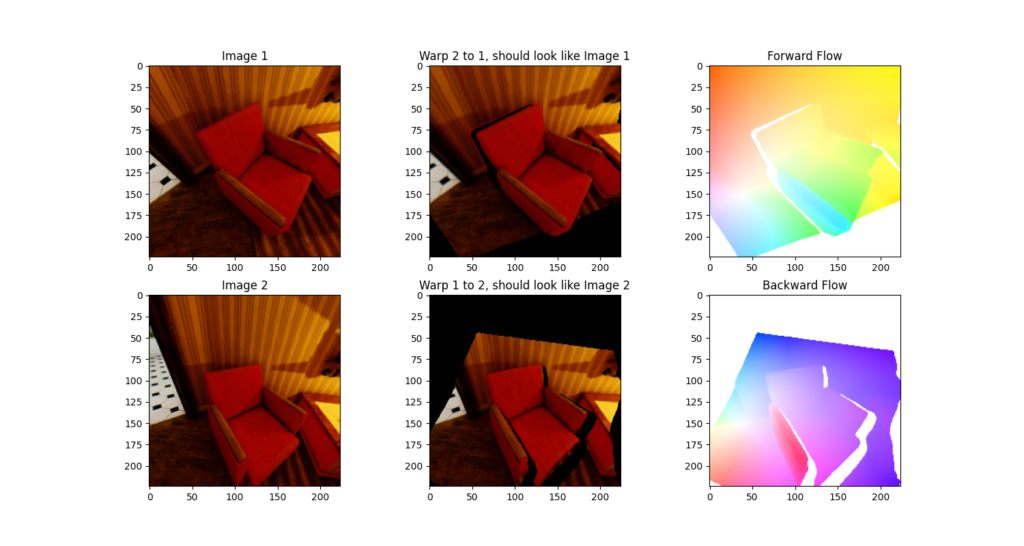
Co-visible Mask Generation
Project pixels from camera 1 into 3D space and then back to camera 2
FoV mask: If the coordinates of projected pixel is within image boundaries, then it’s in FOV
Occlusion mask: If the depth of projected pixel is close to the real depth of that pixel, then it’s visible

Sampling Method
To get image pairs, we need to design a sampling method.
1. Accumulate Pointcloud:
From posed depth image, upproject into point cloud and accumulate.

2. Voxelize:
Voxel down-sample point clouds & camera positions to create enumerable scene representation.

3. Calculate Covisibility:
For all camera position to all voxels, determine if the camera can see the voxel. Save to a list.

4. Generate Samples:
Randomly select a base camera and a target voxel, filter all candidate camera position that can have required angle with the base camera when looking at the target voxel.
Score all candidates based on visibility from the preprocessed covisibility list. Keep N candidates and add to pair list.


Utilizing match anything for reconstruction
To achieve precise mapping and odometry, we build upon state of art method MAC-VO. Essentially we replace the current FlowFormer based frontend with Match Anything. We have started to integrate it and the results look promising.

