Using Compressed Video Cues for Faster Video Transformers
Sihan Liu, Guanglei Zhu
Robotics Institute, Carnegie Mellon University
In this sample results, the patches framed in blue are retained, while the gray ones represent dropped tokens. As can be seen, with our method given a long video, we can effectively retain dynamic tokens and remove repetitive tokens between frames.
Abstract
We present Run-Length Tokenization (RLT), a simple and efficient approach to speed up video transformers by removing redundant tokens from the input. Existing methods prune tokens progressively, incurring significant overhead and resulting in no speedup during training. Other approaches are content-agnostic: they reduce the number of tokens by a constant factor and thus require tuning for different datasets and videos for optimal performance. Our insight is that we can efficiently identify which patches are redundant before running the model. In contrast, RLT efficiently identifies and removes all tokens that are repeated over time before running the model, replacing them with a single token and a positional encoding to represent its new length. This approach is both content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead. RLT can increase the throughput of pre-trained transformers without any additional training, increasing throughput by 40% with only 0.1% drop in accuracy on action recognition. It also results in a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by more than 40% while matching the baseline model performance. These benefits extend to video-language tasks, with RLT matching baseline performance on Epic Kitchens-100 multi-instance retrieval while reducing training time and throughput by 30%.
Problem Statement
How to speed up video transformer models for diverse video understanding tasks, while maintaining performance?

Related works
(1) Compressed Video Action Recognition
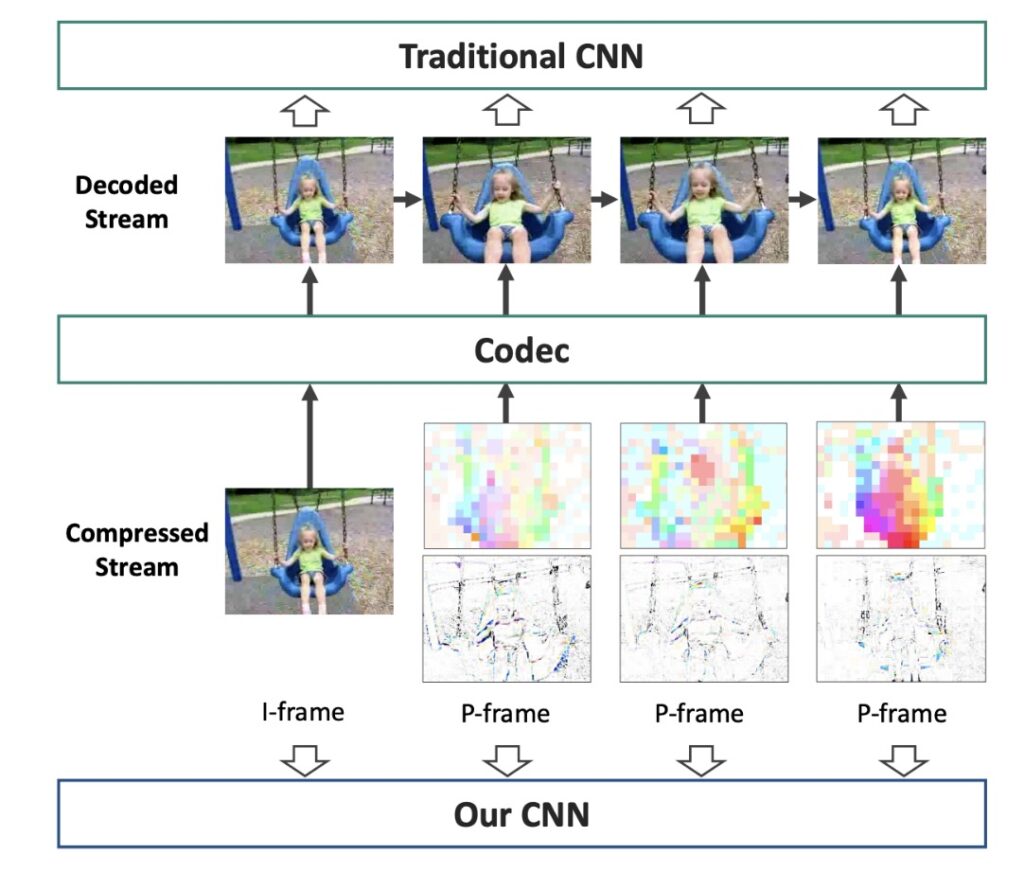
Motivation: Raw video compression data contains strong signal that can be leveraged for model training
Contribution: CoViAR train directly on compressed videos by leveraging motion vectors and residuals from compression algorithms
Methods: (1) Learn representation from compressed data; (2) Model processes I-frames and P-frames directly; (3) Faster by using less computation on P-frames.
(2) Scaling Language-Image Pre-training via Masking

Motivation: Due to the complex nature of vision plus language, large-scale training is essential for the capability of language-supervised models, e.g. CLIP.
Contribution: FLIP is a simple method for efficient CLIP training via masking.
Method: Randomly masking out image patches with a high masking ratio.
(3) Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ration and Resolution

Motivation: Current vision models typically require resizing images to a fixed resolution, which can result in loss of information or inefficient training.
Contribution: NaViT(a Vision Transformer for any Aspect Ratio and Resolution) processes images with varying resolutions and aspect ratios by packing multiple patches from different images into a single sequence.
Method: (1) Data Preprocessing. Patchify Images, followed by selective dropping of some patches to create a diverse training sequence
Patched Sequence: These patches are assembled into a packed sequence that combines patches from different images, accommodating for varied sizes and aspect ratios (2) Masked Self-Attention. Self-Attention is applied only to patches from the same image, ignoring the padding tokens. (3) Masked Pooling. Apply pooling to the sequence, with padding tokens excluded from the pooling process to prevent them from affecting the learned representations
Our method
Step 1: Find and remove all static tokens across consecutiveframes in a video.
(1) Each frame is partitioned into 16 x 16 patches
(2) Compare patches in the same position betweentwo frames
(3) If the residual between patches is below somethresholds, we remove them

Step 2: Feed selected tokens into Video Transformers.

Experiments
We present some sample video results of Run-Length Tokenization (RLT) on a variety of video question answering benchmarks. Click the thumbnails to play the videos.
Quantitive results
Numerical results on Epic Kitchen datasets with Multi-Instance Retrieval task. Our method can achieve up to 25% speed up with minimal performance drop, comparing to random drop and maintaining the comparable performance.

Qualitative results
Sample results from the Kinetics dataset.
Sample results from the Something-Something dataset.
Sample results from the UCF101 dataset.
Authors:
Guanglei Zhu

I am currently pursuing a Master’s in Computer Vision at Carnegie Mellon University, driven by a passion for solving real-world problems using Machine Learning and Computer Vision. Previously, I interned at the Vector Institute under the guidance of Prof. Animesh Garg. I hold a Bachelor’s degree in Computer Science from the University of Toronto. In my MSCV project, I am responsible for designing and conducting experiments on various dataset.
Sihan Liu

I am Sihan and currently a MSCV student at Carnegie Mellon University. My latest active research area is generative ai and 3D reconstruction than can 1) be generalizable; 2) be robust to and sparse views; 5) work on scene-level. I completed my undergrad study from Boston University. In this project, I am responsible for running and benchmarking classification experiments on many datasets using our method.
Presentations
https://docs.google.com/presentation/d/1N9EIBaRt2oeVkhS7uxWSy3l03Zv9bZpOYb_1skhOfCs/edit?usp=sharing