We propose a three-stage architecture to create an end-to-end image-to-3D pose model pipeline.

Image-to-2D keypoints
In order to extract 2D keypoints from images in an unsupervised manner, we leverage a modified Stable Keypoints model to overcome its native limitations.

Instead of localizing the diffuse heatmaps to their argmax response location, we extract first-frame 2D keypoints from the image and localize to specific pixel locations. This allows us to force the Stable Diffusion model to attend to regions of our choice, and not arbitrary regions.
Temporal Context
3D-LFM performs single-frame lifting and does not treat sequential data separately. To overcome this limitation, we introduce temporal attention blocks to promote temporal smoothness and avoid jittering or switching of uncertain or occluded keypoints. This attention mechanism add operates across frames of the video in 3D-LFM’s Graph Attention block.

- Local graph attention (GA) layers between keypoints of the same image
- Global Multi-head attention (MHA) between images at different timesteps
2D-to-3D Keypoints
We overcome some limitations exhibited by the 3D-LFM architecture. Concretely,
- In order to create an end-to-end model, 3D-LFM must run on keypoints generated by a 2D detection model. As these keypoints are inherently noisy, 3D-LFM must be robust to input 2D noise. To this end, we re-train 3D-LFM with train-time 2D pose noise augmentations (gaussian, uniform distributions) to handle noise at inference. We are inspired from motionBERT for the way in which they use noise augmentations for training.
- 3D-LFM is prone to heavy distortions of input keypoints due to the usage of OnP (Orthographic-n-Point) projections from 3D to 2D. Instead, we plan to explore the usage of a differentiable PnP (Perspective-n-Point) with intrinsics to allow the model to be sensitive to perspective effects of images (and consequently, their keypoints).
3D-to-mesh reconstruction

We extend the above image-to-3D pipeline to also reconstruct a mesh!
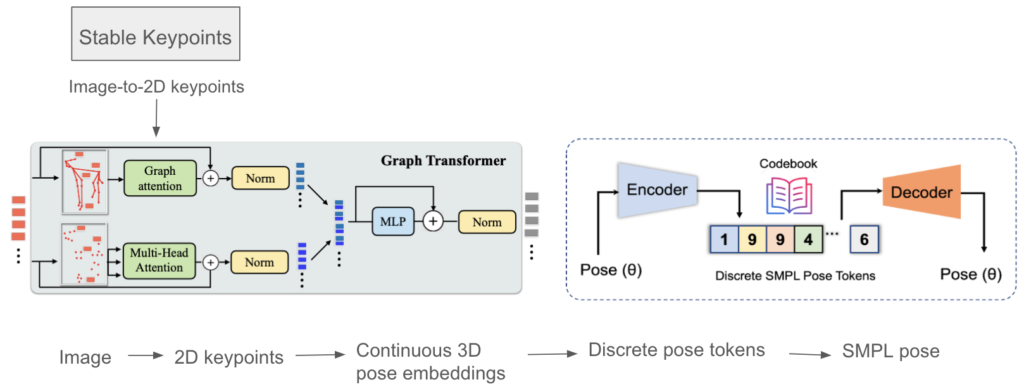
The 2D keypoints extracted using StableKeypoints are lifted into 3D using our 3D-LFM++ model. Instead of using the 3D pose, we input the output embeddings from 3D-LFM++ to the tokenHMR model’s pose head and obtain discrete pose tokens. These discrete pose tokens are converted into continuous SMPL poses using the pre-trained decoder codebook.Currently, we only show the results for humans using the pre-trained decoder. Future works involve training the VQ-VAE tokenizer to also include SMAL poses for animals.