
Approach for 3D Face Fitting

We take one frame at a time and run a 2D Landmark Regression model on it. This gives us the 2D landmarks over the face. This process operates at around 90 FPS. After that the detected 2D landmarks are lifted to 3D using the landmark-vertex correspondence of the FLAME model. This forms a coarse and slightly random initialization of a mesh in 3D.
After this a two-step optimization is performed using L-BFGS
- Rigid Optimisation : Under this type of optimization, the values such as the rotation, translation, and scale are optimized
- Non-Rigid Optimisation : Under this optimization the Shape, Pose and Expressions are optimized along with the rigid parameters
Results for 3D Face Fitting

In the above figure we can see that our approach is able to aptly model the 3D Mesh on the face. And in the rightmost pic it can be see that the method is robust to some degree of occlusion.
End to End Latency of the different implementations of our algorithm are as follows
Pytorch Implementation – 58 ms
JAX Implementation – 22 ms
An example as a video is also presented below.
Biases in 3DMMs
- 3D Fitting results are biased towards ethnicities in training scans
- Popular 3D morphable models are opaque on the attribute distribution in the training set

Example fitting using FaceVerse 3DMM
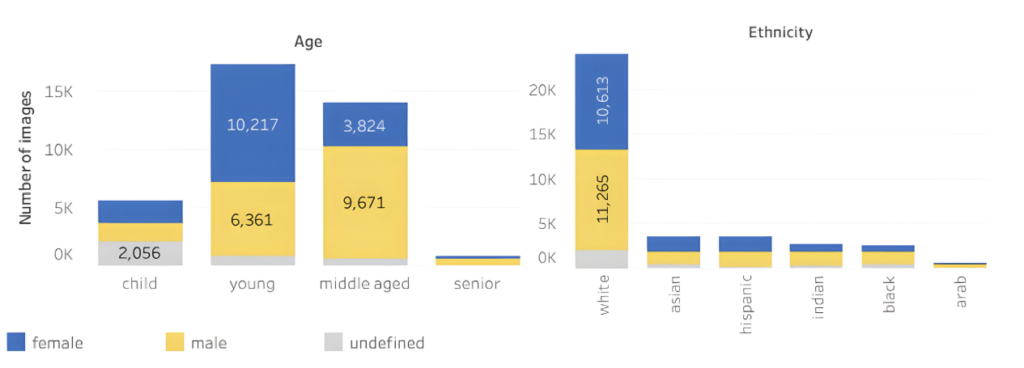
Disparity across gender, age, and ethnicity in a large 3D heads dataset
Bias-free attribute classifiers need to be used as a diagnostic tool to evaluate the fairness of the 3DMM training data. Assess whether the 3DMM model encodes attributes (e.g.gender, age, ethnicity) uniformly
How to set a target for de-biasing?
Defining what we mean by a de-biased distribution can be open to interpretation. Defining the de-biased target is harder when multiple attributes are at play. We propose to create a small golden dataset that has the desired data distribution.
The golden dataset is small enough to be curated manually and inspected visually, and so it should ideally be created manually. However, we propose a semi-automatic method for creating the golden dataset based on a biased dataset and then modifying it based on a set of attributes. That approach though not ideal, is shown below.

Approach for attribute classifier debiasing
Step 1 :
Generate samples closer to golden data distribution.

Step 2 :
Finetune the biased classifier with generated samples

Step 1 and Step 2 are repeated iteratively
The Debiasing goal is based on the accuracy on the Test set
Result for current work
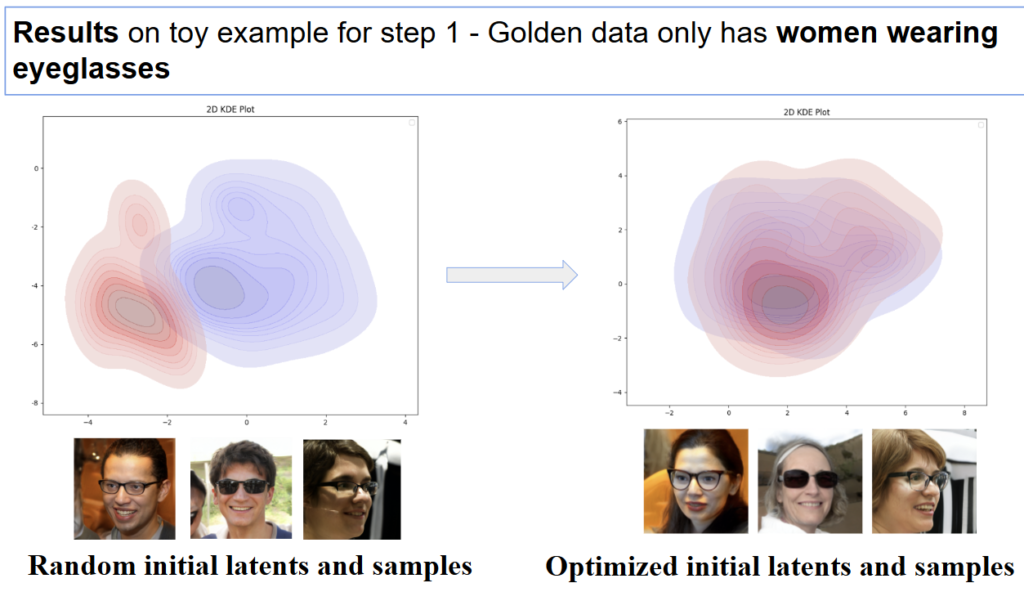
The distribution in blue represents the KDE plot for the golden data. It is obtained by projecting the feature distribution of the golden data images in 2D. The red distribution is the corresponding one for the generated samples. We start from random images from random latents that has some random overlap with the golden data distribution. As the training progresses, the random images are modified through their latents to move towards the target golden data distribution, which can be used for fine-tuning the biased classifier in Step 2
Future Work
- Design metrics and methodology for comparing different 3DMM models using an analysis by synthesis algorithm based on photometric loss
- Use Active learning techniques to generate a minimal set of images

References
- Tianye Li, Timo Bolkart, Michael J. Black, Hao Li, and Javier Romero. 2017. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. 36, 6,
- Wang, Lizhen et al. “FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022): 20301-20310.
- Martyniuk, T. et al. “DAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022): 20910-20920.
- Wang, Yinong & Li, Eileen & Luo, Jinqi & Wang, Zhaoning & Torre, Fernando. (2024). Unsupervised Model Diagnosis. 10.48550/arXiv.2410.06243.